Spark应用 —— 快速构建用户推荐系统
来源:互联网 发布:终结者软件 编辑:程序博客网 时间:2024/05/15 08:54
大数据一个重要的应用是预测用户喜好,例如相关广告的推送、相关产品的推荐、相关图书电影的推荐等。这里我们使用Spark的机器学习来展示如何进行预测,并基于此快速构建一个电影评分及推荐应用。
找到文件
import os from databricks_test_helper import Test dbfs_dir = '...' ratings_filename = dbfs_dir + '/ratings.csv' movies_filename = dbfs_dir + '/movies.csv' if os.path.sep != '/': ratings_filename = ratings_filename.replace('/', os.path.sep) movie_filename = movie_filename.replace('/', os.path.sep)定义数据架构
from pyspark.sql.types import * ratings_df_schema = StructType( [StructField('userId', IntegerType()), StructField('movieId', IntegerType()), StructField('rating', DoubleType())] ) movies_df_schema = StructType( [StructField('ID', IntegerType()), StructField('title', StringType())] ) 载入数据并缓存
from pyspark.sql.functions import regexp_extract from pyspark.sql.types import * raw_ratings_df = sqlContext.read.format('com.databricks.spark.csv').options(header=True, inferSchema=False).schema(ratings_df_schema).load(ratings_filename) ratings_df = raw_ratings_df.drop('Timestamp') raw_movies_df = sqlContext.read.format('com.databricks.spark.csv').options(header=True, inferSchema=False).schema(movies_df_schema).load(movies_filename) movies_df = raw_movies_df.drop('Genres').withColumnRenamed('movieId', 'ID') ratings_df.cache() movies_df.cache() assert ratings_df.is_cached assert movies_df.is_cached raw_ratings_count = raw_ratings_df.count() ratings_count = ratings_df.count() raw_movies_count = raw_movies_df.count() movies_count = movies_df.count() print 'There are %s ratings and %s movies in the datasets' % (ratings_count, movies_count) print 'Ratings:' ratings_df.show(3) print 'Movies:' movies_df.show(3, truncate=False) assert raw_ratings_count == ratings_count assert raw_movies_count == movies_count快速浏览一下数据结构
display(movies_df)
平均分最高的电影
from pyspark.sql import functions as F movie_ids_with_avg_ratings_df = ratings_df.groupBy('movieId').agg(F.count(ratings_df.rating).alias("count"), F.avg(ratings_df.rating).alias("average")) print 'movie_ids_with_avg_ratings_df:' movie_ids_with_avg_ratings_df.show(3, truncate=False) movie_names_df = movie_ids_with_avg_ratings_df.join(movies_df, movie_ids_with_avg_ratings_df.movieId == movies_df.ID) movie_names_with_avg_ratings_df = movie_names_df.select('average', 'title', 'count', 'movieId') print 'movie_names_with_avg_ratings_df:' movie_names_with_avg_ratings_df.show(3, truncate=False) 结果类似于
movie_ids_with_avg_ratings_df:+-------+-----+------------------+|movieId|count|average |+-------+-----+------------------+|1831 |7463 |2.5785207021305103||431 |8946 |3.695059244355019 ||631 |2193 |2.7273141814865483|+-------+-----+------------------+only showing top 3 rowsmovie_names_with_avg_ratings_df:+-------+-----------------------------+-----+-------+|average|title |count|movieId|+-------+-----------------------------+-----+-------+|5.0 |Ella Lola, a la Trilby (1898)|1 |94431 ||5.0 |Serving Life (2011) |1 |129034 ||5.0 |Diplomatic Immunity (2009? ) |1 |107434 |+-------+-----------------------------+-----+-------+only showing top 3 rows有500条以上评价平均分最高的电影
movies_with_500_ratings_or_more = movie_names_with_avg_ratings_df.filter('count>=500') print 'Movies with highest ratings:' movies_with_500_ratings_or_more.show(20, truncate=False) 协作过滤
协作过滤是一种利用用户整体(协作)偏好信息来进行自动预测的方法。它基于这样的假设,如果用户A和用户B在某个问题上意见一致,那么A与B在另一问题X上更有可能意见一致。
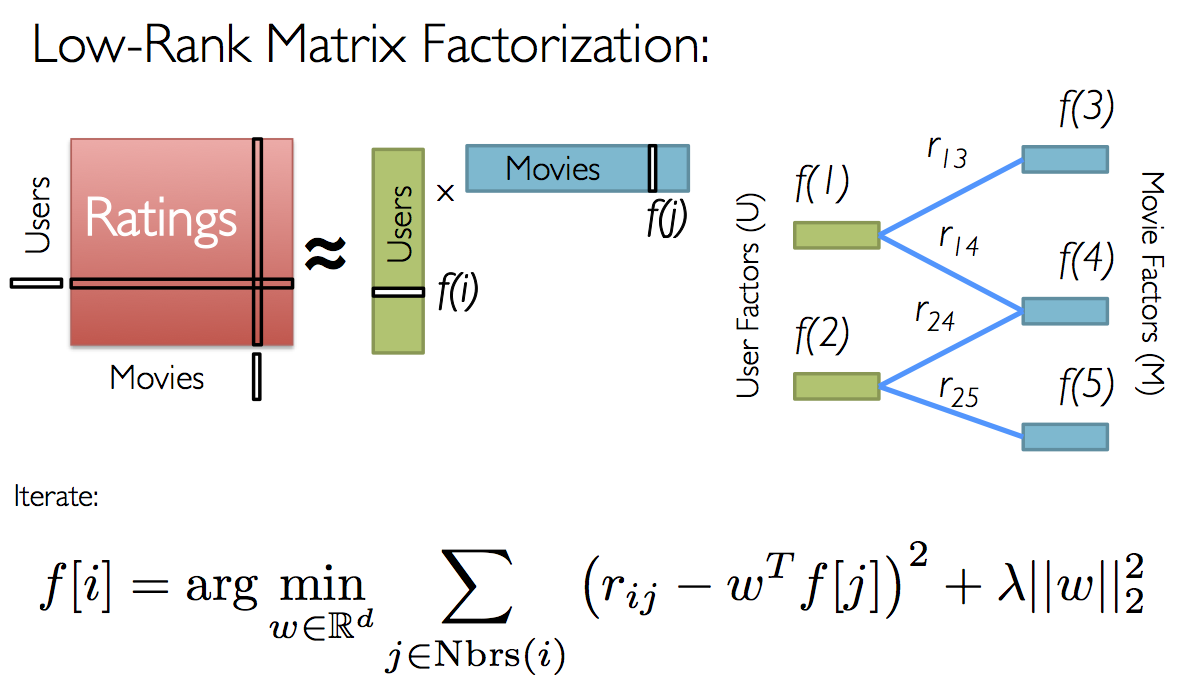
首先我们将评价数据分割成训练集、验证集和测试集
seed = 43 (split_60_df, split_a_20_df, split_b_20_df) = ratings_df.randomSplit([0.6, 0.2, 0.2], seed) training_df = split_60_df.cache() validation_df = split_a_20_df.cache() test_df = split_b_20_df.cache() print('Training: {0}, validation: {1}, test: {2}\n'.format( training_df.count(), validation_df.count(), test_df.count()) ) training_df.show(3) validation_df.show(3) test_df.show(3) 使用ALS函数并设置参数
from pyspark.ml.recommendation import ALS als = ALS() als.setMaxIter(5)\ .setSeed(seed)\ .setRegParam(0.1)\ .setUserCol('userId')\ .setItemCol('movieId')\ .setRatingCol('rating') from pyspark.ml.evaluation import RegressionEvaluator reg_eval = RegressionEvaluator(predictionCol="prediction", labelCol="rating", metricName="rmse") tolerance = 0.03 ranks = [4, 8, 12] errors = [0, 0, 0] models = [0, 0, 0] err = 0 min_error = float('inf') best_rank = -1 for rank in ranks: als.setRank(rank) model = als.fit(training_df) predict_df = model.transform(validation_df) predicted_ratings_df = predict_df.filter(predict_df.prediction != float('nan')) error = reg_eval.evaluate(predicted_ratings_df) errors[err] = error models[err] = model print 'For rank %s the RMSE is %s' % (rank, error) if error < min_error: min_error = error best_rank = err err += 1 als.setRank(ranks[best_rank]) print 'The best model was trained with rank %s' % ranks[best_rank] my_model = models[best_rank] 测试模型
predict_df = my_model.transform(test_df) predicted_test_df = predict_df.filter(predict_df.prediction != float('nan')) test_RMSE = reg_eval.evaluate(predicted_test_df) print('The model had a RMSE on the test set of {0}'.format(test_RMSE)) 比较模型
from pyspark.sql.functions import lit avg_rating_df = training_df.groupBy().avg('rating') training_avg_rating = avg_rating_df.collect()[0][0] print('The average rating for movies in the training set is {0}'.format(training_avg_rating)) test_for_avg_df = training_df.withColumn('prediction', lit(training_avg_rating)) test_avg_RMSE = reg_eval.evaluate(test_for_avg_df) print("The RMSE on the average set is {0}".format(test_avg_RMSE)) 进行新的预测
评价你的电影
from pyspark.sql import Row my_user_id = 0 my_rated_movies = [ (my_user_id, 318, 4), (my_user_id, 858, 4), (my_user_id, 527, 4), (my_user_id, 1221, 4), (my_user_id, 260, 4), (my_user_id, 1196, 4), (my_user_id, 2571, 5), (my_user_id, 94466, 5), (my_user_id, 593, 4), (my_user_id, 1197, 4) ] my_ratings_df = sqlContext.createDataFrame(my_rated_movies, ['userId','movieId','rating']) print 'My movie ratings:' display(my_ratings_df.limit(10))
将你的电影评价加入训练集
training_with_my_ratings_df = training_df.unionAll(my_ratings_df) print ('The training dataset now has %s more entries than the original training dataset' % (training_with_my_ratings_df.count() - training_df.count())) assert (training_with_my_ratings_df.count() - training_df.count()) == my_ratings_df.count() 使用模型进行训练
als.setPredictionCol("prediction")\ .setMaxIter(5)\ .setSeed(seed)\ .setRegParam(0.1)\ .setUserCol('userId')\ .setItemCol('movieId')\ .setRatingCol('rating') my_ratings_model = als.fit(training_with_my_ratings_df) 检查新模型的RMSE
my_predict_df = my_ratings_model.transform(test_df) predicted_test_my_ratings_df = my_predict_df.filter(my_predict_df.prediction != float('nan')) test_RMSE_my_ratings = reg_eval.evaluate(predicted_test_my_ratings_df) print('The model had a RMSE on the test set of {0}'.format(test_RMSE_my_ratings)) 预测你对新电影的评分
my_rated_movie_ids = [x[1] for x in my_rated_movies] not_rated_df = movies_df.filter(~ movies_df['ID'].isin(my_rated_movie_ids)) my_unrated_movies_df = not_rated_df.withColumnRenamed('ID', 'movieId').withColumn('userId', lit(my_user_id)) raw_predicted_ratings_df = my_ratings_model.transform(my_unrated_movies_df) predicted_ratings_df = raw_predicted_ratings_df.filter(raw_predicted_ratings_df['prediction'] != float('nan')) 输出评价最高的产品
predicted_with_counts_df = predicted_ratings_df.join(movie_names_with_avg_ratings_df, 'movieId') predicted_highest_rated_movies_df = predicted_with_counts_df.orderBy('prediction', ascending=False).filter('count>75') print ('My 25 highest rated movies as predicted (for movies with more than 75 reviews):') predicted_highest_rated_movies_df.show(25) 阅读全文
0 0
- Spark应用 —— 快速构建用户推荐系统
- Spark构建推荐系统引擎--来源于Spark机器学习
- Hadoop/Spark推荐系统(四)——推荐链接
- Spark Mllib构建简单的电影推荐系统(转)
- Hadoop—Spark企业应用实战(推荐版)视频教程
- Hadoop/Spark推荐系统(一)——共同好友
- spark机器学习笔记:(三)用Spark Python构建推荐系统
- 基于Spark构建推荐引擎
- Spark-构建基于Spark的推荐引擎
- Spark-电影推荐系统
- Mahout推荐系统构建
- idea快速构建spark 工程
- Spark学习笔记-推荐系统(协同过滤算法为用户推荐播放歌手)
- 推荐系统:寻找相近用户——欧几里德距离评价
- 推荐系统初探之一 —— 寻找相似的用户
- 推荐系统——利用用户标签数据
- 推荐系统那点事 —— 什么是用户画像?
- 【投稿】Machine Learning With Spark Note 2:构建简单的推荐系统
- PCA
- String、StringBuffer与StringBuilder之间区别
- 使用tensorflow导入已经下载好的mnist数据集
- Android Activity去除标题栏和状态栏
- Ubuntu14.04 + GTX1070 + Cuda8.0 + TensorFlow安装配置
- Spark应用 —— 快速构建用户推荐系统
- IBM中国编译器团队电面总结
- EJB学习笔记_9_拦截器
- 全球钓鱼网站数量激增,交易、金融证券等行业成“重灾区”
- android Intent 原理及分析
- JavaScript中原型学习基本理解(原型链)三
- 2017,最受欢迎的 15 大 Python 库有哪些?
- 第1章 PHP概述
- ImageLoader源码解析-----ImageLoader的结构


