第二篇. 操作系统之 进程与线程
来源:互联网 发布:网络语芭比是什么意思 编辑:程序博客网 时间:2024/05/22 12:33
五.多进程图像的引出
L8: CPU管理的直观想法
不仅要切换PC指针,还需要对应的寄存器环境
L9: 多进程图像
六、 线程引出与实现
L10:用户级线程
10.1 需要两个栈用于线程切换
几个线程就需要几个栈
10.2 用户主动切换
只在调用Yield处进行切换
yield, thread_create都是自己写的,linux 0.11源码中没有
10.3 进程和线程概念区分
进程 和 线程 都是动态概念
进程 = 资源 (包括寄存器值,PCB,内存映射表)+ 指令序列
线程 = 指令序列
线程 的资源是共享的,
进程 间的资源是分隔独立的,内存映射表不同,占用物理内存地址是分隔的
线程 的切换只是切换PC,切换了指令序列
进程 的切换不仅要切换PC,还包括切换资源,即切换内存映射表
用户级线程:调用Yield函数,自己主动让出cpu,内核看不见,内核只能看见所属进程而看不见用户级线程,所以一个用户级线程需要等待,内核会切到别的进程上,不会切到该进程下的其他用户级线程!!!
内核级线程: 内核能看见内核级线程,一个线程需要等待,内核会切到所属进程下的其他内核级线程。
L11:内核级线程
11.1 基本概念
只有内核级线程才能发挥多核性能,多个CPU共用一套MMU设备情况下,可以一个CPU执行一个内核级线程,在内核级线程切换的时候,不需要切换内存映射关系,代价小很多,因为本来一个进程中MMU映射关系就是一样的
进程 无法发挥多核性能,因为只有一套MMU,进程切换时MMU映射关系也得跟着切换,即切换内存映射表,切换内存映射表代价比较大
一个内核级线程的切换需要两套栈: 用户栈 + 内核栈
注意
linux 0.11中本身不支持内核级线程切换,只有进程切换,但实际上只是多了切换内存映射表那部分。
11.2 完整的系统调用中断过程:
1) INT中断自动压栈的有下一条指令,以及用户级线程SS:SP,就是下图五个参数 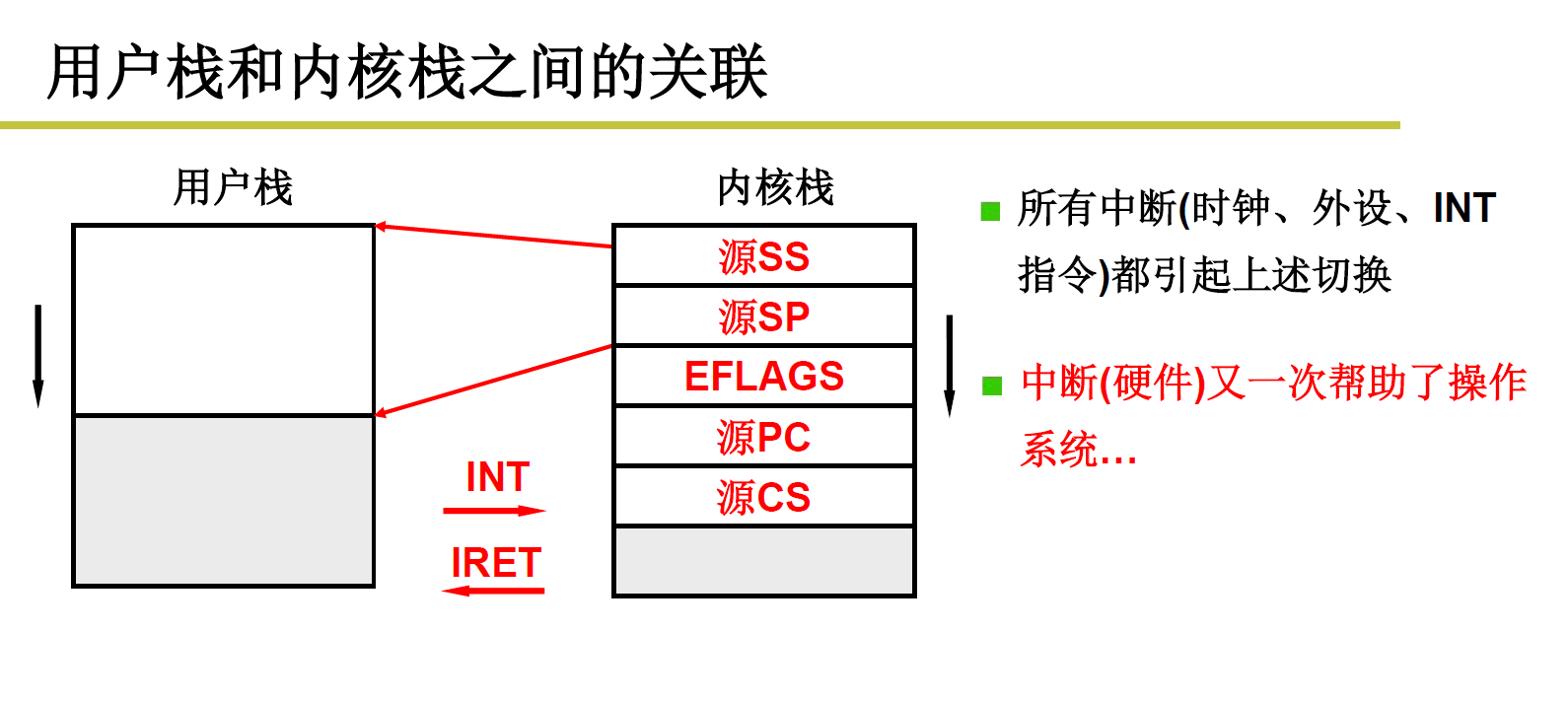
2) _system_call 把寄存器保护压栈是压到内核栈中,需要手动压栈
3) 系统调用,(有可能是_sys_fork,其实就是根据标号找到的系统调用),结束之后继续执行,要执行reschedule,先push $ret_from_sys_call,让其在_schedule之后返回到ret_from_sys_call, _schedule为c函数,结束右括号会把ret_from_sys_call pop出来,返回到这里执行,即执行ret_from_sys_call;
这里注意call 和 jmp的区别!!!
4)在ret_from_sys_call中pop出_system_call时保护的寄存器内容,然后中断返回!!!
5)中断返回是在最后,中断返回会把SS:SP 以及用户态的下一条指令 POP出来,即把5个寄存器pop出来!!!这样就会返回到用户栈,运行用户态的下一条指令!!!
代码:
reschedule: pushl $ret_from_sys_call jmp _schedule //如果用call就是先将下一条指令压栈,然后jmp,这样只能顺序往下走,但是用push+jmp则可以改变跳转地址!!!11.3 switch_to五段论

这里要注意,中断出口这里已经经过了前面的switch_to,中断的iret已经不是原先的中断返回了,是切换后的新中断的执行返回!!!这样返回以后就来到了引发该新中断的用户态代码来执行
L12 核心级线程实现实例
12.1 fork函数经典调用
if (!fork()) //关键在于 INT 80 后面的指令 mov res, %eax;父进程和子进程都会执行这个代码,但是%eax的值不一样{ 子进程}else{ 父进程}fork新建了内核栈,但没有新建用户栈,即子进程和父进程共用了用户栈,这样不会出现问题么???
//Main.cstatic inline _syscall0(int,fork) //宏定义#define _syscall0(type,name) \type name(void) \{ \long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_##name)); \if (__res >= 0) \ return (type) __res; \errno = -__res; \return -1; \}//宏展开int fork(){long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_fork)); \if (__res >= 0) \ return (type) __res; \errno = -__res; \return -1; \}12.2 sys_fork解析
sys_fork: call find_empty_process testl %eax,%eax js 1f push %gs pushl %esi pushl %edi pushl %ebp pushl %eax call copy_process addl $20,%esp1: ret12.3 find_empty_process
find_empty_process返回非0值,要么为正整数,要么为负数,并且将返回值保存到寄存器eax中,即父进程的eax值为非0
int find_empty_process(void){ int i; repeat: if ((++last_pid)<0) last_pid=1; for(i=0 ; i<NR_TASKS ; i++) if (task[i] && task[i]->pid == last_pid) goto repeat; for(i=1 ; i<NR_TASKS ; i++) if (!task[i]) return i; return -EAGAIN;}12.4 copy_process
12.4.1 创建内核栈和用户栈
调用系统调用get_free_page在内核段申请到一页空间,强制转换为PCB指针
也即图中下端低地址处黄色区域所示,PCB数据结构保存
上端高地址处,用作内核栈的栈顶,压栈则往低地址处靠近
用户栈还是和父进程共用同一个栈
即 新建了内核栈,用户栈和父进程共用
12.4.2 eax
copy_process中,有很重要的一句
p->tss.eax = 0;
到时候switch_to的时候,会把tss表中的寄存器值都恢复到cpu寄存器中,
也即子进程eax寄存器的值为0
/* * Ok, this is the main fork-routine. It copies the system process * information (task[nr]) and sets up the necessary registers. It * also copies the data segment in it's entirety. */int copy_process(int nr,long ebp,long edi,long esi,long gs,long none, long ebx,long ecx,long edx, long fs,long es,long ds, long eip,long cs,long eflags,long esp,long ss){ struct task_struct *p; int i; struct file *f; p = (struct task_struct *) get_free_page(); if (!p) return -EAGAIN; task[nr] = p; *p = *current; /* NOTE! this doesn't copy the supervisor stack */ p->state = TASK_UNINTERRUPTIBLE; p->pid = last_pid; p->father = current->pid; p->counter = p->priority; p->signal = 0; p->alarm = 0; p->leader = 0; /* process leadership doesn't inherit */ p->utime = p->stime = 0; p->cutime = p->cstime = 0; p->start_time = jiffies; p->tss.back_link = 0; p->tss.esp0 = PAGE_SIZE + (long) p; p->tss.ss0 = 0x10; p->tss.eip = eip; p->tss.eflags = eflags; p->tss.eax = 0; p->tss.ecx = ecx; p->tss.edx = edx; p->tss.ebx = ebx; p->tss.esp = esp; p->tss.ebp = ebp; p->tss.esi = esi; p->tss.edi = edi; p->tss.es = es & 0xffff; p->tss.cs = cs & 0xffff; p->tss.ss = ss & 0xffff; p->tss.ds = ds & 0xffff; p->tss.fs = fs & 0xffff; p->tss.gs = gs & 0xffff; p->tss.ldt = _LDT(nr); p->tss.trace_bitmap = 0x80000000; if (last_task_used_math == current) __asm__("clts ; fnsave %0"::"m" (p->tss.i387)); if (copy_mem(nr,p)) { task[nr] = NULL; free_page((long) p); return -EAGAIN; } for (i=0; i<NR_OPEN;i++) if ((f=p->filp[i])) f->f_count++; if (current->pwd) current->pwd->i_count++; if (current->root) current->root->i_count++; if (current->executable) current->executable->i_count++; set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss)); set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt)); p->state = TASK_RUNNING; /* do this last, just in case */ return last_pid;}小结: fork之后,eax中为0的为子进程,eax非0的为父进程
12.5 exec(cmd)
fork一个子进程,就是一个叉子
1) 一开始的状态和父进程完全一样,相当于建了一个进程壳子,然后填的父进程的程序内容,直到fork返回
2) 根据fork的返回值,进入子进程分支。在子进程分支中,执行子进程的内容,即把子进程的函数填进来。
if (!fork()) exec(cmd); //exec为系统调用exec也即execve系统调用 将程序装到新建的进程壳子中
具体就是先调用execve,触发软终端,调用系统调用_sys_execve,再调用c函数_do_execve,在_do_execve中将内核栈做成新进程的样子,主要是
1)改动内核栈中返回地址的内容即图中ret内容,将返回地址置为要调用的程序入口
2)改动内核栈中用户栈地址内容即图中SS:SP内容,将用户栈地址置为新分配的用户栈空间
这样在iret返回的时候,会返回到新程序入口去执行,并且跳转到对应的新分配的用户栈,这样就将新的程序,新的用户栈,新的程序地址和新的PCB关联起来了,以后保存到tss也是新的用户栈了,新的内核栈在fork中就已经保存到对应的tss中了
其中最重要的两句代码
p = create_table; //为新进程分配用户栈空间eip[3] = p; //将新的用户栈空间放到SS:SP处_syscall3(int,execve,const char *,file,char **,argv,char **,envp)//宏展开,得到execve函数的定义int execve(const char* file, char ** argv, char ** envp){long __res; \__asm__ volatile ("int $0x80" \ : "=a" (__res) \ : "0" (__NR_execve),"b" ((long)(a)),"c" ((long)(b)),"d" ((long)(c))); \if (__res>=0) \ return (type) __res; \errno=-__res; \return -1; \}_sys_execve: lea EIP(%esp), %eax pushl %eax call _do_execve/* * 'do_execve()' executes a new program. */int do_execve(unsigned long * eip,long tmp,char * filename, char ** argv, char ** envp){ struct m_inode * inode; struct buffer_head * bh; struct exec ex; unsigned long page[MAX_ARG_PAGES]; int i,argc,envc; int e_uid, e_gid; int retval; int sh_bang = 0; unsigned long p=PAGE_SIZE*MAX_ARG_PAGES-4; if ((0xffff & eip[1]) != 0x000f) panic("execve called from supervisor mode"); for (i=0 ; i<MAX_ARG_PAGES ; i++) /* clear page-table */ page[i]=0; if (!(inode=namei(filename))) /* get executables inode */ return -ENOENT; argc = count(argv); envc = count(envp);restart_interp: if (!S_ISREG(inode->i_mode)) { /* must be regular file */ retval = -EACCES; goto exec_error2; } i = inode->i_mode; e_uid = (i & S_ISUID) ? inode->i_uid : current->euid; e_gid = (i & S_ISGID) ? inode->i_gid : current->egid; if (current->euid == inode->i_uid) i >>= 6; else if (current->egid == inode->i_gid) i >>= 3; if (!(i & 1) && !((inode->i_mode & 0111) && suser())) { retval = -ENOEXEC; goto exec_error2; } if (!(bh = bread(inode->i_dev,inode->i_zone[0]))) { retval = -EACCES; goto exec_error2; } ex = *((struct exec *) bh->b_data); /* read exec-header */ if ((bh->b_data[0] == '#') && (bh->b_data[1] == '!') && (!sh_bang)) { /* * This section does the #! interpretation. * Sorta complicated, but hopefully it will work. -TYT */ char buf[1023], *cp, *interp, *i_name, *i_arg; unsigned long old_fs; strncpy(buf, bh->b_data+2, 1022); brelse(bh); iput(inode); buf[1022] = '\0'; if ((cp = strchr(buf, '\n'))) { *cp = '\0'; for (cp = buf; (*cp == ' ') || (*cp == '\t'); cp++); } if (!cp || *cp == '\0') { retval = -ENOEXEC; /* No interpreter name found */ goto exec_error1; } interp = i_name = cp; i_arg = 0; for ( ; *cp && (*cp != ' ') && (*cp != '\t'); cp++) { if (*cp == '/') i_name = cp+1; } if (*cp) { *cp++ = '\0'; i_arg = cp; } /* * OK, we've parsed out the interpreter name and * (optional) argument. */ if (sh_bang++ == 0) { p = copy_strings(envc, envp, page, p, 0); p = copy_strings(--argc, argv+1, page, p, 0); } /* * Splice in (1) the interpreter's name for argv[0] * (2) (optional) argument to interpreter * (3) filename of shell script * * This is done in reverse order, because of how the * user environment and arguments are stored. */ p = copy_strings(1, &filename, page, p, 1); argc++; if (i_arg) { p = copy_strings(1, &i_arg, page, p, 2); argc++; } p = copy_strings(1, &i_name, page, p, 2); argc++; if (!p) { retval = -ENOMEM; goto exec_error1; } /* * OK, now restart the process with the interpreter's inode. */ old_fs = get_fs(); set_fs(get_ds()); if (!(inode=namei(interp))) { /* get executables inode */ set_fs(old_fs); retval = -ENOENT; goto exec_error1; } set_fs(old_fs); goto restart_interp; } brelse(bh); if (N_MAGIC(ex) != ZMAGIC || ex.a_trsize || ex.a_drsize || ex.a_text+ex.a_data+ex.a_bss>0x3000000 || inode->i_size < ex.a_text+ex.a_data+ex.a_syms+N_TXTOFF(ex)) { retval = -ENOEXEC; goto exec_error2; } if (N_TXTOFF(ex) != BLOCK_SIZE) { printk("%s: N_TXTOFF != BLOCK_SIZE. See a.out.h.", filename); retval = -ENOEXEC; goto exec_error2; } if (!sh_bang) { p = copy_strings(envc,envp,page,p,0); p = copy_strings(argc,argv,page,p,0); if (!p) { retval = -ENOMEM; goto exec_error2; } }/* OK, This is the point of no return */ if (current->executable) iput(current->executable); current->executable = inode; for (i=0 ; i<32 ; i++) current->sigaction[i].sa_handler = NULL; for (i=0 ; i<NR_OPEN ; i++) if ((current->close_on_exec>>i)&1) sys_close(i); current->close_on_exec = 0; free_page_tables(get_base(current->ldt[1]),get_limit(0x0f)); free_page_tables(get_base(current->ldt[2]),get_limit(0x17)); if (last_task_used_math == current) last_task_used_math = NULL; current->used_math = 0; p += change_ldt(ex.a_text,page)-MAX_ARG_PAGES*PAGE_SIZE; p = (unsigned long) create_tables((char *)p,argc,envc); current->brk = ex.a_bss + (current->end_data = ex.a_data + (current->end_code = ex.a_text)); current->start_stack = p & 0xfffff000; current->euid = e_uid; current->egid = e_gid; i = ex.a_text+ex.a_data; while (i&0xfff) put_fs_byte(0,(char *) (i++)); eip[0] = ex.a_entry; /* eip, magic happens :-) */ eip[3] = p; /* stack pointer */ return 0;exec_error2: iput(inode);exec_error1: for (i=0 ; i<MAX_ARG_PAGES ; i++) free_page(page[i]); return(retval);}
12.6 进程切换
12.6.1 进程
到内核中,溜达一圈出来
时间中断,进内核,schedule调度,转到内核中的另一个PCB,然后在返回时执行iret,弹出对应用户栈和IP,即执行对应的用户代码
12.6.2 五段论中的switch_to
linux 0.11是用TSS方式来实现的;也可以用内核栈来保存
TSS就是一个数据结构,用来保存所有的寄存器值
#define switch_to(n) {\struct {long a,b;} __tmp; \__asm__("cmpl %%ecx,current\n\t" \ "je 1f\n\t" \ "movw %%dx,%1\n\t" \ "xchgl %%ecx,current\n\t" \ "ljmp *%0\n\t" \ //最核心的部分 "cmpl %%ecx,last_task_used_math\n\t" \ "jne 1f\n\t" \ "clts\n" \ "1:" \ ::"m" (*&__tmp.a),"m" (*&__tmp.b), \ "d" (_TSS(n)),"c" ((long) task[n])); \}1)先把当前寄存器值,保存到当前TR所指向的TSS描述符所指向的tss数据结构中
2)将下一个tss数据结构恢复到各个寄存器中
12.7 汇编调用c函数
linux 0.11源码剖析 v3.0 P68
实际上是把参数都压到栈里,然后c程序就可以调用,用call来调用
但是要注意c语言 调用结束后,要把栈里的参数删掉,即addl指令,把指针改一下,忽略那些参数
call实际上执行了
push 参数
push 返回地址
jmp 调用地址
c函数右括号会生成ret指令,会返回到返回地址!
这个时候要把没用的参数从栈里去掉,这就是为什么要调用addl 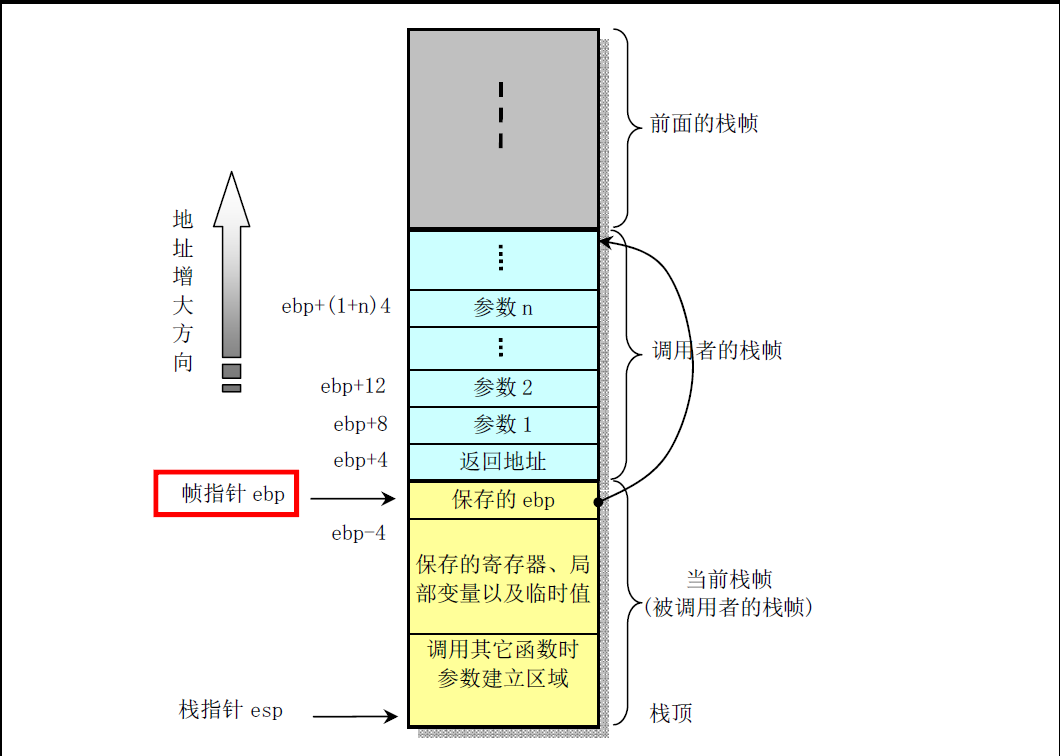



call = push 返回地址 + jmp 调用地址
不用call 直接手动 push 返回地址 + jmp 用地址的话也可以,如果push地址改成别的,返回的时候就会跳转到别的地方了
L13 操作系统的那棵树
只有进入内核才能进行内核调度,进入内核的唯一方法就是中断
七. CPU 调度
L14 CPU调度策略
14.1 指标
周转时间: 从开始申请执行任务,到执行任务完成
响应时间: 从开始申请执行任务到开始执行任务
14.2 三种调度方法
1) 先来先服务 平均周转时间可能会很长
2) 短作业优先(SJF)
周转时间短,但是响应时间长
适用于后台程序,如gcc的编译,快点把整个程序编译完成
3) 时间片轮转(RR)
响应时间可以得到保证,nT,n为任务个数,T为时间片长度,
适用于前台程序,IO操作多的
4) 优先级轮转
固定优先级,可能会造成有程序一直没法得到执行,需要动态调整优先级
14.3 schedule解析
L15 一个实际的schedule函数
COUNT的复用,既作为优先级,又作为时间片,count会改变,优先级是动态的
八. 进程同步与死锁
L16 进程同步与信号量
同步的作用: 各个程序走走停停,配合向前推进
同步 = 等待 + 唤醒
依据信号量来执行等待和唤醒
信号量 为负数表示欠
为整数表示富裕
L17 信号量临界区保护
17.1 为什么要保护
同时修改信号量可能造成empty的含义不正确

empty正常应该为-3,但是可能因为同时修改变成了-2,含义不对了
必须进入临界区以后才能修改信号量,修改完成后退出临界区,临界区是互斥的,只能有一个进程能够进入各自临界区!!!
验证保护算法是否合理的标准:
互斥进入
有空让进
有限等待 
17.2 如何实现保护
其实是进入临界区的保护
17.2.1 软件方法
1)轮换法 有空让进效果不好!!!
2)标记法 可能会造成无限制空转等待
3)非对称标记 结合了标记和轮转两种思想
两个进程:Peterson算法
多个进程:面包店算法
17.2.2 硬件方法
关闭中断来关闭调度即可
但是注意,多CPU的时候不好使
这里涉及到多cpu如何schedule
17.2.3 硬件原子指令
其实是用 mutex锁信号量 来保护信号量,为了解决mutex仍然需要保护的问题
使用硬件级原子操作,不能被打断不能切出去进行调度 
L18 信号量的代码实现
信号量的用法可以有两种:
1)sem 有正有负
-n 表示有n个进程在等待这个资源,欠了n个
+n 表示该资源有n个空余
这种可以用 if来判断是否睡眠
但是这里没说如何唤醒
2)sem 只有0,和1两种状态
1表示锁住态
0表示解锁态
在检查的时候用while处理,当锁住则睡眠,当被唤醒,重新要检查下状态是否被锁住
这个需要外围机制配合,唤醒的时候,是将整个等待此资源的队列里的所有进程都唤醒,然后让其根据优先级去竞争调度,起到优先级搞得优先获得该资源继续执行的效果!!!

唤醒等待此资源的队列里的所有进程的原理是,先唤醒队首进程,再让队首进程去唤醒下一个,以此类推,一路唤醒!!!
void sleep_on(struct task_struct **p){ //p是指向队首pcb的指针的指针 struct task_struct *tmp; tmp = *p; //tmp指向原来的队首 *p = current; current->state = TASK_UNINTERRUPTIBLE;schedule(); if (tmp) //用来唤醒下队列中下一个等待资源的进程 tmp->state=0;} 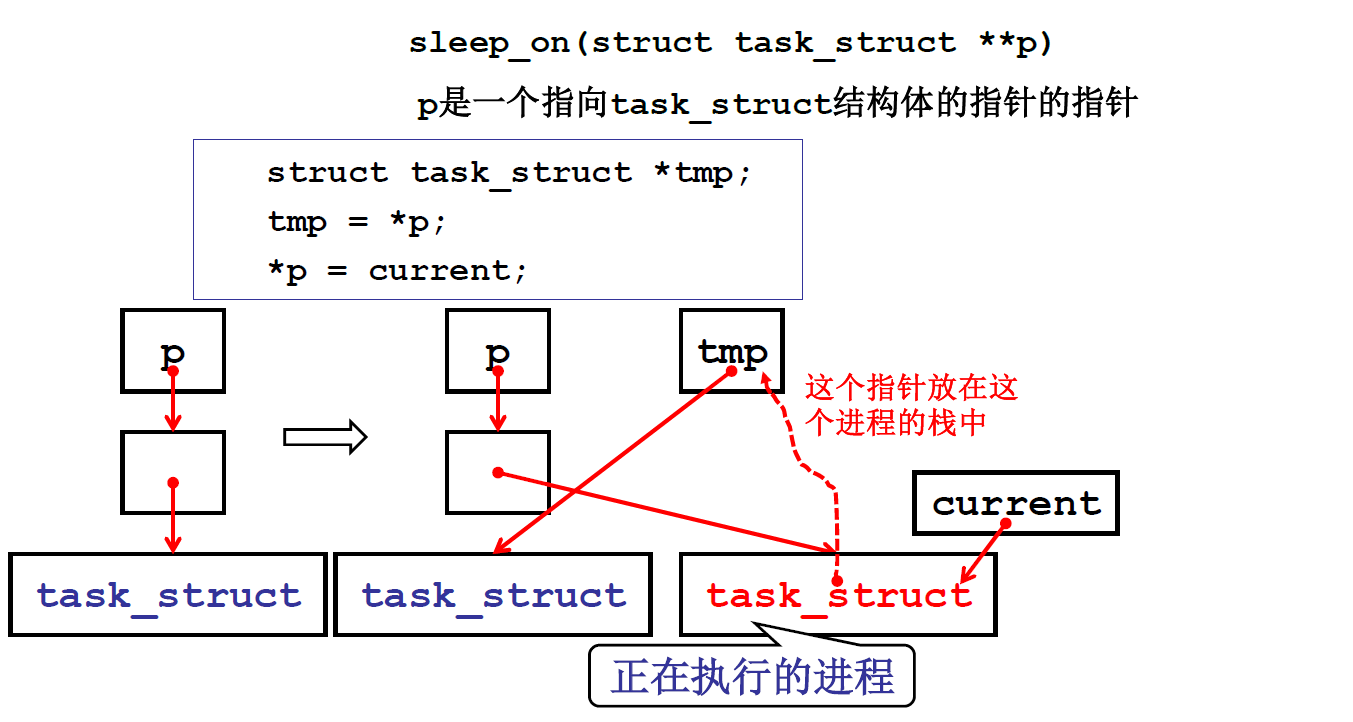
实际上市把自己作为了队首,然后用tmp记录了队列里的下一个pcb,便于在唤醒的时候能够唤醒队列里的下一个进程
L19 死锁
19.1 必要条件

形成了资源等待环路!!!
19.2 死锁处理方法

死锁预防:
死锁避免 :检测每个资源请求,假装分配,看看进程组是否会造成死锁,如果造成死锁就拒绝如果找到了安全序列,就可以这样分配。
银行家算法
但是这样的算法时间复杂度太高,每次请求资源都算一次,效率太低
死锁检测+恢复:
等出现问题了,有一些进程因为死锁而停住了,再处理,选择一个进程进行回滚,然后再用银行家算法来算是否能找到安全序列,如果不行,再回滚,直到所有程序都能执行。
但是回滚是个大问题!!!已经写入磁盘,还得退回来,那就很麻烦了。
死锁忽略:
windows,linux个人版都不做死锁处理,直接忽略,大不了重启就好了,小概率事件,代价可以接受
- 第二篇. 操作系统之 进程与线程
- 操作系统进程与线程之进程篇
- 操作系统进程与线程之线程篇
- 操作系统之进程与线程
- 操作系统 进程管理之进程与线程
- 计算机操作系统之进程与线程
- 现代操作系统学习之进程与线程
- 操作系统之进程和线程进程篇
- 《现代操作系统》读书笔记——第二章 进程与线程
- 操作系统--进程与线程
- 【操作系统】 进程与线程
- 操作系统 *** 进程与线程
- 操作系统--进程与线程
- [操作系统] 进程与线程
- 操作系统进程与线程
- 操作系统--进程与线程
- 【操作系统】进程与线程
- [操作系统] 进程与线程
- 第一章
- 将文件存储到MySQL
- Python 错误和异常小结
- Java基础--------(7)IO流Reader和Writer
- 难点统计——剑指offer与金典
- 第二篇. 操作系统之 进程与线程
- 罕见bug解决办法: kienct 1代运行错误Failed to claim camera interface: LIBUSB_ERROR_NOT_FOUND
- 【bzoj1797】[Ahoi2009]Mincut 最小割
- Android绘图基础——仿华为加载动画
- 阿里云服务器 ECS 访问不了公网 ip 可能的原因及解决方法
- 十大算法之朴素贝叶斯
- 嵌入式OS入门笔记-以RTX为案例:三.初探进程
- 根据服务器返回的状态改变前端显示的内容(Angular 过滤器)
- Redis-跳表


