google protobuf序列化原理
来源:互联网 发布:淘宝注册网店步骤 编辑:程序博客网 时间:2024/06/11 10:11
一、Java数据序列化大致有3种实现方式,1、JSON,2、Object Serialize,3、protobuf,今天重点解析第三种使用google protobuf的序列化原理。
Protobuf的简单介绍、使用和分析
一、protobuf是什么?
protobuf(Google Protocol Buffers)是Google提供一个具有高效的协议数据交换格式工具库(类似Json),但相比于Json,Protobuf有更高的转化效率,时间效率和空间效率都是JSON的3-5倍。后面将会有简单的demo对于这两种格式的数据转化效率的对比。但这个库目前使用还不是太流行,据说谷歌内部很多产品都有使用。
二、protobuf有什么?
Protobuf 提供了C++、Java、Python语言的支持,提供了windows(proto.exe)和Linux平台动态编译生成proto文件对应的源文件。proto文件定义了协议数据中的实体结构(message ,field)
简易的proto文件
syntax = "proto3";option java_multiple_files = true;option java_outer_classname = "AccountGatewayProto";package com.whtr.appbe.gateway.account;service AccountGateway { rpc GetUserInfo(UserInfoReq) returns (UserInfoResp )}message UserInfoResp { ///userId required int64 userId = 1; ///姓名 string name = 2; ///年龄 int32 age = 3;}message UserInfoReq{ ///userId required int64 userId = 1; ///Platform Platform reqPlatform = 2;}enum Platform { Android = 0; IOS = 1;}关键字message: 代表了实体结构,由多个消息字段(field)组成。
消息字段(field): 包括数据类型、字段名、字段规则、字段唯一标识、默认值
数据类型:常见的原子类型都支持(在FieldDescriptor::kTypeToName中有定义)
字段规则:(在FieldDescriptor::kLabelToName中定义)
required:必须初始化字段,如果没有赋值,在数据序列化时会抛出异常 optional:可选字段,可以不必初始化。 repeated:数据可以重复(相当于java 中的Array或List) 字段唯一标识:序列化和反序列化将会使用到。默认值:在定义消息字段时可以给出默认值。
service rpc定义了rpc服务,由实际的service继承实现AccountGatewayImplBase中定义的rpc方法
三、protobuf有什么用?
Xml、Json是目前常用的数据交换格式,它们直接使用字段名称维护序列化后类实例中字段与数据之间的映射关系,一般用字符串的形式保存在序列化后的字节流中。消息和消息的定义相对独立,可读性较好。但序列化后的数据字节很大,序列化和反序列化的时间较长,数据传输效率不高。
Protobuf和Xml、Json序列化的方式不同,采用了二进制字节的序列化方式,用字段索引和字段类型通过算法计算得到字段之前的关系映射,从而达到更高的时间效率和空间效率,特别适合对数据大小和传输速率比较敏感的场合使用。
四、protobuf的简单分析
1、优缺点
优点:通过以上的时间效率和空间效率,可以看出protobuf的空间效率是JSON的2-5倍,时间效率要高,对于数据大小敏感,传输效率高的模块可以采用protobuf库
缺点:消息结构可读性不高,序列化后的字节序列为二进制序列不能简单的分析有效性;目前使用不广泛,只支持java,C++和Python;
2、数据序列化/反序列化
a、规则:
protobuf把消息结果message也是通过 key-value对来表示。只是其中的key是采取一定的算法计算出来的即通过每个message中每个字段(field index)和字段的数据类型进行运算得来的key = (index<<3)|type;
type类型的对应关系如下:
Varints算法描述: 每一个字节的最高位都是有特殊含义的,如果是1,则表示后续的字节也是该数字的一部分;如果是0,则结束
b、demo生成的的二进制文件反序列化。
第1个字节 (0A)
字段索引(index): 0A = 0001010 0A>>3 = 001 = 1
数据类型(type): 0A = 0001010&111 = 2 (String);
第2个字节 (0C)
字符串长度(length): 0E = 12;
字符串: 0A 05 69 64 6F 6C 33 10 01 18 BD 0F
第3个字节 (0A)
因为字符串是来自phoneInfo属于嵌套类型
字段索引(index): 0A = 0001010 0A>>3 = 001 = 1
数据类型(type): 0A = 0001010&111 = 2 (String);
第4-9个字节(69 64 6F 6C 33)
字符串长度(length): 05 = 5
字符串: 69 64 6F 6C 33 = idol3
第10个字节 (10)
字段索引(index): 10 = 00010000 10A>>3 = 0010 = 2
数据类型(type): 10 = 00010000&111 = 0 (Varints);
第11个字节 (01)
Varints: 01 = 00001字节的最高位为0 整数结束
Value: 1;
第12个字节(18)
字段索引(index): 18 = 00011000 18>> 00011 = 3
数据类型(type): 18 = 00011000&111 = 0 (Varints);
第13个字节(D0)
最高位为1,整数计算到下一个字节
第14个字节(0F)
最高位为0,整数计算结束
Value:为11111010000 =2000
C、反序列化结果
phoneinfo为:
phoneName = “idol3”
top = 1
price = 2000;
同样的方法watchInfo为:
watchName = “tcl name”
top = 1
price=2000
3、时间效率
通过protobuf序列化/反序列化的过程可以得出:protobuf是通过算法生成二进制流,序列化与反序列化不需要解析相应的节点属性和多余的描述信息,所以序列化和反序列化时间效率较高。
4、空间效率
xml、json是用字段名称来确定类实例中字段之间的独立性,所以序列化后的数据多了很多描述信息,增加了序列化后的字节序列的容量。
Protobuf的序列化/反序列化过程可以得出:
protobuf是由字段索引(fieldIndex)与数据类型(type)计算(fieldIndex<<3|type)得出的key维护字段之间的映射且只占一个字节,所以相比json与xml文件,protobuf的序列化字节没有过多的key与描述符信息,所以占用空间要小很多。
五、Protobuf的源码分析
1、protobuf在java使用的序列化流程
java程序调用parserFrom(byte[] data)开始字节序列的反序列,Java程序通过调用编译生类GenerateMessage中的wirteTo()方法开始将序列化后的字节写入输出流中
GenerateMessage 继承AbstractMessage类,序列化最终在AbstractMesssage中完成,序列化的实现过程:
a、遍历对象中Message结构()
调用AbstractMessage类中的writeTo()方法
b、 序列化Message中每一个字段
调用CodeOutputStream类中的writeMessageSetExtension()方法
c、 对于Varints Tag 的序列化流程:
调用CodeOutputStream类中的writeUInt32()方法
调用CodeOutputStream类中的WriteRawVarint32()方法
d、 对于非Varints Tag的序列化
调用CodeOutputStream类中的WriteTag()方法
具体的序列化实现都在CodedOutputStream中完成
2、java使用protobuf 的反序列化流程分析
java程序通过调用parserFrom(byte[] data)开始反序列化
具体在com.google.protobuf. AbstractParser类中实现
最后在com.google.protobuf.CodedInputStream类中完成反序列化
总结:
一个message,序列化时首先就算这个message所有filed序列化需要占用的字节长度,计算这个长度是非常简单的,因为protobuf中每种类型的filed所占用的字节数是已知的(bytes、string除外),只需要累加即可。这个长度就是serializedSize,32为integer,在protobuf的某些序列化方式中可能使用varint32(一个压缩的、根据数字区间,使用不同字节长度的int);
此后是filed列表输出,每个filed输出包含int32(tag,type)和value的字节数据,我们知道每个filed都有一个唯一的数字tag表示它的index位置,type为字段的类型;如果filed为string、bytes类型,还会在value之前额外的补充添加一个varint32类型的数字,表示string、bytes的字节长度。
消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对,如下图 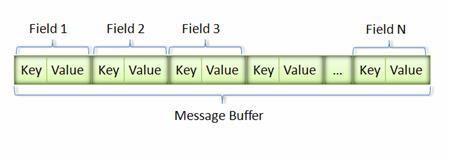
二进制格式的message使用数字标签作为key,Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field。
那么在反序列化的时候,首先读取一个32为的int表示serializedSize,然后读取serializedSize个字节保存在一个bytebuffer中,即读取一个完整的package。然后读取一个int32数字,从这个数字中解析出tag和type,如果type为string、bytes,然后补充读取一个varint32就知道了string的字节长度了,此后根据type或者字节长度,读取后续的字节数组并转换成Java type。重复上述操作,直到整个package解析完毕。
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
上边我们说,“二进制格式的message使用数字标签作为key”,此处的数字标签,并非单纯的数字标签,而是数字标签与传输类型的组合,根据传输类型能够确定出值的长度。
key的定义: (field_number << 3) | wire_type
Key 由两部分组成。第一部分是 field_number,第二部分为 wire_type。表示 Value 的传输类型。也就是说,key中的后三位,是值的传输类型
- google protobuf序列化原理
- google protobuf序列化原理
- protobuf序列化原理
- C++序列化方法 参考google protobuf
- Google 开源序列化框架protobuf
- Netty集成Google的ProtoBuf序列化
- google protobuf入门(序列化和反序列化)
- 每周一荐:Google的序列化框架Protobuf
- 细说google protobuf序列化 与相关改进方案
- google protobuf 升级版 com.dyuproject.protostuff java 序列化
- google protobuf 使用和原理
- Protobuf序列化协议
- protobuf序列化存储
- protobuf (序列化协议)
- 序列化protobuf
- Google Protobuf Primer (1) 实现跨平台跨语言的序列化/反序列化
- Google Protobuf - 实现跨平台跨语言的序列化/反序列化
- Google Protobuf——实现跨平台跨语言的序列化/反序列化
- Java中的ThreadLocal
- Python中为什么没有switch-case
- Spring框架的特性
- ubuntu系统备份与恢复-remastersys方法
- Leetcode 460. LFU Cache
- google protobuf序列化原理
- WebView的优化--使用腾讯的x5内核
- 腾讯微信技术总监周颢:一亿用户增长背后的架构秘密
- struts-2.5 入门配置
- 机器学习(1.1)——Logistic回归的详细推导
- 解释器模式
- Linux 常用命令
- (OK) Android-x86-7.1.1/ kernel 4.4.62/ MPTCP-0.92/ quagga/ospf6d/ MIMP(MultiInterface MultiPath)
- 《css揭秘》学习笔记(一)


