Multiple Language Syntax Highlighting, Part 1: JScript
来源:互联网 发布:网络k歌人声效果器 编辑:程序博客网 时间:2024/06/06 00:06
Multiple Language Syntax Highlighting, Part 1: JScript
By Jonathan de Halleux- highlight_src.zip (112.3 Kb)
- highlight-demo.zip (8.9 Kb)
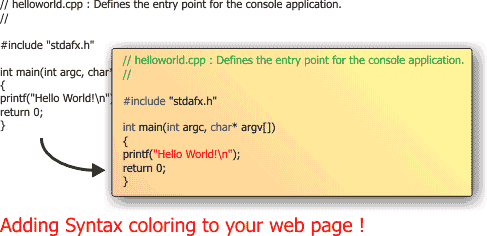
Outline
This is the first of a 2 articles serie. In this article, thetechniques and ideas are discussed and a Javascript solution is given.In Part 2, a C# solution is given.
Unfortunately for JScript users, I will not update the JScript code and focus on C# only. :)
Introduction
Have you ever wondered how the CP team highlights the source code intheir edited article ? I suppose it's not by hand and they must havesome clever code to do it.
However, if you look around in the forums on the web, you will seethat there are few if any who have this feature. Sad thing, becausecolored source code is much easier to read. In fact, it would be greatto have source code in forums automatically colored with your favoritecoloring scheme.
The last-but-not-least reason for writing this article was to learn regular expressions, javascript and DOM in one project.
The source code entirely written in JScript so it can be included server-side or client-side in your web pages.
The techniques used are:
- regular expressions
- XML DOM
- XSL transformation
- CSS style
When reading this article, I will assume that you have littleknowledge of regular expressions, DOM and XSLT although I'm also anewbie in those 3 topics.
Live Demo
CP does not acceptscript or form tags in the article. To play with the live demo, download the "JScript" enabled page (see download section). Transformation Overview
 Parsing pipe
Parsing pipeAll the boxes will be discussed in details in the next chapter. I will give here an short overview of the process.
First, a language syntax specification file is loaded (Languagespecification box). This specification is a plain xml file given by theusers. In order to speed up things, preprocessing is made on thisdocument (Preprocessing box).
Let us suppose for simplicity that we have the source code tocolorize (Code box). Note that I will show how to apply the coloring toa whole html page later on. The parser, using the preprocessed syntaxdocument, builds an XML document representing the parsed code (Parsingbox). The technique used by the parser is to split up the code in asuccession of nodes of different types: keyword, comment, litteral,etc...
At last, an XSTL transformation are applied to the parsed codedocument to render it to HTML and a CSS style is given to match thedesired appearance.
Parsing Procedure
The philosophy used to build the parser is inspired from the Kate documentation (see [1]).
The code is considered as a succession of contexts. For example, in C++,
- keyword: if, else, while, etc...
- preprocessor instruction: #ifdef, ...
- literals: "..."
- line comment: // ...
- block comment: /* ... */
- and the rest.
For each context, we define rules that have 3 properties:
- a regular expression for matching a string
- the context of the text matched by the rule: attribute
- the context of the text following the rule: context
The rules have priority among them. For example, we will first lookfor a /* ... */ comment, then a // ... line comment, then litteral,etc...
When a rule is matched using a regular expression, the string matched by the rule is assigned with the attribute context, the current context is updated as contextand the parsing continues. The diagram show the possible path betweencontexts. As one can see, some rule do not lead to a need context.

Context dynamics
Let me explain a bit the schema below. Consider that we are in the code context. We are going to look for the first match of the code rules: /**/, //, "...", keyword.Moreover, we have to take into account their priorities: a keyword isnot really a keyword in a block of comment, so it has a lower priority.This task is easily and naturally done through regular expressions.
Once we find a match, we look for the rule that triggered that match(always following the priority of the rules). Therefore, pathologicallike is well parsed:
// a keyword while in a commentwhile is not considered as a keyword since it is in a comment. Rules Available
There are 5 rules currently available:
- detect2chars: detects a pattern made of 2 characters.
- detectchar: detects a pattern made of 1 character.
- linecontinue: detects end of line
- keyword:detect a keyword out of a keyword family
- regexp:matches a regular expression.
regexp is by far the most powerful rule of all as all other rules are represented internally by regular expressions.
Language Specification
From the rules and context above, we derive an XML structure as described in the XSD schema below (I don't really understand xsd but .Net generates this nice diagram...)
 Language specification schema. Click on the image to view it full size.
Language specification schema. Click on the image to view it full size.I will breifly discuss the language specification file here. For more details, look at the xsd schema or at highlight.xmlspecification file (for C++). Basically, you must define families ofkeywords, choose context and write the rule to pass from one to another.
Nodes
NameTypeParent NodeDescriptionhighlightrootnoneThe root node
needs-buildA (optional)highlight"yes" if file needs preprocessingsave-buildA (optional***)highlight"yes" if file has to be saved after preprocessingkeywordlistsEhighlightNode containing families of keywords as childrenkeywordlistEkeywordlistA family of keywordsidAkeywordlistString identifierpreA (optional)keywordlistRegular to append before keywordpostA (optional)keywordlistRegular to append at the end of the keywordregexpA (optional*)keywordlistRegular expression matching the keyword family. Build by the preprocessorkwEkeywordlistText or CDATA node containing the keywordslanguagesEhighlightNode containing languages as childrenlanguageElanguagesA language specificationcontextsElanguageA collection of context nodedefaultAcontextsString identifying the default contextcontextEcontextsA context node containing rules as childrenidAcontextString identifierattributeAcontextThe name of the node in which the context will be stored.detect2chars**EcontextRule to dectect pair of characters. (ex:/*)charAdetect2charsFirst character of the patternchar1Adetect2charsSecond character of the patterndetectchar**EcontextRule to dectect one character. (ex: ")charAdetectcharcharacter to matchkeyword**EcontextRule to match a family of keywordsfamilyAkeywordFamily indentifier, must match /highlight/keywordlists/keyword[@id]regexpEcontextA regular expression to matchexpressionAregexpthe regular expression.Comments: - *: this argument is optional at the condition that preprocessingtakes place. The usual way to do is to always preprocess or topreprocess once with the "save-build" parameter set to "yes" so thatthe preprocessing is save. Note that if you modify the language syntax,you will have to re-preprocess.
- **: all those element have two other attributes: attribute (optional)Aa ruleThe name of the node in which the string match will be stored. If not set or equal to "hidden", no node is created.contextAa ruleThe next context.
- ***: Client-side javascript is not allowed to write files. Hence, this option aplies only to server-side execution.
Preprocessing
In the preprocessing phase, we are going to build the regular expressions that will be used later on to match the rules. This section makes an extensive use of regular expressions.As mentionned before, this is not a tutorial on regular expressionssince I'm also a newbie in that topic. A tool that I have found to be really useful is Expresso (see [3]) a regular expression test machine.Keyword Families
Building the keyword families regular expressions is straightforward. You just need to concatenate the keywords togetter using |:<keywordlist ...>
<kw>if</kw>
<kw>else</kw>
</keywordlist>will be matched by /b(if|else)/bThe generated regular expression is added as an attribute to the keywordlist node:
<keywordlist regexp="/b(if|else)/b">
<kw>if</kw>
<kw>else</kw>
</keywordlist>When using libraries of function, it is usual to have a common function header, like for OpenGL:
glVertex2f, glPushMatrix(), etc...
You can skip the hassle of rewritting gl in all the kw items by using the attribute pre which takes a regular expression as a parameter: <keywordlist pre="gl" ...>
<kw>Vertex2f</kw>
<kw>PushMatrix</kw>
</keywordlist>will be matched by /bgl(Vertex2f|PushMatrix)/bYou can also add regular expression after the keyword using post. Still working on our OpenGL example, there are some methods that have characters at the end to tell the type of parameters: glCoord2f: takes 2 floats,glRaster3f: takes 3 floats,glVertex4v: takes an array of floats of size 4
post and regular expression, we can match it easily: <keywordlist pre="gl" post="[2-4]{1}(f|v){1}" ...>
<kw>Vertex</kw>
<kw>Raster</kw>
</keywordlist>will be matched by /bgl(Vertex2f|PushMatrix)[2-4]{1}(f|v){1}/bString Literals
This is a little exercise on regular expression: How to match a literal string in C++? Remember that it must support /", end of line with /.
My answer (remember I'm a newbie) is
"(.|//"|///r/n)*?((////)+"|[^//]{1}")I tested this expression on the following string: "a simple string"
---
"a less /" simple string"
---
"a even less simple string //"
---
"a double line/
string"
---
"a double line string does not work without
backslash"
---
"Mixing" string "can/"" become "tricky"
---
"Mixing /" nasty" string is /" even worst"
Contexts
The context regular expression is also build by concatenating theregular expression of the rules. The value is added as an attribute tothe context node:
<context regexp="(...|...)">Controlling if Preprocessing is Neccessary
It is possible toskip the preprocessing phase or to save the "preprocessed" languagespecification file. This is done by specifying the following parametersin the root node highlight AttributeDescriptionDefaultneed-build"yes" if needs preprocessingyessave-build"yes" if saving preprocessed language specification to disknoJavascript call
The preprocessing phase is done through the javascript method loadAndBuildSyntax:
// language specification file
var sXMLSyntax = "highlight.xml";
// loading is done by loadXML
// preprocessing is done in loadAnd... It returns a DOMDocument
var xmlDoc = loadAndBuildSyntax( loadXML( sXMLSyntax ) );Parsing
We are going to use the language syntax above to build an XMLtree out of the source code. This tree will be made out of successive context nodes.We can start parsing the string (pseudo-code below):
source = source code;
context = code; // current context
regExp = context.regexp; // regular expresion of the current context
while( source.length > 0)
{
Here we follow the procedure: - find first match of the contextrules
- store the source before the match
- find the rule that was matched
- process the rule parameters
match = regExp.execute( source );
// check if the rules matched something
if( !match)
{
// no match, creating node with the remaining source and finishing.
addChildNode( context // name of the node,
source // content of the node);
break;
}
else
{
The source before the match has to be stored in a new node: addChildNode( context, source before match);
We now have to find the rule that has matched. This is done by the method findRule that returns the rule node. The rule is then processed using attribute and context parameters.
// getting new node
ruleNode = findRule( match );
// testing if matching string has to be stored
// if yes, adding
if (ruleNode.attribute != "hidden")
addChildNode( attribute, match);
// getting new context
context=ruleNode.context;
// getting new relar expression
regExp=context.regexp;
}
}
At the end of this method, we have build an XML tree containing thecontext. For example, consider the classic of the classic "Hello world"program below:
int main(int argc, char* argv[])
{
// my first program
cout<<"Hello world";
return -1;
};
This sample is translated in the following xml structure: <parsedcode lang="cpp" in-box="-1">
<reservedkeyword>int</reservedkeyword>
<code> main(</code>
<reservedkeyword>int</reservedkeyword>
<code> argc, >Here is the specification of the resulting XML file: Node NameTypeParent NodeDescriptionparsedcoderootRoot node of documentlangAparsedcodetype of language: c, cpp, jscript, etc.in-boxAparsedcode-1 if it should be enclosed in a pre tag, otherwize in code tagcodeEparsedcodenon special source codeand others...Eparsedcode
Javascript Call
The algorithm above is implemented in the applyRules method:
applyRules( languageNode, contextNode, sCode, parsedCodeNode);
where
languageNodeis the current language node (XMLDOMNode),contextNodeis the start context node (XMLDOMNode),sCodeis the source code (String),parsedCodeNodeis the parent node of the parsed code (XMLDOMNode)
XSLT Transformation
Once you have the XML representation of your code, you can basically do whatever you want with it using XSLT transformations.
Header
Every XSL file starts with some declarations and other standard options:
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output encoding="ISO-8859-1" indent="no" omit-xml-declaration="yes"/>Since source code indenting has to be conserved, we disable automatic indenting and, also the xml declaration is omitted:
<xsl:output encoding="ISO-8859-1" indent="no" omit-xml-declaration="yes"/>Basic Templates
<xsl:template match="cpp-linecomment">
<span class="cpp-comment">//<xsl:value-of select="text()"
disable-output-escaping="yes" /></span>
</xsl:template>This template appies to the node cpp-linecomment which corresponds to single line comment in C++.
We apply the CSS style to this node by encapsulating it in span tags and by specifying the CSS class.
Moreovern, we do not want character escaping for that, so we use
<xsl:value-of select="text()" disable-output-escaping="yes" /></span>The Parsedcode Template
It gets a little complicated here. As everybody knows, XSL quiclybecomes really complicated once you want to do more advancedstylesheets. Below is the template for parsedcode, it does simple thing but looks ugly:
Checks if in-box parameter is true, if true create pre tags, otherwize create code tags.
<xsl:template match="parsedcode">
<xsl:choose>
<xsl:when test="@in-box[.=0]">
<xsl:element name="span">
<xsl:attribute name="class">cpp-inline</xsl:attribute>
<xsl:attribute name="lang">
<xsl:value-of select="@lang"/>
</xsl:attribute>
<xsl:apply-templates/>
</xsl:element>
</xsl:when>
<xsl:otherwise>
<xsl:element name="pre">
<xsl:attribute name="class">cpp-pre</xsl:attribute>
<xsl:attribute name="lang">
<xsl:value-of select="@lang"/>
</xsl:attribute>
<xsl:apply-templates/>
</xsl:element>
</xsl:otherwise>
</xsl:choose>
</xsl:template>Javascript Call
This is where you have to customize a bit the methods. The rendering is done in the method highlightCode:
highlightCode( sLang, sRootTag, bInBox, sCode)where sLangis a string identifying the language ( "cpp" for C++),sRootTagwill the node name encapsulation the code. For example,prefor boxed code,codefor inline code,bInCodea boolean set to true ifin-boxhas to be set to true.sCodeis the source code- it returns the modified code
The file names are hardcoded inside the highlightCode method: hightlight.xml for the language specification, highlight.xsl for the stylesheet. In the article, the XML syntax is embed in a xml tag and is simply accessed using the id
Applying Code Transformation to an Entire HTML Page.
So now you are wondering how to apply this transformation to an entire HTML page? Well surprisingly, this can be done in... 2 lines! In fact, there exist the method String::replace(regExp, replace) that replaces the substring matching the regular expressions regExp with replace. The best part of the story is that replace can be a function... So we just (almost) need to pass highlightCode and we are done.
For example, we want to match the code enclosed in pre tags:
// this is javascript
var regExp=/<pre>(.|/n)*?<//pre>/gim;
// render xml
var sValue = sValue.replace( regExp,
function( $0 )
{
return highlightCode("cpp", "cpp",$0.substring( 5, $0.length-6 ));
}
);
In practice, some checking are made on the language name and all these computations are hidden in the replaceCode method.
Using the Methods in your Web Wite
ASP Pages
To use the highlightin scheme in your ASP web site:- Put the javascript code between script tags in an asp page:
 Collapse
Collapse<script language="javascript" runat="server">
...
</script> - include this page where you need it
- modify the method
processAndHighlightCodeto suit your needs - modify the method handleException to redirect the exception to the Response
- apply this method to the HTML code you want to modify
- update your
cssstyle with the corresponding classes.
Demonstration Application
The demonstration application is a hack of the CodeProject Article Helper. Type in code in pre or code to see the results.
Update History
- Added demonstration in the article!
- Added new languages: JScript, VBScript, C, XML
- Now handling <pre lang="..."> bracketting: you can specify the language of the code.
loadAndBuildSyntaxtakes a DomDocument as parameter. You can call it like this:loadAndBuildSyntax( loadXML( sFileName ))highlightCodetakes one more argument: bInBox.
- Added
pre,post to the keyword rule <li> The text disapearing in <code> brackets is fixed. The bug was in processAndHighlightArcticle (bad function argument).</li> </ul>
References
[1]The Kate Syntax Highlight System documentation files. [2]The Code Project Article Helper, Jason Henderson [3]Expresso - A Tool for Building and Testing Regular Expressions, Hollenhorst [4]Article Part 2License
Thisarticle has no explicit license attached to it but may contain usageterms in the article text or the download files themselves. If in doubtplease contact the author via the discussion board below.
A list of licenses authors might use can be found here
About the Author
Jonathan de Halleux
Jonathan de Halleux is Civil Engineer in Applied Mathematics. Hefinished his PhD in 2004 in the rainy country of Belgium. After 2 yearsin the Common Language Runtime (i.e. .net), he is now working atMicrosoft Research on Pex (http://research.microsoft.com/pex).
Occupation: EngineerLocation:
From: http://www.codeproject.com/KB/scripting/highlight.aspx
- Multiple Language Syntax Highlighting, Part 1: JScript
- Multiple Language Syntax Highlighting, Part 1: JScript
- syntax highlighting
- CRichEditCtrl for Syntax HighLighting
- vim syntax highlighting
- 9 Useful Javascript Syntax Highlighting Scripts
- syntax highlighting in LESS command on Ubuntu
- Java - Language Syntax 090820
- ARM Assembly Language Programming (part 1)
- How to get a syntax-highlighting code text
- syntax highlighting when editing your .cu files in Visual Studio
- How to enable syntax highlighting and other options in VIM
- Quick Tip: How to Add Syntax Highlighting to Any Project
- vim syntax highlighting for scala : A bash one liner
- HTML syntax highlighting with the Rich Edit control
- Class in Jscript Part I
- Highlighting System4.1的使用
- MSIL - the language of the CLR (Part 1)
- javascript基础学习
- bnu1281 忙乱的活动 C语言版
- 神秘的 ORACLE DUAL
- Spring AOP在DWR安全上的应用
- Oracle的Window服务启动时并不启动实例
- Multiple Language Syntax Highlighting, Part 1: JScript
- ASP Studio 2005 1.45编程工具
- 汇编语言學習
- ADO.NET 如何读取 Excel (下)
- 实现 asp 的服务器无刷新推技术
- 使用bacula实现Linux的远程备份和还原
- 自己用的个人展示网站,刚出炉(含源码)
- 有关IIS和有关用户权限设置问题
- ubuntu下wine 的使用


