object detection目标检测,Image classification图片分类,Instance Segmentation 和 Semantic Segmentation
来源:互联网 发布:云计算控制节点 编辑:程序博客网 时间:2024/06/05 11:56
链接:https://www.zhihu.com/question/51704852/answer/127120264
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
最近也在做跟这个相关的问题,来分享一下自己的见解.
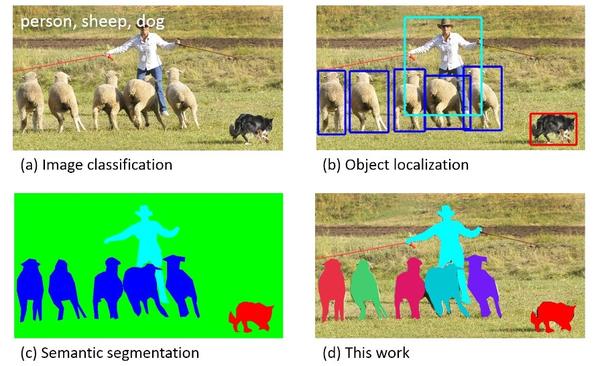
图1. 这张图清楚说明了image classification, object detection, semantic segmentation, instance segmentation之间的关系. 摘自COCO dataset (https://arxiv.org/pdf/1405.0312.pdf)
Semantic segmentation的目的是在一张图里分割聚类出不同物体的pixel. 目前的主流框架都是基于Fully Convolutional Neural Networks (FCN,详情见https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf).FCN区别于物体识别网络诸如AlexNet最主要的差别是pixel-wise prediction,就是每个像素点都有个probability, 而AlexNet是一张图一个prediction.AlexNet或者VGG通过一个小的trick(caffe/net_surgery.ipynb at master · BVLC/caffe · GitHub)就可以转变成FCN. 这里有个八卦是当年FCN得到CVPR'15 best paper honorable mention的时候, Yann LeCun等人出来吐槽这个'FCN'的概念早就有了,AlexNet里面的fully connected layer (FC)本身就是个误导,因为FC layer可以看成是1x1的convolution, 本来就可以输入任意大小的图片.
Semantic segmentation的其他典型代表还有诸SegNet, Dilated Convolution Net, deconvolutionNet
等.这里又有两个八卦,比如SegNet相关的几篇论文连续投了两年多到现在都还没中(作者要哭晕在厕所里了),以及关于deconvolution, dilated convolution, atrous convolution这几个概念的争论(这里有篇分析我觉得不错Dilated Convolutions and Kronecker Factored Convolutions).在我个人使用过程中,相对于FCN等带skip connection结构的网络,我更喜欢类似于Dilated Net这种桶状结构的网络,原因是带skip connection的网络由于需要normalize不同layer之间的activation, 比较难训练. Liu Wei有一篇专门分析这个layer之间normalization trick的论文(http://www.cs.unc.edu/~wliu/papers/parsenet.pdf).
切入正题,semantic segmentation把图片里人所在的区域分割出来了,但是本身并没有告诉这里面有多少个人,以及每个人分别的区域.这里就跟instance segmentation联系了起来,如何把每个人的区域都分别分割出来,是比semantic segmentation要难不少的问题.基于semantic segmentation来做instance segmentation的论文,大家可以看看Jifeng Dai最近的几篇论文:https://arxiv.org/pdf/1512.04412v1.pdf,https://arxiv.org/pdf/1603.08678v1.pdf. 大致做法是在dense feature map上面整合个instance region proposal/score map/RoI, 然后再分割.
这里instance segmentation本身又是跟object detection是紧密相关的.最近Facebook放出来的DeepMask和SharpMask(GitHub - facebookresearch/deepmask: Torch implementation of DeepMask and SharpMask), 很明确地点出了两者关系. 我之前跟Piotr Dollar也讨论过这个问题, 他自己觉得: semantic segmentation is a bad direction, we should focus on object detection. 我不赞同他的观点,但觉得还是挺有道理:) 这里可以想象, 如果object proposal和object detection能做得非常好, instance segmentation本身这个问题就能比较好的解决. COCO detection challenge (COCO - Common Objects in Context) 里面一个track, 就是要求predict segmentation mask rather than bbox, 可惜今年只有两个队参加(你参加的话再差都是第三哟:p) .
总结一下, instance segmentation其实是semantic segmentation和object detection殊途同归的一个结合点, 是个挺重要的研究问题. 我非常期待后面能同时结合semantic segmentation和object detection两者优势的instance segmentation算法和网络结构.
链接:https://www.zhihu.com/question/51704852/answer/127120264
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
图2. Scene Parsing (MIT Scene Parsing Challenge 2016) from ADE20K dataset (ADE20K dataset). 每张图的每个物体以及物体的物体都有清楚的标注.
最后,我个人觉得之所以大家猛搞semantic segmentation而忽略instance segmentation的一个原因是没有好的数据集. pascal dataset里面一张图片里的instance数量非常少, 而且物体种类也只有20种. 这里自荐下我自己的工作, 我们组最近搞了个Scene parsing dataset and challenge (MIT Scene Parsing Challenge 2016). 这里scene parsing跟semantic segmentation最大的不同是我们包含了150类概念类别(包括离散物体类别诸如person, car, table, 也包含了很多stuff类别, 如floor, ceiling, wall) , 图片里面每个pixel都需要被predict. 分割floor, ceiling, wall这些类对于robot navigation等应用也是非常重要,但是他们并没有instance segmentation的概念. 今年我们的scene parsing challenge采用semantic segmentation的框架进行, 大家提出了不少新颖的模型, 也挺受欢迎 . 我们明年的scene parsing challenge (ICCV'17) 将设立instance segmentation track, 希望能推动instance segmentation 的进步.
再然后,其实semantic segmentation可以用到很多地方,比如说我们lab之前的一个PhD把这个用在medical imaging中癌症细胞的检测和分割(https://people.csail.mit.edu/khosla/papers/arxiv2016_Wang.pdf),拿了奖,还开了自己的startup :)- object detection目标检测,Image classification图片分类,Instance Segmentation 和 Semantic Segmentation
- Instance Segmentation 和 Semantic Segmentation
- Instance Segmentation Semantic Segmentation
- 目标检测 R-CNN 论文笔记(Rich feature hierarchies for accurate object detection and semantic segmentation)
- Classification with an edge: Improving semantic image segmentation with boundary detection
- DeepLab: Semantic Image Segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierachies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation
- Rich feature hierarchies for accurate object detection and semantic segmentation
- zifeng wu instance level segmentation:Bridging Category-level and Instance-level Semantic Image
- Instance Segmentation 比 Semantic Segmentation 难很多吗?
- 论文阅读:BiSeg: Simultaneous Instance Segmentation and Semantic Segmentation
- Salient Object Detection and Segmentation
- Instance-aware Semantic segmentation (MNC)笔记
- Semantic segmentation
- Semantic Segmentation
- jquery-ui之dialog的使用
- 最大数
- mybatis批量插入clob,ORA-01461-仅能绑定要插入LONG列的LONG值
- Swing 的java文件写好之后显示不全的问题
- 个人开发环境搭建 ubuntu
- object detection目标检测,Image classification图片分类,Instance Segmentation 和 Semantic Segmentation
- Python 刷题日记:LeetCode: 1&15&16-Two Sum and 3Sum
- RecyclerView ItemTouchHelper源码分析扩展
- 微软云Centos byobu安装
- Linux 远程连接工具使用-putty 密钥验证
- Java Clone研究
- 入门-误差逆传播算法
- crond和crontab
- NodeJS镜像配置


