Spark Python 快速体验
来源:互联网 发布:log4j写入mysql数据库 编辑:程序博客网 时间:2024/05/22 06:21
Spark是2015年最受热捧大数据开源平台,我们花一点时间来快速体验一下Spark。
Spark 技术栈
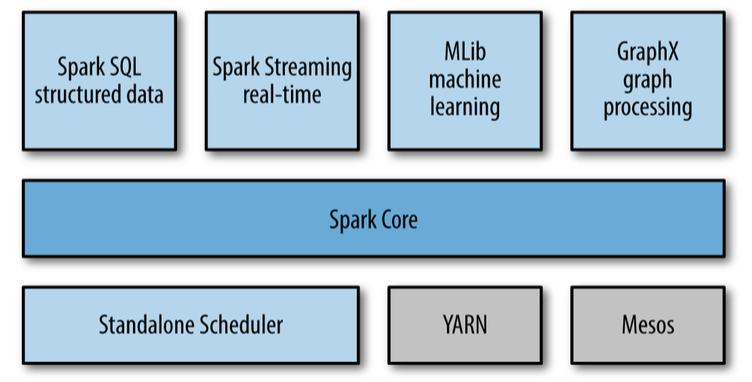
如上图所示,Spark的技术栈包括了这些模块:
核心模块 :Spark Core
集群管理
Standalone Scheduler
YARN
Mesos
Spark SQL
Spark 流 Streaming
Spark 机器学习 MLLib
GraphX 图处理模块
安装和启动Spark
Spark Python Shell
> bin/pysparkSpark Ipython Shell
> IPYTHON=1 ./bin/pyspark> IPYTHON_OPTS="notebook" ./bin/pysparkSpark 架构
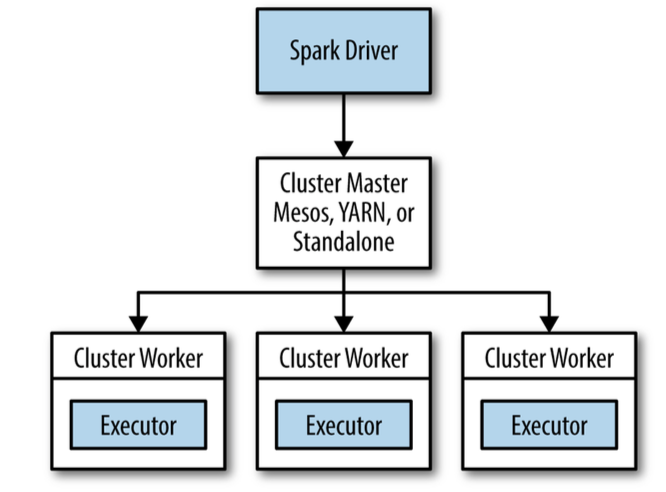
初始化 Spark Context
在使用Spark的功能之前首先要初始化Spark的context,Context包含了Spark的连接和配置信息。
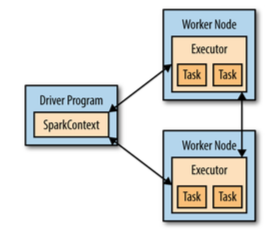
Spark Context,Driver和Worker节点之间的关系如下图:
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local").setAppName("My App")sc = SparkContext(conf = conf)创建 RDD
RDD是Spark的基本数据模型,所有的操作都是基于RDD。RDD是inmutable(不可改变)的。
lines = sc.textFile("README.md")pythonLines = lines.filter(lambda line: "Python" in line) pythonLines.first()pythonLines.count()RDD 操作:
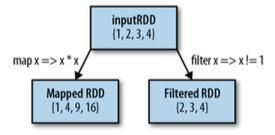
下面是一些对RDD的变形操作
RDD Transformation on {1,2,3,4}

两个RDD之间的操作, Transformation on {1,2,3} and {3,4,5}

RDD actions on {1,2,3,3}


Transformation on pair RDD {(1,2),(3,4),(3,6)}

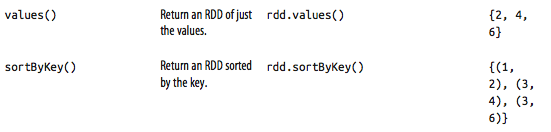
Transform on two pair RDDs {(1,2),(3,4),(3,6)}, {(3,9)}

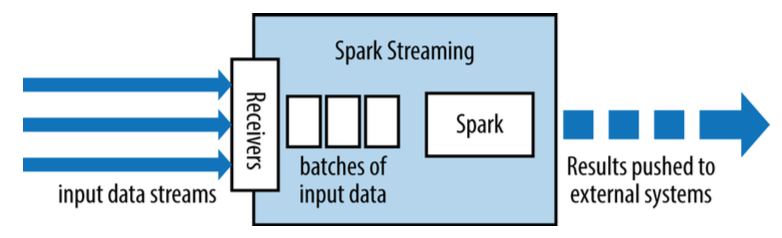
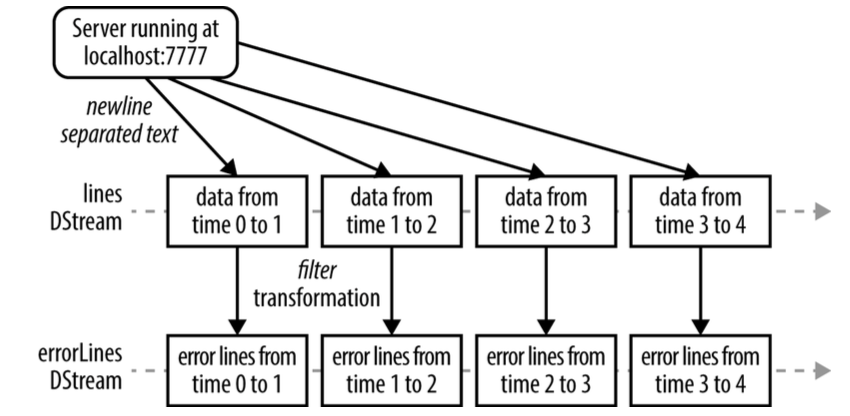
Spark 流 stream
Spark流基于RDD,可以理解对小的时间片段上的RDD操作。

SparkSQL
Spark SQL可以用于操作和查询结构化和半结构化的数据。包括Hive,JSON, CSV等。
# Import Spark SQLfrom pyspark.sql import HiveContext, Row# Or if you can't include the hive requirementsfrom pyspark.sql import SQLContext, Row input = hiveCtx.jsonFile(inputFile)# Register the input schema RDDinput.registerTempTable("tweets")# Select tweets based on the retweetCounttopTweets = hiveCtx.sql("SELECT text, retweetCount FROM tweets ORDER BY retweetCount LIMIT 10")Spark SQL支持JDBC
SparkML
机器学习的基本流程如下:
获得数据
从数据中提取特征
对数据进行有监督的或者无监督的学习,训练机器学习的模型
对模型进行评估,找出最佳模型
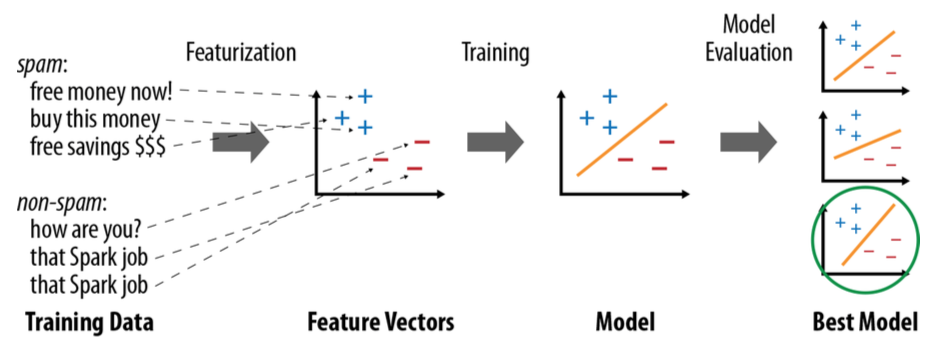
由于Spark的架构特点,Spark支持的机器学习算法是哪些可以并行的算法。
from pyspark.mllib.regression import LabeledPointfrom pyspark.mllib.feature import HashingTFfrom pyspark.mllib.classification import LogisticRegressionWithSGDspam = sc.textFile("spam.txt")normal = sc.textFile("normal.txt")# Create a HashingTF instance to map email text to vectors of 10,000 features.tf = HashingTF(numFeatures = 10000)# Each email is split into words, and each word is mapped to one feature.spamFeatures = spam.map(lambda email: tf.transform(email.split(" ")))normalFeatures = normal.map(lambda email: tf.transform(email.split(" ")))# Create LabeledPoint datasets for positive (spam) and negative (normal) examples.positiveExamples = spamFeatures.map(lambda features: LabeledPoint(1, features))negativeExamples = normalFeatures.map(lambda features: LabeledPoint(0, features))trainingData = positiveExamples.union(negativeExamples)trainingData.cache() # Cache since Logistic Regression is an iterative algorithm.# Run Logistic Regression using the SGD algorithm.model = LogisticRegressionWithSGD.train(trainingData)# Test on a positive example (spam) and a negative one (normal). We first apply# the same HashingTF feature transformation to get vectors, then apply the model.posTest = tf.transform("O M G GET cheap stuff by sending money to ...".split(" "))negTest = tf.transform("Hi Dad, I started studying Spark the other ...".split(" "))print "Prediction for positive test example: %g" % model.predict(posTest)print "Prediction for negative test example: %g" % model.predict(negTest) - Spark Python 快速体验
- spark sql 快速体验调试
- Spark-python-快速开始
- 3 分钟快速体验 Apache Spark SQL
- spark-shell初体验
- Elasticsearch-Spark 体验
- spark streaming初体验
- spark初体验
- spark-sql初体验
- python体验
- 体验 Python
- python spark
- Spark笔记(1)-Spark初体验
- Spark再体验之springboot整合spark
- CDH5 Apache Spark初体验
- spark初体验之wordCount
- rails2.02快速体验
- Linux快速体验
- Letter Combinations of a Phone Number(回溯,dfs)
- ArrayList<Integer>如何转换为int[]数组
- [R语言]蒙特卡罗模拟检验CLRM假定下最小二乘量的BLUE性质
- Spring 中 @Controller 和 @RestController
- 【算法】程序猿不写代码是不对的75
- Spark Python 快速体验
- 12th 【基础】二进制计数
- 走进官方手册系列 --- 详解InnoDB针对不同类型的SQL所采取的锁策略
- 反向传播BP算法
- Mac下写bitcoin执行脚步
- SQL 从一个sql 语句结果中(作为AS一个表) 查询结果 ;按照count排序
- android 生成随机颜色
- MySQL之inner join、left join、right join、limit
- NCBI推出blastp加速服务(Accelerated protein-protein BLAST)


