说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnection还是不够的。
在这里我们可以使用HttpClient这个第三方jar包。
接下来我们使用HttpClient简单的写一个爬去百度的Demo:
- import java.io.FileOutputStream;
- import java.io.InputStream;
- import java.io.OutputStream;
- import org.apache.commons.httpclient.HttpClient;
- import org.apache.commons.httpclient.HttpStatus;
- import org.apache.commons.httpclient.methods.GetMethod;
-
-
-
-
-
- public class Spider {
- private static HttpClient httpClient = new HttpClient();
-
-
-
-
-
-
-
- public static boolean downloadPage(String path) throws Exception {
-
- InputStream input = null;
- OutputStream output = null;
-
- GetMethod getMethod = new GetMethod(path);
-
- int statusCode = httpClient.executeMethod(getMethod);
-
-
- if (statusCode == HttpStatus.SC_OK) {
- input = getMethod.getResponseBodyAsStream();
-
- String filename = path.substring(path.lastIndexOf('/') + 1)
- + ".html";
-
- output = new FileOutputStream(filename);
-
- int tempByte = -1;
- while ((tempByte = input.read()) > 0) {
- output.write(tempByte);
- }
-
- if (input != null) {
- input.close();
- }
-
- if (output != null) {
- output.close();
- }
- return true;
- }
- return false;
- }
- public static void main(String[] args) {
- try {
-
- Spider.downloadPage("<a target=_blank href="http:
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- }
但是这样基本的爬虫是不能满足各色各样的爬虫需求的。
先来介绍宽度优先爬虫。
宽度优先相信大家都不陌生,简单说来可以这样理解宽度优先爬虫。
我们把互联网看作一张超级大的有向图,每一个网页上的链接都是一个有向边,每一个文件或没有链接的纯页面则是图中的终点:

宽度优先爬虫就是这样一个爬虫,爬走在这个有向图上,从根节点开始一层一层往外爬取新的节点的数据。
宽度遍历算法如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col,转到步骤(5),若 V 的所有邻接顶点都已经被访问过,则转到步骤(2)。
按照宽度遍历算法,上图的遍历顺序为:A->B->C->D->E->F->H->G->I,这样一层一层的遍历下去。
而宽度优先爬虫其实爬取的是一系列的种子节点,和图的遍历基本相同。
我们可以把需要爬取页面的URL都放在一个TODO表中,将已经访问的页面放在一个Visited表中:
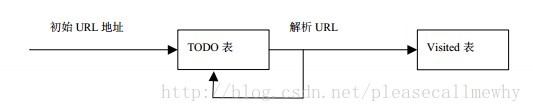
则宽度优先爬虫的基本流程如下:
(1) 把解析出的链接和 Visited 表中的链接进行比较,若 Visited 表中不存在此链接, 表示其未被访问过。
(2) 把链接放入 TODO 表中。
(3) 处理完毕后,从 TODO 表中取得一条链接,直接放入 Visited 表中。
(4) 针对这个链接所表示的网页,继续上述过程。如此循环往复。
下面我们就来一步一步制作一个宽度优先的爬虫。
首先,对于先设计一个数据结构用来存储TODO表, 考虑到需要先进先出所以采用队列,自定义一个Quere类:
- import java.util.LinkedList;
-
-
-
- public class Queue {
-
-
-
- private LinkedList<Object> queue = new LinkedList<Object>();
-
-
-
- public void enQueue(Object t) {
- queue.addLast(t);
- }
-
-
-
- public Object deQueue() {
- return queue.removeFirst();
- }
-
-
-
- public boolean isQueueEmpty() {
- return queue.isEmpty();
- }
-
-
-
- public boolean contians(Object t) {
- return queue.contains(t);
- }
-
-
-
- public boolean empty() {
- return queue.isEmpty();
- }
- }
还需要一个数据结构来记录已经访问过的 URL,即Visited表。
考虑到这个表的作用,每当要访问一个 URL 的时候,首先在这个数据结构中进行查找,如果当前的 URL 已经存在,则丢弃这个URL任务。
这个数据结构需要不重复并且能快速查找,所以选择HashSet来存储。
综上,我们另建一个SpiderQueue类来保存Visited表和TODO表:
- import java.util.HashSet;
- import java.util.Set;
-
-
-
- public class SpiderQueue {
-
-
-
- private static Set<Object> visitedUrl = new HashSet<>();
-
-
-
- public static void addVisitedUrl(String url) {
- visitedUrl.add(url);
- }
-
-
-
- public static void removeVisitedUrl(String url) {
- visitedUrl.remove(url);
- }
-
-
-
- public static int getVisitedUrlNum() {
- return visitedUrl.size();
- }
-
-
-
- private static Queue unVisitedUrl = new Queue();
-
-
-
- public static Queue getUnVisitedUrl() {
- return unVisitedUrl;
- }
-
-
-
- public static Object unVisitedUrlDeQueue() {
- return unVisitedUrl.deQueue();
- }
-
-
-
- public static void addUnvisitedUrl(String url) {
- if (url != null && !url.trim().equals("") && !visitedUrl.contains(url)
- && !unVisitedUrl.contians(url))
- unVisitedUrl.enQueue(url);
- }
-
-
-
- public static boolean unVisitedUrlsEmpty() {
- return unVisitedUrl.empty();
- }
- }
上面是一些自定义类的封装,接下来就是一个定义一个用来下载网页的工具类,我们将其定义为DownTool类:
- package controller;
- import java.io.*;
- import org.apache.commons.httpclient.*;
- import org.apache.commons.httpclient.methods.*;
- import org.apache.commons.httpclient.params.*;
- public class DownTool {
-
-
-
- private String getFileNameByUrl(String url, String contentType) {
-
- url = url.substring(7);
-
- if (contentType.indexOf("html") != -1) {
-
- url = url.replaceAll("[\\?/:*|<>\"]", "_") + ".html";
- } else {
- url = url.replaceAll("[\\?/:*|<>\"]", "_") + "."
- + contentType.substring(contentType.lastIndexOf("/") + 1);
- }
- return url;
- }
-
-
-
- private void saveToLocal(byte[] data, String filePath) {
- try {
- DataOutputStream out = new DataOutputStream(new FileOutputStream(
- new File(filePath)));
- for (int i = 0; i < data.length; i++)
- out.write(data[i]);
- out.flush();
- out.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
-
- public String downloadFile(String url) {
- String filePath = null;
-
- HttpClient httpClient = new HttpClient();
-
- httpClient.getHttpConnectionManager().getParams()
- .setConnectionTimeout(5000);
-
- GetMethod getMethod = new GetMethod(url);
-
- getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
-
- getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
- new DefaultHttpMethodRetryHandler());
-
- try {
- int statusCode = httpClient.executeMethod(getMethod);
-
- if (statusCode != HttpStatus.SC_OK) {
- System.err.println("Method failed: "
- + getMethod.getStatusLine());
- filePath = null;
- }
-
- byte[] responseBody = getMethod.getResponseBody();
-
- filePath = "temp\\"
- + getFileNameByUrl(url,
- getMethod.getResponseHeader("Content-Type")
- .getValue());
- saveToLocal(responseBody, filePath);
- } catch (HttpException e) {
-
- System.out.println("请检查你的http地址是否正确");
- e.printStackTrace();
- } catch (IOException e) {
-
- e.printStackTrace();
- } finally {
-
- getMethod.releaseConnection();
- }
- return filePath;
- }
- }
在这里我们需要一个HtmlParserTool类来处理Html标记:
- package controller;
- import java.util.HashSet;
- import java.util.Set;
- import org.htmlparser.Node;
- import org.htmlparser.NodeFilter;
- import org.htmlparser.Parser;
- import org.htmlparser.filters.NodeClassFilter;
- import org.htmlparser.filters.OrFilter;
- import org.htmlparser.tags.LinkTag;
- import org.htmlparser.util.NodeList;
- import org.htmlparser.util.ParserException;
- import model.LinkFilter;
- public class HtmlParserTool {
-
- public static Set<String> extracLinks(String url, LinkFilter filter) {
- Set<String> links = new HashSet<String>();
- try {
- Parser parser = new Parser(url);
- parser.setEncoding("gb2312");
-
- NodeFilter frameFilter = new NodeFilter() {
- private static final long serialVersionUID = 1L;
- @Override
- public boolean accept(Node node) {
- if (node.getText().startsWith("frame src=")) {
- return true;
- } else {
- return false;
- }
- }
- };
-
- OrFilter linkFilter = new OrFilter(new NodeClassFilter(
- LinkTag.class), frameFilter);
-
- NodeList list = parser.extractAllNodesThatMatch(linkFilter);
- for (int i = 0; i < list.size(); i++) {
- Node tag = list.elementAt(i);
- if (tag instanceof LinkTag)
- {
- LinkTag link = (LinkTag) tag;
- String linkUrl = link.getLink();
- if (filter.accept(linkUrl))
- links.add(linkUrl);
- } else
- {
-
- String frame = tag.getText();
- int start = frame.indexOf("src=");
- frame = frame.substring(start);
- int end = frame.indexOf(" ");
- if (end == -1)
- end = frame.indexOf(">");
- String frameUrl = frame.substring(5, end - 1);
- if (filter.accept(frameUrl))
- links.add(frameUrl);
- }
- }
- } catch (ParserException e) {
- e.printStackTrace();
- }
- return links;
- }
- }
最后我们来写个爬虫类调用前面的封装类和函数:
- package controller;
- import java.util.Set;
- import model.LinkFilter;
- import model.SpiderQueue;
- public class BfsSpider {
-
-
-
- private void initCrawlerWithSeeds(String[] seeds) {
- for (int i = 0; i < seeds.length; i++)
- SpiderQueue.addUnvisitedUrl(seeds[i]);
- }
-
- public void crawling(String[] seeds) {
- LinkFilter filter = new LinkFilter() {
- public boolean accept(String url) {
- if (url.startsWith("<a target=_blank href="http:
- return true;
- else
- return false;
- }
- };
-
- initCrawlerWithSeeds(seeds);
-
- while (!SpiderQueue.unVisitedUrlsEmpty()
- && SpiderQueue.getVisitedUrlNum() <= 1000) {
-
- String visitUrl = (String) SpiderQueue.unVisitedUrlDeQueue();
- if (visitUrl == null)
- continue;
- DownTool downLoader = new DownTool();
-
- downLoader.downloadFile(visitUrl);
-
- SpiderQueue.addVisitedUrl(visitUrl);
-
- Set<String> links = HtmlParserTool.extracLinks(visitUrl, filter);
-
- for (String link : links) {
- SpiderQueue.addUnvisitedUrl(link);
- }
- }
- }
-
- public static void main(String[] args) {
- BfsSpider crawler = new BfsSpider();
- crawler.crawling(new String[] { "<a target=_blank href="http:
- }
- }
运行可以看到,爬虫已经把百度网页下所有的页面都抓取出来了:
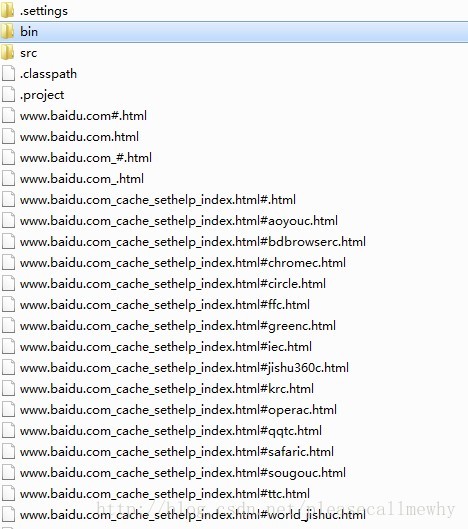
以上就是java使用HttpClient工具包和宽度爬虫进行抓取内容的操作的全部内容。
来源:http://blog.csdn.net/zhihui1017/article/details/50511241


