【简记】Operating System—— file system in Linux
来源:互联网 发布:改变图片尺寸 mac 编辑:程序博客网 时间:2024/04/30 10:58
This memo is based on the course of Dr.Li with Operating System as the reference book.
本章内容:
- Linux文件结构
- Linux文件系统概述
一 、Linux文件结构
Linux采用的是树型结构。最上层是根目录,其他的所有目录都是从根目录出发而生成的。微软的DOS和windows也是采用树型结构,但是在DOS和 windows中这样的树型结构的根是磁盘分区的盘符,有几个分区就有几个树型结构,他们之间的关系是并列的。但是在linux中,无论操作系统管理几个磁盘分区,这样的目录树只有一个。从结构上讲,各个磁盘分区上的树型目录不一定是并列的。
/是文件系统中必须存在的挂载点,而其他的/boot、/home、/opt等等这些都不是必须独立挂载设备的挂载点。
那么为什么又有很多文章推荐/home多少多少,/boot多少多少呢?这是为了怕一旦有误操作,或者分区表损坏之类的情况发生。尽可能的把鸡蛋多分散到几个篮子里去:一个物理设备的多个分区挂载到多个挂载点上。
二 、linux文件系统
文件系统指文件存在的物理空间,linux系统中每个分区都是一个文件系统,都有自己的目录层次结构。linux会将这些分属不同分区的、单独的文件系统按一定的方式形成一个系统的总的目录层次结构。一个操作系统的运行离不开对文件的操作,因此必然要拥有并维护自己的文件系统。
每次安装系统的时候我们都会进行分区,Linux下磁盘分区和目录的关系如下:
- 任何一个分区都必须挂载到某个目录上。
- 目录是逻辑上的区分。分区是物理上的区分。
- 磁盘Linux分区都必须挂载到目录树中的某个具体的目录上才能进行读写操作。
- 根目录是所有Linux的文件和目录所在的地方,需要挂载上一个磁盘分区。
Q:如何查看分区和目录及使用情况?
- fdisk:查看硬盘分区表
- df:查看分区使用情况
- du: 查看文件占用空间情况
Q: 为什么要分区,如何分区?
- 可以把不同资料,分别放入不同分区中管理,降低风险。
- 大硬盘搜索范围大,效率低
- 磁盘配合只能对分区做设定

磁盘(硬盘)、分区、物理卷【物理部分】
卷组【中间部分】
逻辑卷、文件系统【虚拟化后可控制部分】
每个逻辑卷可被格式化成文件系统,然后挂在到虚拟目录中的某个特定位置。
不同类型的硬盘和分区的设备文件命名都有统一的规则,具体表述形式如下:
硬盘:对于IDE接口的硬盘设备,表示为“hdX”形式的文件名,对于SATA或SCSI接口的硬盘设备,则表示为“sdX”形式的文件名,其中“X”可以为a、b、c、d等字母序号。例如,将系统中的第1个IDE设备表示为“hda”,将第2个SATA设备表示为“sdb”。
分区:表示分区时,以硬盘设备的文件名作为基础,在后边添加该分区对应的数字序号即可。例如,第1个IDE硬盘中的第1个分区表示为“hda1”、第2个分区表示为“hda2”,第2个SATA硬盘中的第3个分区表示为“sdb3”,第4个分区表示为“sdb4”等。
三、文件系统层次分析
由上而下主要分为用户层、VFS层、文件系统层、缓存层、块设备层、磁盘驱动层、磁盘物理层
用户层:最上面用户层就是我们日常使用的各种程序,需要的接口主要是文件的创建、删除、打开、关闭、写、读等。
VFS层:我们知道Linux分为用户态和内核态,用户态请求硬件资源需要调用System Call通过内核态去实现。用户的这些文件相关操作都有对应的System Call函数接口,接口调用 VFS对应的函数。
文件系统层:不同的文件系统实现了VFS的这些函数,通过指针注册到VFS里面。所以,用户的操作通过VFS转到各种文件系统。文件系统把文件读写命令转化为对磁盘LBA的操作,起了一个翻译和磁盘管理的作用。
缓存层:文件系统底下有缓存,Page Cache,加速性能。对磁盘LBA的读写数据缓存到这里。
块设备层:块设备接口Block Device是用来访问磁盘LBA的层级,读写命令组合之后插入到命令队列,磁盘的驱动从队列读命令执行。linux设计了电梯算法等对很多LBA的读写进行优化排序,尽量把连续地址放在一起。
磁盘驱动层:磁盘的驱动程序把对LBA的读写命令转化为各自的协议,比如变成ATA命令,SCSI命令,或者是自己硬件可以识别的自定义命令,发送给磁盘控制器。Host Based SSD甚至在块设备层和磁盘驱动层实现了FTL,变成对Flash芯片的操作。
磁盘物理层:读写物理数据到磁盘介质。 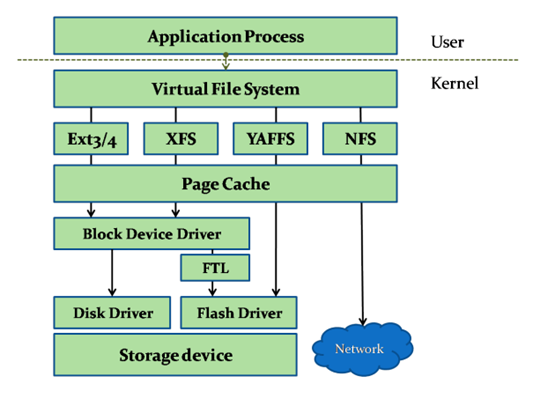
四、文件系统结构与工作原理(主要以ext4为例)
我们都知道,windows文件系统主要有fat、ntfs等,而linux文件系统则种类多的很,主要有VFS做了一个软件抽象层,向上提供文件操作接口,向下提供标准接口供不同文件系统对接,下面主要就以EXT4文件系统为例,讲解下文件系统结构与工作原理: 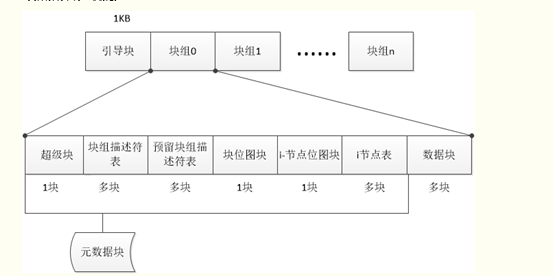
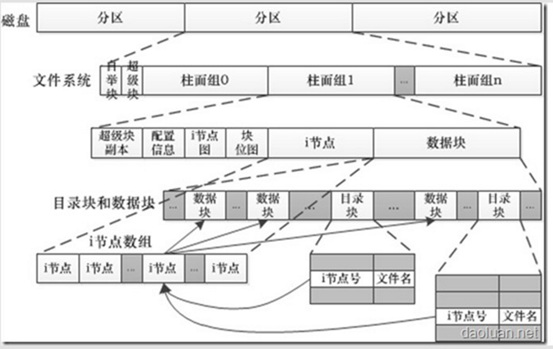
上面两个图大体呈现了ext4文件系统的结构,从中也相信能够初步的领悟到文件系统读写的逻辑过程。下面对上图里边的构成元素做个简单的讲解:
引导块:为磁盘分区的第一个块,记录文件系统分区的一些信息,引导加载当前分区的程序和数据被保存在这个块中。一般占用2kB。
超级块:
超级块用于存储文件系统全局的配置参数(譬如:块大小,总的块数和inode数)和动态信息(譬如:当前空闲块数和inode数),其处于文件系统开始位置的1k处,所占大小为1k。为了系统的健壮性,最初每个块组都有超级块和组描述符表(以下将用GDT)的一个拷贝,但是当文件系统很大时,这样浪费了很多块(尤其是GDT占用的块多),后来采用了一种稀疏的方式来存储这些拷贝,只有块组号是3, 5 ,7的幂的块组(譬如说1,3,5,7,9,25,49…)才备份这个拷贝。通常情况下,只有主拷贝(第0块块组)的超级块信息被文件系统使用,其它拷贝只有在主拷贝被破坏的情况下才使用。
块组描述符:
GDT用于存储块组描述符,其占用一个或者多个数据块,具体取决于文件系统的大小。它主要包含块位图,inode位图和inode表位置,当前空闲块数,inode数以及使用的目录数(用于平衡各个块组目录数),具体定义可以参见ext3_fs.h文件中struct ext3_group_desc。每个块组都对应这样一个描述符,目前该结构占用32个字节,因此对于块大小为4k的文件系统来说,每个块可以存储128个块组描述符。由于GDT对于定位文件系统的元数据非常重要,因此和超级块一样,也对其进行了备份。GDT在每个块组(如果有备份)中内容都是一样的,其所占块数也是相同的。从上面的介绍可以看出块组中的元数据譬如块位图,inode位图,inode表其位置不是固定的,当然默认情况下,文件系统在创建时其位置在每个块组中都是一样的,如图2所示(假设按照稀疏方式存储,且n不是3,5,7的幂)
块组:
每个块组包含一个块位图块,一个 inode 位图块,一个或多个块用于描述 inode 表和用于存储文件数据的数据块,除此之外,还有可能包含超级块和所有块组描述符表(取决于块组号和文件系统创建时使用的参数)。下面将对这些元数据作一些简要介绍。
块位图:
块位图用于描述该块组所管理的块的分配状态。如果某个块对应的位未置位,那么代表该块未分配,可以用于存储数据;否则,代表该块已经用于存储数据或者该块不能够使用(譬如该块物理上不存在)。由于块位图仅占一个块,因此这也就决定了块组的大小。
Inode位图:
Inode位图用于描述该块组所管理的inode的分配状态。我们知道inode是用于描述文件的元数据,每个inode对应文件系统中唯一的一个号,如果inode位图中相应位置位,那么代表该inode已经分配出去;否则可以使用。由于其仅占用一个块,因此这也限制了一个块组中所能够使用的最大inode数量。
Inode表:
Inode表用于存储inode信息。它占用一个或多个块(为了有效的利用空间,多个inode存储在一个块中),其大小取决于文件系统创建时的参数,由于inode位图的限制,决定了其最大所占用的空间。
以上这几个构成元素所处的磁盘块成为文件系统的元数据块,剩余的部分则用来存储真正的文件内容,称为数据块,而数据块其实也包含数据和目录。
了解了文件系统的结构后,接下来我们来看看操作系统是如何读取一个文件的: 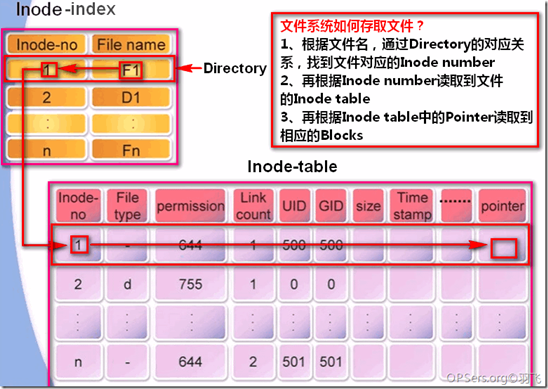
大体过程如下:
1、根据文件所在目录的inode信息,找到目录文件对应数据块
2、根据文件名从数据块中找到对应的inode节点信息
3、从文件inode节点信息中找到文件内容所在数据块块号
4、读取数据块内容
到这里,相信很多人会有一个疑问,我们知道一个文件只有一个Inode节点来存放它的属性信息,那么你可能会想如果一个大文件,那它的block一定是多个的,且可能不连续的,那么inode怎么来表示呢,下面的图告诉你答案: 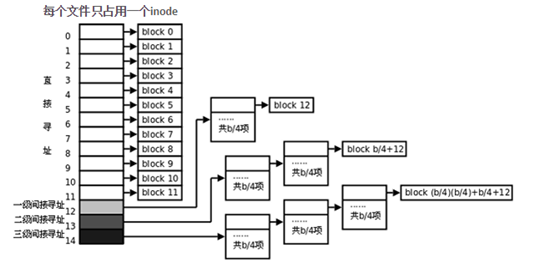
也就是说,如果文件内容太大,对应数据块数量过多,inode节点本身提供的存储空间不够,会使用其他的间接数据块来存储数据块位置信息,最多可以有三级寻址结构。
http://www.cnblogs.com/itech/archive/2012/05/15/2502284.html
一、inode是什么?
理解inode,要从文件储存说起。
文件储存在硬盘上,硬盘的最小存储单位叫做”扇区”(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个”块”(block)。这种由多个扇区组成的”块”,是文件存取的最小单位。”块”的大小,最常见的是4KB,即连续八个 sector组成一个 block。
文件数据都储存在”块”中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为”索引节点”。
五、文件的拷贝、剪切的底层过程
下面来结合stat命令动手操作一下,便知真相:
1)拷贝文件:创建一个新的inode节点,并且拷贝数据块内容 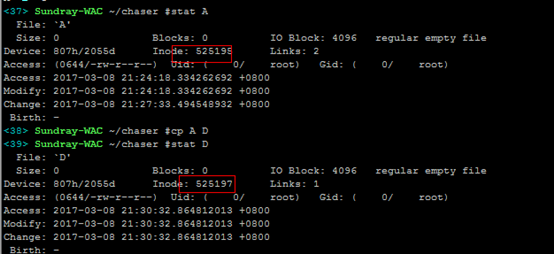
2)移动文件或者改名:同个分区里边mv,inode节点不变,只是更新目录文件对应数据块里边的文件名和inode对应关系;跨分区mv,则跟拷贝一个道理,需要创建新的inode,因为inode节点不同分区是不能共享的。 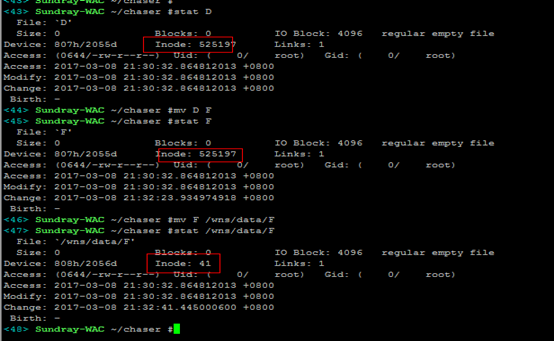
六、软连接、硬链接
软链接和硬链接是我们常见的两种概念:
硬链接:是给文件一个副本,同时建立两者之间的连接关系。修改其中一个,与其连接的文件同时被修改。如果删除其中任意一个其余的文件将不受影响。
ln命令可以创建硬链接:ln 源文件 目标文件
创建硬链接,并不会新建inode节点,只是links加1,还有在目录文件对应数据块上增加一条文件名和inode对应关系记录;只有将硬链接和原文件都删除之后,文件才会真正删除,即links为0才真正删除。 
软连接:也叫符号连接,他只是对源文件在新的位置建立一个“快捷(借用一下wondows常用词)”,所以,当源文件删除时,符号连接的文件将成为无源之水->仅仅剩下个文件名了,当然删除这个连接,也不会影响到源文件,但对连接文件的使用、引用都是直接调用源文件的。
创建软连接会创建一个新的inode节点,其对应数据块内容存储所链接的文件名信息,这样原文件即便删除了,重新建立一个同名的文件,软连接依然能够生效。 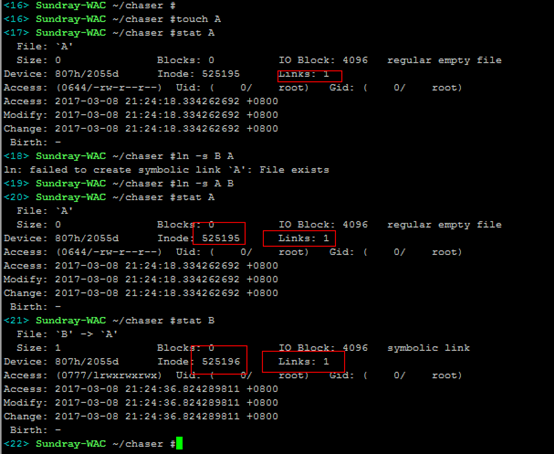
这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode”链接数”不会因此发生变化。
ln -s命令可以创建软链接。
ln -s 源文文件或目录 目标文件或目录
- 【简记】Operating System—— file system in Linux
- 【简记】Operating System—— distributed system
- 【简记】Operating System——process synchronization in Java
- 【简记】Operating System—— memory management in Linux(暂)
- 【简记】Operating System——Linux schedule()(暂)
- 【简记】Operating System——Overview
- 【简记】Operating System——Process
- 【简记】Operating System——Thread
- 【简记】Operating System——CPU Scheduling
- 【简记】Operating System——process synchronization
- 【简记】Operating System——Dead Lock
- 【简记】Operating System—— virtual memory
- 【简记】Operating System—— I/O
- 【简记】Operating System——Atomic Transaction Overview
- 【简记】Operating System—— memory management(part 1)
- Describe the process of opening a file in Linux system, what actions the operating system w
- 【简记】Operating System—— memory management(分页,分段,页表大小计算)
- 【简记】Operating System—— distributed coordination(2PC 3PC)
- Eclipse全文搜索,很实用
- 电动汽车控制策略
- K-近邻算法
- java冒泡排序的优化
- 捡拾日记:令牌机制
- 【简记】Operating System—— file system in Linux
- PHP连接MySQL数据库的三种方式(mysql、mysqli、pdo)
- error LNK2019: 无法解析的外部符号
- Android中com.android.camera.action.CROP(图片裁剪)所有属性
- NP完全问题 课后习题
- SOCK_STREAM和SOCK_DGRAM两种类型的区别
- MySql 里的IFNULL、NULLIF和ISNULL用法
- UE4材质编辑器
- 【HTTP】Fiddler(一)


