卷积神经网络caffe
来源:互联网 发布:c语言闰年流程图 编辑:程序博客网 时间:2024/06/03 19:18
卷积神经网络caffe
卷积神经网络是层级结构,但层的功能和形式做了变化,层包含:
- 数据输入层 input layer
- 卷积计算层 conv layer
- Relu激励层 Relu layer
- 池化层 pooling layer
- 全连接层 FC layer

一、输入层 input layer
1.1 图像预处理
- 去均值: 把输入数据各个维度都中心化到0
- 归一化: 幅度归一化到同样的范围
- PCA/白化: 白化是对数据每个特征轴上的幅度归一化
二、卷积计算层 conv layer
卷积层 实现了图片的局部关联,通过这种局部关联,可以有效地降低参数的数目。
- 局部关联,每个神经元看作一个filter
- 窗口滑动,filter对局部数据进行计算
包含三个值:
- 深度 depth
- 步长 stride
- 填充值 zero-padding
卷积计算层和神经网络层其实类似,但是卷积计算层假设的是每个神经元连接数据窗 的权重是固定的。其中卷积:
- 固定每个神经元连接权重,可以看作模板 每个神经元只关注一个特性
- 需要估算的权重个数减少
- 一组固定的权重和不同窗口内数据做内积:卷积
如下图所示,:

三、激励层 ReLU
将卷积层的输出结果做非线性映射,包含以下几种分类:
- Sigmoid
- tanh
- ReLu
- Leaky ReLU
- ELU
- Maxout

3.1 Sigmoid
sigmoid非线性函数的数学公式是,它输入实数值并将其“挤压”到0到1范围内。更具体地说,很大的负数变成0,很大的正数变成1。
但是它有明显的缺点:
- 函数饱和使梯度消失
- 函数输出0不是中心
3.1 tanh
tanh将实数值压缩到[-1,1]之间,和sigmoid一样存在饱和问题,但它输出是以0为中心的。
表达式为:

relu 比 sigmoid等好在:后者容易引起梯度消失, 导致训练难以收敛
3.3 ReLU
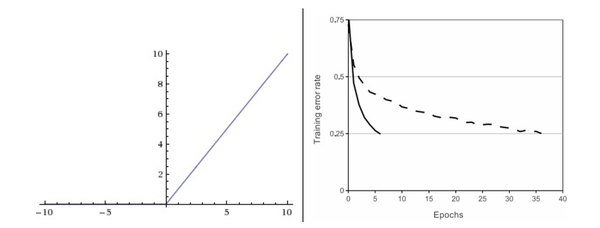
左边是ReLU(校正线性单元:Rectified Linear Unit)激活函数,当x=0时函数值为0;当x>1时,斜率为1。
其函数公式为:f(x) = max(0,x),函数一个关于0的阈值函数。
优点:简单,不存在指数运算等耗时操作;ReLU对随机梯度下降的收敛有巨大的加速作用。
3.4 Leaky Relu
函数公式为:f(x) = max(0.01x, x),也是一个关于0的阈值函数,当x<0时,取值0.01x
3.5 ELU
指数线性单元ELU

3.6 Maxout
即所有神经元通路中wx+b最大的那个值。
![]()
![]()
四、池化层 Pooling layer
- 夹在连续的卷积层中间
- 压缩数据和参数的量,减小过拟合
- 其计算方式分为Max Pooling和average pooling两种
五、全连接层
FC layer
- 两层之间所有神经元都有权重连接
- 通常全连接层在卷积神经网络尾部
Dropout
为了防止过拟合,需要降维,别让神经元记太多特殊的内容,保持泛化能力,降低误判率。
六、fine tunning
使用已用于其他目标,预训练好的模型的权重或者部分权重,作为初始值开始训练
- 原因
从头训练卷积神经网络容易出问题
fine-tunning可以很快收敛到一个较理想的状态
服用相同层的权重,新定义层取随机权重初始值,并且调大新定义层的学习率,调小复用层的学习率
优先学习权放在新加层
- 每一层都有控制学习率的参数: blobs_lr
- 一般会把前面层学习率调低,最后新加层调高
- 你甚至可以freeze前面的层次不动
- 一般fine-tuning的前期loss下降非常快,中间有个瓶颈期,要有耐心
在solver处调整学习率
- 调低solver处的学习率(1/10,1/100)
- 记住存储一下中间结果,以免出现意外
阅读全文
0 0
- 卷积神经网络caffe
- caffe卷积神经网络框架安装
- 卷积神经网络与caffe的卷积层、池化层
- caffe 卷积神经网络源码一些模糊点整理
- 神经网络BP推导及caffe中卷积层的实现
- Caffe下卷积神经网络中的一些特殊层
- Caffe下卷积神经网络中的一些特殊层
- 卷积神经网络与caffe Convolution层及参数设置
- caffe 进行卷积神经网络训练的命令参数解析
- caffe中使用draw_net.py绘制卷积神经网络结构图
- 卷积神经网络
- 卷积神经网络
- 卷积神经网络
- 卷积神经网络
- 卷积神经网络
- 卷积神经网络
- 卷积神经网络
- 卷积神经网络
- 葵花宝典 十一 过滤器 监听器
- rmq(区间最值)
- Web Service简洁版调用公开手机api
- 导出PDF合同例子
- Maven 本地仓库明明有jar包,pom文件还是报错解决办法
- 卷积神经网络caffe
- Python模块
- android.mk编译静态.jar
- ES6“箭头”用法总结
- leetcode 629. K Inverse Pairs Array
- http.sys远程代码注入漏洞
- 将页面input中的value值打印出来
- 【问题处理】Unable to cast object of type 'System.DBNull' to type 'System.String'.
- leetcode 64. Minimum Path Sum


