django学习
来源:互联网 发布:手机淘宝号怎么登录 编辑:程序博客网 时间:2024/06/05 06:04
1、下载、安装
2、django-admin startproject mysite 创建项目
3、django-admin startapp blog 创建应用
3、 修改sittings.py
3.1 INSTALLED_APPS中添加'blog'
3.2修改时区 TIME_ZONE = 'Asia/Shanghai'
3.3 修改语言 LANGUAGE_CODE = 'zh-hans' //django在1.9 版本后不支持zh-cn
4、修改urls.py
from blog import views
url(r'^blog/index/$',views.index) //新版本django只支持先倒入,后引用
5、处理 视图blog/views.py
from django.http import HttpResponse
def index(req):
return HttpResponse('<h1>hello world</h1>');
6、启动服务器
python manager.py runserver
//访问链接 127.0.0.1:8000/blog/index
二、加载模版文件
1、在blog文件夹下新建一个文件夹,templates文件夹,然后在里面新建一个html名字为index.html
2、在blog/views/index.py加入代码如下:
from django.shortcuts import render;
#request为http请求对象
def index(request):
return render(request,'index.html',{})
三、views向模板传递变量
views.py/index方法
{{ title }}
{{ user }}
{{ book_list}}
模板渲染,如果对象中的属性、方法等重复,有优先级,
1、字典
2、属性
3、方法
四、模板
http://blog.csdn.net/zhangxinrun/article/details/8095118/
1、if标签
{% if user %}
注意点:不能再if中同时使用 and和or 、不能再if中使用()
2、for标签
2.1 循环列表
{% if book_list %}
2.2.1循环出key
{% if user %}
2.2.2循环出key、value
2.2.3 带序号循环
#forloop_counter从1开始,forloop_counter0从0开始,
#forloop_revcounter,forloop_revcounter0反向
2.2.4 for...empty
{% for k,v in user2.items %}
2.2.5
用在嵌套的 for 循环中,
获取上一层 for 循环的 forloop
3.1include:在模版html中包含另一个模版{% include 'moban.html'%},变量不需要传递
3.2模版继承:
第一步,先创建基础模版base.html
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN">
<html lang="en">
<head>
<title>{% block title %}{% endblock %}</title>
</head>
<body>
<h1>My helpful timestamp site</h1>
{% block content %} {% endblock %}
{% block footer %} <hr>
<p>Thanks for visiting my site.</p>
{% endblock %}
</body>
</html>
第二步,让其他模版页面继承此模版,index.html
{% extends "base.html" %}
{% block title %}The current time {% endblock %}
{% block content %}
<p>It is now {{ current_date }}.</p>
{% endblock %}
注意:模板一般放在app下的templates中,Django会自动去这个文件夹中找。但 假如我们每个app的templates中都有一个 index.html,当我们在views.py中使用的时候,直接写一个 render(request, 'index.html'),Django 能不能找到当前 app 的 templates 文件夹中的 index.html 文件夹呢?(答案是不一定能,有可能找错)
def add(request, a, b): c = int(a) + int(b) return HttpResponse(str(c)) # urls.py urlpatterns = patterns('', url(r'^add/(\d+)/(\d+)/$', 'app.views.add', name='add'), ) # template html {% url 'add' 4 5 %}这样网址上就会显示出:/add/4/5/ 这个网址,假如我们以后修改 urls.py 中的
r'^add/(\d+)/(\d+)/$'这一部分,改成另的,比如:
r'^jiafa/(\d+)/(\d+)/$'{% url 'some-url-name' arg arg2 as the_url %}<a href="{{ the_url }}">链接到:{{ the_url }}</a>获取当前用户:
{{ request.user }}如果登陆就显示内容,不登陆就不显示内容:
{% if request.user.is_authenticated %} {{ request.user.username }},您好!{% else %} 请登陆,这里放登陆链接{% endif %}获取当前网址:
{{ request.path }}获取当前 GET 参数:
{{ request.GET.urlencode }}合并到一起用的一个例子:
<a href="{{ request.path }}?{{ request.GET.urlencode }}&delete=1">当前网址加参数 delete</a>比如我们可以判断 delete 参数是不是 1 来删除当前的页面内容。
csrf与from
<form method='post'>{% csrf_token %}{{ form }}<input type="submit" value="提交"></form>五、定义模型
1、settings.py中设置数据库mysql
DATABASES = {
2、编辑blog/models.py
from django.db import models
def __unicode__(self): #打印article对象时候会调用此方法
return self.title;
3、启动服务器
python manage.py makemigrations blog #生产sql文件
python manage.py migrate #执行生产的sql文件创建表
【问题1】:ImportError: No module named 'MySQLdb'
django python3.0 安装mysql报错
解决办法:安装pymsql
【问题2】:,再次运行 python manage.py migrate报错“mysqlclient 1.3.3 or newer is required”
下载最新的mysqlclient,一般在linux下是好了
【问题3】:如果在windows上出现需要vc ++ 10...
解决办法:去此网站 http://www.lfd.uci.edu/~gohlke/pythonlibs/找到对应的扩展
4、queryset操作数据库
new = Article()
4.2添加数据
new = Article(title='heihie')
new.save()
4.3添加数据
Article.objects.create(title='hoho')
4.4 查找不存在添加
Person.objects.get_or_create(name="WZT", age=23) //这种方法是防止重复很好的方法,但是速度要相对慢些,返回一个元组,第一个为Person对象,第二个为True或False, 新建时返回的是True, 已经存在时返回False.
4.5 更新不存在添加:update_or_create()
5、修改数据
article = Article.objects.get(id=1);
article.title = '666'
article.save()
批量修改
Person.objects.filter(name__contains="abc").update(name='xxx') # 名称中包含 "abc"的人 都改成 xxx6、删除数据
article = Article.objects.get(id=1);
article.delete()
Person.objects.all().delete() # 删除所有 Person 记录7 、查询数据
Person.objects.count()
Person.objects.all()
打印queryset 操作语句的sql: print str(Author.objects.all().query),在语句后架上query,
所以,当不知道Django做了什么时,你可以把执行的 SQL 打出来看看,也可以借助 django-debug-toolbar 等工具在页面上看到访问当前页面执行了哪些SQL,耗时等。还有一种办法就是修改一下 log 的设置。
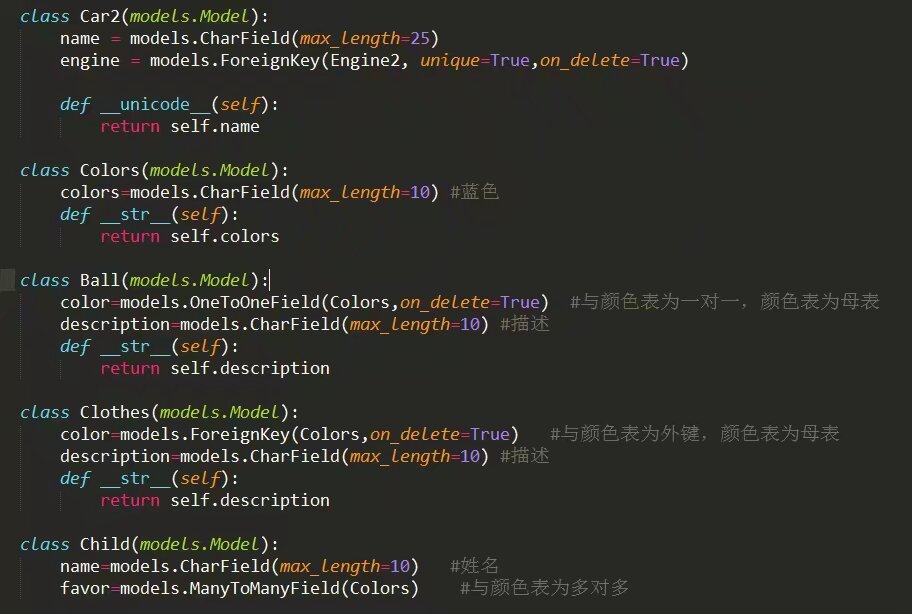
8.1 一对一:
model中
8.1.1差
正查(通过当前对象信息查询关联对象信息):
ball = Ball.objects.get(description='红球')
clolors = ball.color.colors #查询红球对应的颜色,一种球一个颜色,一对一
反查(通过已知关联对象的属性查询当前对象信息):
clolors = color.colors
8.1.2 添加数据
color_obj = Colors.objects.create(colors='黑色')#先创建黑色
#增添数据的三种写法:
color_obj=models.Colors.objects.get(colors="黑") #.get()等同于.filter().first()
再添几种方式:
8.1.4 删除数据
#删除一条
models.Ball.objects.get(description="灰球").delete() #对象和QuerySet都有方法delete()
#删除多条
Colors.objects.filter(colors='红色').delete() #删除所有colors为红色的数据
Colors.objects.all().delete() #清空一张表
8.2 一对多(外键):
8.2.1 查询数据
#外键表联合查询:
备注:通过QuerySet的.values()方法,将QuerySet转化为ValuesQuerySet
print(models.Clothes.objects.filter(color=models.Colors.objects.get(colors="红")).values('color__colors','description')) #获取子表的description字段,和母表的colors字段,获取母表字段写法: 子表外键字段名__母表字段名--适用于values()或filter()
#增添子表数据,形式与一对一一致
#颜色为红的服装,description都更新为大美女
models.Clothes.objects.get(description="灰裙子").delete() #对象和QuerySet都有方法
delete()models.Colors.objects.filter(colors="灰").delete()
8.3 多对多:
8.3.1 查询
#多对多子表查询母表,查找小明喜欢哪些颜色--返回:[<Colors: 红>, <Colors: 黄>, <Colors: 蓝>]
8.3.2 增与改
#添加子表关联关系
8.3.3 删除多对多表关系
#删除子表与母表关联关系
8.3.4删除多对多表数据
#删除子表数据
删除母表数据:
默认情况下,如此例中,删除“红”色,那么子表与颜色表是一对一或外键关系的,子表对应数据会自动删除,如:红球,小虎哥
与颜色表是多对多关系的话,不会自动删除喜欢红色的人,而是去掉红色已选
class Clothes(models.Model):
8.4 choice
#choices相当于实现一个简化版的外键,外键的选项不能动态更新,如可选项目较少,可以采用
8.5 django查询条件补充
条件选取querySet的时候,filter表示=,exclude表示!=
extra 实现 别名,条件,排序等
extra 中可实现别名,条件,排序等,后面两个用 filter, exclude 一般都能实现,排序用 order_by 也能实现。我们主要看一下别名这个
比如 Author 中有 name, Tag 中有 name 我们想执行
SELECT name AS tag_name FROM blog_tag;
这样的语句,就可以用 select 来实现,如下:
In [44]: tags = Tag.objects.all().extra(select={'tag_name': 'name'})
In [45]: tags[0].name
Out[45]: u'Django'
In [46]: tags[0].tag_name
Out[46]: u'Django'
我们发现 name 和 tag_name 都可以使用,确认一下执行的 SQL
In [47]: Tag.objects.all().extra(select={'tag_name': 'name'}).query.__str__()
Out[47]: u'SELECT (name) AS "tag_name", "blog_tag"."id", "blog_tag"."name" FROM "blog_tag"'
我们发现查询的时候弄了两次 (name) AS "tag_name" 和 "blog_tag"."name"
如果我们只想其中一个能用,可以用 defer 排除掉原来的 name (后面有讲)
In [49]: Tag.objects.all().extra(select={'tag_name': 'name'}).defer('name').query.__str__()
Out[49]: u'SELECT (name) AS "tag_name", "blog_tag"."id" FROM "blog_tag"'
也许你会说为什么要改个名称,最常见的需求就是数据转变成 list,然后可视化等,我们在下面一个里面讲。
annotate 聚合 计数,求和,平均数等
计数
我们来计算一下每个作者的文章数(我们每个作者都导入的Article的篇数一样,所以下面的每个都一样)
In [66]: from django.db.models import Count
In [66]: Article.objects.all().values('author_id').annotate(count=Count('author')).values('author_id', 'count')
Out[66]: <QuerySet [{'count': 20, 'author_id': 1}, {'count': 20, 'author_id': 2}, {'count': 20, 'author_id': 4}]>
这是怎么工作的呢?
In [67]: Article.objects.all().values('author_id').annotate(count=Count('author')).values('author_id', 'count').query.__str__()
Out[67]: u'SELECT "blog_article"."author_id", COUNT("blog_article"."author_id") AS "count" FROM "blog_article" GROUP BY "blog_article"."author_id"'
简化一下SQL: SELECT author_id, COUNT(author_id) AS count FROM blog_article GROUP BY author_id
我们也可以获取作者的名称 及 作者的文章数
In [72]: Article.objects.all().values('author__name').annotate(count=Count('author')).values('author__name', 'count')
Out[72]: <QuerySet [{'count': 20, 'author__name': u'WeizhongTu'}, {'count': 20, 'author__name': u'twz915'}, {'count': 20, 'author__name': u'xiaoming'}]>
这时候会查询两张表,细心的同学会发现,因为作者名称中 blog_author 这张表中,author_id 在 blog_article 表中本身就有的
求和 与 平均值
求一个作者的所有文章的得分(score)平均值
In [6]: from django.db.models import Avg
In [7]: Article.objects.values('author_id').annotate(avg_score=Avg('score')).values('author_id', 'avg_score')
Out[7]: <QuerySet [{'author_id': 1, 'avg_score': 86.05}, {'author_id': 2, 'avg_score': 83.75}, {'author_id': 5, 'avg_score': 85.65}]>
执行的SQL
In [8]: Article.objects.values('author_id').annotate(avg_score=Avg('score')).values('author_id', 'avg_score').qu
...: ery.__str__()
Out[8]: u'SELECT "blog_article"."author_id", AVG("blog_article"."score") AS "avg_score" FROM "blog_article" GROUP BY "blog_article"."author_id"'
求一个作者所有文章的总分
In [12]: from django.db.models import Sum
In [13]: Article.objects.values('author__name').annotate(sum_score=Sum('score')).values('author__name', 'sum_score')
Out[13]: <QuerySet [{'author__name': u'WeizhongTu', 'sum_score': 1721}, {'author__name': u'twz915', 'sum_score': 1675}, {'author__name': u'zhen', 'sum_score': 1713}]>
执行的SQL
In [14]: Article.objects.values('author__name').annotate(sum_score=Sum('score')).values('author__name', 'sum_sco
...: re').query.__str__()
Out[14]: u'SELECT "blog_author"."name", SUM("blog_article"."score") AS "sum_score" FROM "blog_article" INNER JOIN "blog_author" ON ("blog_article"."author_id" = "blog_author"."id") GROUP BY "blog_author"."name"'
配置打印sql到日志
开始之前我们修改一个 settings.py 让Django打印出在数据库中执行的语句
settings.py 尾部加上
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console': { 'class': 'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'level': 'DEBUG' if DEBUG else 'INFO', }, },}这样当 DEBUG 为 True 的时候,我们可以看出 django 执行了什么 SQL 语句
tu@pro ~/zqxt $ python manage.py shell
In [1]: from blog.models import *
In [2]: Author.objects.all()
Out[2]: (0.001) SELECT "blog_author"."id", "blog_author"."name", "blog_author"."qq", "blog_author"."addr", "blog_author"."email" FROM "blog_author" LIMIT 21; args=()
<QuerySet [<Author: WeizhongTu>, <Author: twz915>, <Author: dachui>, <Author: zhe>, <Author: zhen>]>
标记背景为 黄色的部分就是打出的 log。
select_related 优化一对一,多对一查询
tu@pro ~/zqxt $ python manage.py shell
In [1]: from blog.models import *
In [2]: Author.objects.all()
Out[2]: (0.001) SELECT "blog_author"."id", "blog_author"."name", "blog_author"."qq", "blog_author"."addr", "blog_author"."email" FROM "blog_author" LIMIT 21; args=()
<QuerySet [<Author: WeizhongTu>, <Author: twz915>, <Author: dachui>, <Author: zhe>, <Author: zhen>]>
标记背景为 黄色的部分就是打出的 log。
假如,我们取出10篇Django相关的文章,并需要用到作者的姓名
In [13]: articles = Article.objects.all()[:10]
In [14]: a1 = articles[0] # 取第一篇
(0.000) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."author_id", "blog_article"."content", "blog_article"."score" FROM "blog_article" LIMIT 1; args=()
In [15]: a1.title
Out[15]: u'Django \u6559\u7a0b_1'
In [16]: a1.author_id
Out[16]: 5
In [17]: a1.author.name # 再次查询了数据库,注意!!!
(0.000) SELECT "blog_author"."id", "blog_author"."name", "blog_author"."qq", "blog_author"."addr", "blog_author"."email" FROM "blog_author" WHERE "blog_author"."id" = 5; args=(5,)
Out[17]: u'zhen'
这样的话我们遍历查询结果的时候就会查询很多次数据库,能不能只查询一次,把作者的信息也查出来呢?
当然可以,这时就用到 select_related,我们的数据库设计的是一篇文章只能有一个作者,一个作者可以有多篇文章。
现在要查询文章的时候连同作者一起查询出来,“文章”和“作者”的关系就是多对一,换句说说,就是一篇文章只可能有一个作者。
In [18]: articles = Article.objects.all().select_related('author')[:10]
In [19]: a1 = articles[0] # 取第一篇
(0.000) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."author_id", "blog_article"."content", "blog_article"."score", "blog_author"."id", "blog_author"."name", "blog_author"."qq", "blog_author"."addr", "blog_author"."email" FROM "blog_article" INNER JOIN "blog_author" ON ("blog_article"."author_id" = "blog_author"."id") LIMIT 1; args=()
In [20]: a1.title
Out[20]: u'Django \u6559\u7a0b_1'
In [21]: a1.author.name # 嘻嘻,没有再次查询数据库!!
Out[21]: u'zhen'
prefetch_related 优化一对多,多对多查询
和 select_related 功能类似,但是实现不同。
select_related 是使用 SQL JOIN 一次性取出相关的内容。
prefetch_related 用于 一对多,多对多 的情况,这时 select_related 用不了,因为当前一条有好几条与之相关的内容。
prefetch_related是通过再执行一条额外的SQL语句,然后用 Python 把两次SQL查询的内容关联(joining)到一起
我们来看个例子,查询文章的同时,查询文章对应的标签。“文章”与“标签”是多对多的关系。
In [24]: articles = Article.objects.all().prefetch_related('tags')[:10]
In [25]: articles
Out[25]: (0.000) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."author_id", "blog_article"."content", "blog_article"."score" FROM "blog_article" LIMIT 10; args=()
(0.001) SELECT ("blog_article_tags"."article_id") AS "_prefetch_related_val_article_id", "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10); args=(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
<QuerySet [<Article: Django 教程_1>, <Article: Django 教程_2>, <Article: Django 教程_3>, <Article: Django 教程_4>, <Article: Django 教程_5>, <Article: Django 教程_6>, <Article: Django 教程_7>, <Article: Django 教程_8>, <Article: Django 教程_9>, <Article: Django 教程_10>]>
遍历查询的结果:
不用 prefetch_related 时
In [9]: articles = Article.objects.all()[:3]
In [10]: for a in articles:
...: print a.title, a.tags.all()
...:
(0.000) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."author_id", "blog_article"."content", "blog_article"."score" FROM "blog_article" LIMIT 3; args=()
(0.000) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" = 1 LIMIT 21; args=(1,)
Django 教程_1 <QuerySet [<Tag: Django>]>
(0.000) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" = 2 LIMIT 21; args=(2,)
Django 教程_2 <QuerySet [<Tag: Django>]>
(0.000) SELECT "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" = 3 LIMIT 21; args=(3,)
Django 教程_3 <QuerySet [<Tag: Django>]>
用 prefetch_related 我们看一下是什么样子
In [11]: articles = Article.objects.all().prefetch_related('tags')[:3]
In [12]: for a in articles:
...: print a.title, a.tags.all()
...:
(0.000) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."author_id", "blog_article"."content", "blog_article"."score" FROM "blog_article" LIMIT 3; args=()
(0.000) SELECT ("blog_article_tags"."article_id") AS "_prefetch_related_val_article_id", "blog_tag"."id", "blog_tag"."name" FROM "blog_tag" INNER JOIN "blog_article_tags" ON ("blog_tag"."id" = "blog_article_tags"."tag_id") WHERE "blog_article_tags"."article_id" IN (1, 2, 3); args=(1, 2, 3)
Django 教程_1 <QuerySet [<Tag: Django>]>
Django 教程_2 <QuerySet [<Tag: Django>]>
Django 教程_3 <QuerySet [<Tag: Django>]>
我们可以看到第二条 SQL 语句,一次性查出了所有相关的内容。
defer 排除不需要的字段
在复杂的情况下,表中可能有些字段内容非常多,取出来转化成 Python 对象会占用大量的资源。
这时候可以用 defer 来排除这些字段,比如我们在文章列表页,只需要文章的标题和作者,没有必要把文章的内容也获取出来(因为会转换成python对象,浪费内存)
In [13]: Article.objects.all()
Out[13]: (0.000) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."author_id", "blog_article"."content","blog_article"."score" FROM "blog_article" LIMIT 21; args=()
<QuerySet [<Article: Django 教程_1>, <Article: Django 教程_2>, <Article: Django 教程_3>, <Article: Django 教程_4>, <Article: Django 教程_5>, <Article: Django 教程_6>, <Article: Django 教程_7>, <Article: Django 教程_8>, <Article: Django 教程_9>, <Article: Django 教程_10>, <Article: Django 教程_11>, <Article: Django 教程_12>, <Article: Django 教程_13>, <Article: Django 教程_14>, <Article: Django 教程_15>, <Article: Django 教程_16>, <Article: Django 教程_17>, <Article: Django 教程_18>, <Article: Django 教程_19>, <Article: Django 教程_20>, '...(remaining elements truncated)...']>
In [14]: Article.objects.all().defer('content')
Out[14]: (0.000) SELECT "blog_article"."id", "blog_article"."title", "blog_article"."author_id", "blog_article"."score" FROM "blog_article" LIMIT 21; args=() # 注意这里没有查 content 字段了
<QuerySet [<Article: Django 教程_1>, <Article: Django 教程_2>, <Article: Django 教程_3>, <Article: Django 教程_4>, <Article: Django 教程_5>, <Article: Django 教程_6>, <Article: Django 教程_7>, <Article: Django 教程_8>, <Article: Django 教程_9>, <Article: Django 教程_10>, <Article: Django 教程_11>, <Article: Django 教程_12>, <Article: Django 教程_13>, <Article: Django 教程_14>, <Article: Django 教程_15>, <Article: Django 教程_16>, <Article: Django 教程_17>, <Article: Django 教程_18>, <Article: Django 教程_19>, <Article: Django 教程_20>, '...(remaining elements truncated)...']>
only 仅选择需要的字段
和 defer 相反,only 用于取出需要的字段,假如我们只需要查出 作者的名称
In [15]: Author.objects.all().only('name')
Out[15]: (0.000) SELECT "blog_author"."id", "blog_author"."name" FROM "blog_author" LIMIT 21; args=()
<QuerySet [<Author: WeizhongTu>, <Author: twz915>, <Author: dachui>, <Author: zhe>, <Author: zhen>]>
细心的同学会发现,我们让查 name , id 也查了,这个 id 是 主键,能不能没有这个 id 呢?
试一下原生的 SQL 查询
In [26]: authors = Author.objects.raw('select name from blog_author limit 1')
In [27]: author = authors[0]
(0.000) select name from blog_author limit 1; args=()
---------------------------------------------------------------------------
InvalidQuery Traceback (most recent call last)
<ipython-input-27-51c5f914fff2> in <module>()
----> 1author = authors[0]
/usr/local/lib/python2.7/site-packages/django/db/models/query.pyc in __getitem__(self, k)
1275
1276 def __getitem__(self, k):
-> 1277 return list(self)[k]
1278
1279 @property
/usr/local/lib/python2.7/site-packages/django/db/models/query.pyc in __iter__(self)
1250 if skip:
1251 if self.model._meta.pk.attname in skip:
-> 1252 raise InvalidQuery('Raw query must include the primary key')
1253 model_cls = self.model
1254 fields =[self.model_fields.get(c)for c in self.columns]
InvalidQuery: Raw query must include the primary key
报错信息说 非法查询,原生SQL查询必须包含 主键!
再试试直接执行 SQL
tu@pro ~/zqxt $ python manage.py dbshell
SQLite version 3.14.0 2016-07-26 15:17:14
Enter ".help" for usage hints.
sqlite> select name from blog_author limit 1;
WeizhongTu <--- 成功!!!
虽然直接执行SQL语句可以这样,但是 django queryset 不允许这样做,一般也不需要关心,反正 only 一定会取出你指定了的字段。
自定义聚合功能
我们前面看到了 django.db.models 中有 Count, Avg, Sum 等,但是有一些没有的,比如 GROUP_CONCAT,它用来聚合时将符合某分组条件(group by)的不同的值,连到一起,作为整体返回。
我们来演示一下,如果实现 GROUP_CONCAT 功能。
新建一个文件 比如 my_aggregate.py
from django.db.models import Aggregate, CharFieldclass GroupConcat(Aggregate): function = 'GROUP_CONCAT' template = '%(function)s(%(distinct)s%(expressions)s%(ordering)s%(separator)s)' def __init__(self, expression, distinct=False, ordering=None, separator=',', **extra): super(GroupConcat, self).__init__( expression, distinct='DISTINCT ' if distinct else '', ordering=' ORDER BY %s' % ordering if ordering is not None else '', separator=' SEPARATOR "%s"' % separator, output_field=CharField(), **extra )代码来自:http://stackoverflow.com/a/40478702/2714931(我根据一个回复改写的增强版本)
使用时先引入 GroupConcat 这个类,比如聚合后的错误日志记录有这些字段 time, level, info
我们想把 level, info 一样的 聚到到一起,按时间和发生次数倒序排列,并含有每次日志发生的时间。
ErrorLogModel.objects.values('level', 'info').annotate( count=Count(1), time=GroupConcat('time', ordering='time DESC', separator=' | ')).order_by('-time', '-count')
自定义field
这个ListField继承自 TextField,代码如下:
from django.db import modelsimport astclass ListField(models.TextField): __metaclass__ = models.SubfieldBase description = "Stores a python list" def __init__(self, *args, **kwargs): super(ListField, self).__init__(*args, **kwargs) def to_python(self, value): if not value: value = [] if isinstance(value, list): return value return ast.literal_eval(value) def get_prep_value(self, value): if value is None: return value return unicode(value) # use str(value) in Python 3 def value_to_string(self, obj): value = self._get_val_from_obj(obj) return self.get_db_prep_value(value)使用它很简单,首先导入 ListField,像自带的 Field 一样使用:
class Article(models.Model): labels = ListField()在终端上尝试(运行 python manage.py shell 进入):
>>> from app.models import Article>>> d = Article()>>> d.labels[]>>> d.labels = ["Python", "Django"]>>> d.labels["Python", "Django"]
9、admin使用
9.1
python manage.py createsuperuser
127.0.0.1:8000/admin #进行登陆
9.2
到blog下admin.py中注册在model/py中新添加的User:
admin.site.register(User) #后台就可以看到User模块
9.3
user添加后显示的列表显示的都是object,在User类中添加方法:
def __unicode__(self):
return self.name
此时列表显示名字
10、表单
10.1关于csrf
1、 settings.py中MIDDLEWARE中的csrf注释掉
2、在模板中
{% csrf_token %}10.2
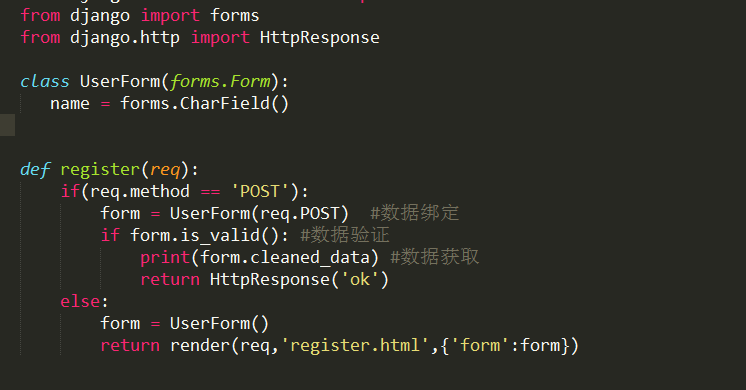
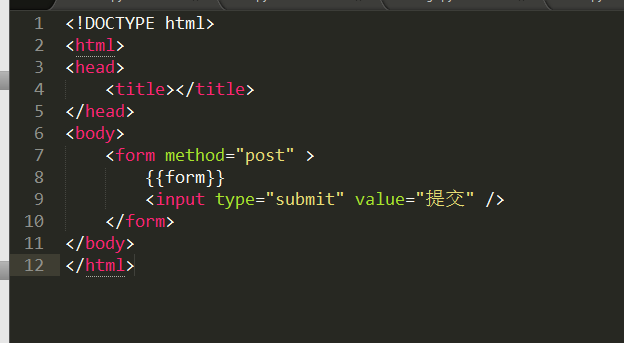
11、文件上传
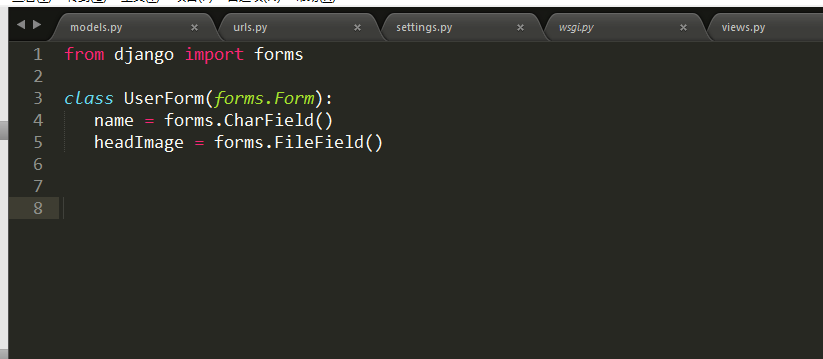
11.1 一般form上传
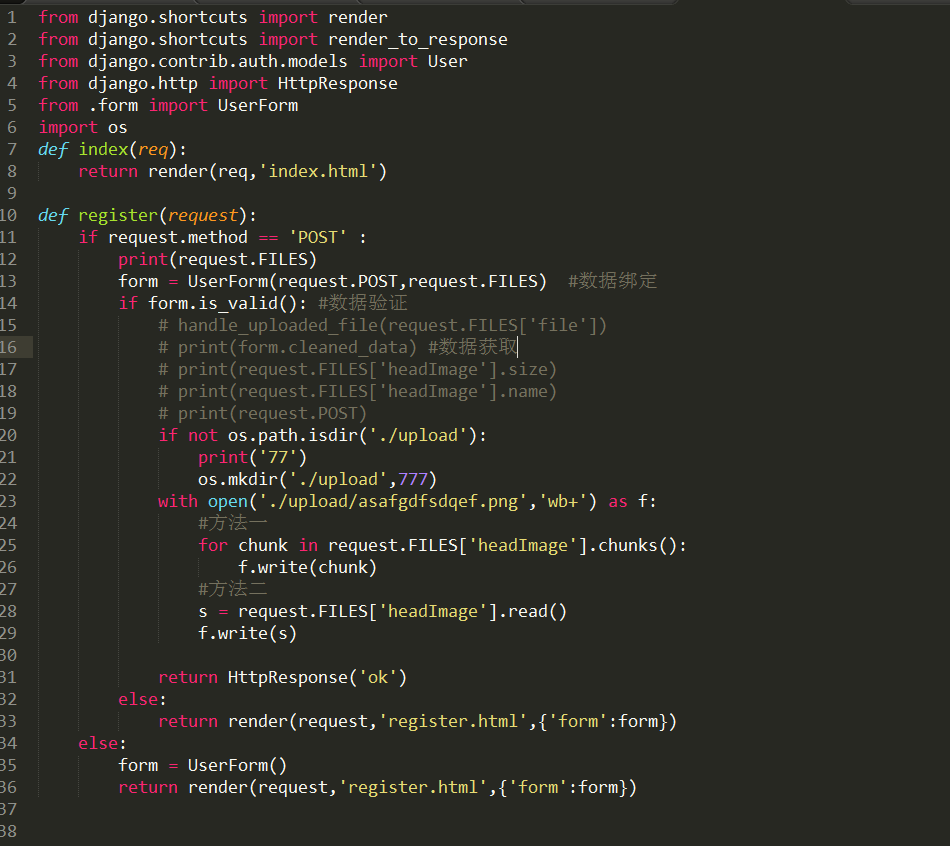
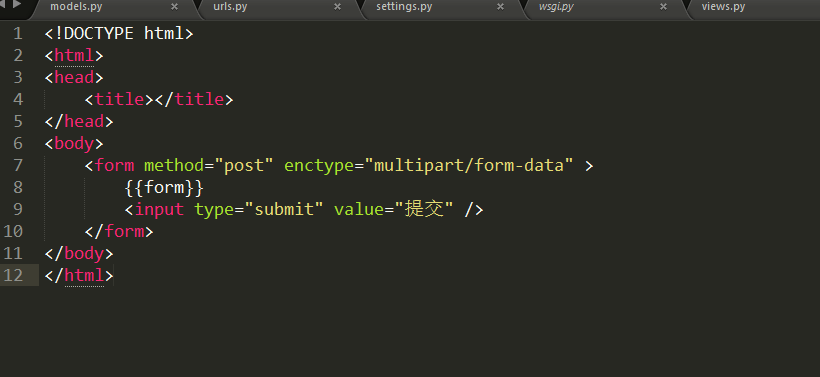
11.2 后台admin 的model上传
model.py中
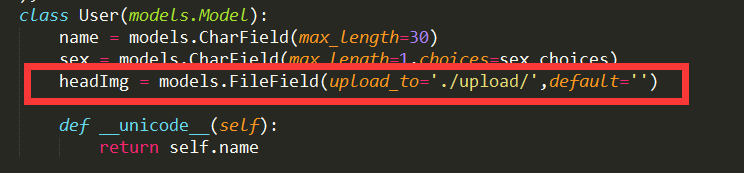
同步数据库字段
urls.py中
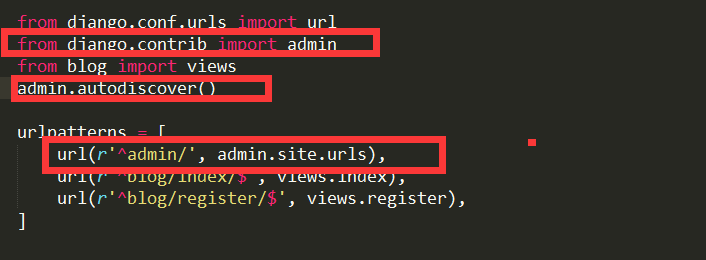
后台直接上传
12、会话cookie
12.1 设置cookie
12.2 获取cookie
request.COOKIE.get('username','')
13.3 删除cookie
response = HttpResponse()
response.delete_cookie('username') //key path domain
13、会话session
13.1 设置session
request.session['username'] = username
13.2 获取session
request.session.get('username','defaultval')
13.2 删除session
del request.session['username']
14、接受参数
def test(request):
if request.method == 'POST':
a = request.GET.get('a','defaultVal')
else:
a = request.POST.get('a','defaultVal')
15、auth系统使用
- django学习
- 学习django
- Django 学习
- Django学习
- Django 学习
- django学习
- Django 学习
- django学习
- Django学习
- Django学习
- django学习
- Django学习
- Django学习
- django学习
- django学习
- Django学习
- Django 学习
- Django学习
- 图片平移缩放
- SlidingMenu
- mac上运行报错:syntax error near unexpected token `('
- linux让Apache支持.htaccess伪静态文件时遇到的坑
- 前端面试知识整理-2017年7月10日
- django学习
- IDC:函数列表
- PHP使用glob方法遍历文件夹下所有文件
- cmake构建时指定编译器架构(x86 or x64)
- 修改secureCRT的配置方案
- Spring : constructor-arg property 注入
- Android-------自定义圆形图片实现多点触控
- Hadoop大数据解决方案
- vim中Tab键设置为4个空格


