ElasticSearch之ANSJ分词器搭建搭建,解决ansj停止词bug (qq交流群 189040279)
来源:互联网 发布:淘宝联盟怎么分享 编辑:程序博客网 时间:2024/05/21 19:50
Caused by: FetchPhaseExecutionException[Fetch Failed [Failed to highlight field [contents]]]; nested: StringIndexOutOfBoundsException[String index out of range: -5];
at org.elasticsearch.search.highlight.FastVectorHighlighter.highlight(FastVectorHighlighter.java:169)
at org.elasticsearch.search.highlight.HighlightPhase.hitExecute(HighlightPhase.java:140)
at org.elasticsearch.search.fetch.FetchPhase.execute(FetchPhase.java:188)
at org.elasticsearch.search.SearchService.executeFetchPhase(SearchService.java:605)
at org.elasticsearch.search.action.SearchServiceTransportAction$FetchByIdTransportHandler.messageReceived(SearchServiceTransportAction.java:408)
at org.elasticsearch.search.action.SearchServiceTransportAction$FetchByIdTransportHandler.messageReceived(SearchServiceTransportAction.java:405)
at org.elasticsearch.transport.TransportRequestHandler.messageReceived(TransportRequestHandler.java:33)
at org.elasticsearch.transport.RequestHandlerRegistry.processMessageReceived(RequestHandlerRegistry.java:77)
at org.elasticsearch.transport.TransportService$4.doRun(TransportService.java:378)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:37)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.StringIndexOutOfBoundsException: String index out of range: -5
at java.lang.String.substring(String.java:1967)
at org.apache.lucene.search.vectorhighlight.BaseFragmentsBuilder.makeFragment(BaseFragmentsBuilder.java:179)
at org.elasticsearch.search.highlight.vectorhighlight.SimpleFragmentsBuilder.makeFragment(SimpleFragmentsBuilder.java:43)
at org.apache.lucene.search.vectorhighlight.BaseFragmentsBuilder.createFragments(BaseFragmentsBuilder.java:144)
at org.apache.lucene.search.vectorhighlight.FastVectorHighlighter.getBestFragments(FastVectorHighlighter.java:186)
at org.elasticsearch.search.highlight.FastVectorHighlighter.highlight(FastVectorHighlighter.java:146)
... 12 more
/** Inverts one field for one document; first is true
* if this is the first time we are seeing this field
* name in this document. */
public void invert(IndexableField field, boolean first) throws IOException, AbortingException {
if (first) {
// First time we're seeing this field (indexed) in
// this document:
invertState.reset();
}
IndexableFieldType fieldType = field.fieldType();
IndexOptions indexOptions = fieldType.indexOptions();
fieldInfo.setIndexOptions(indexOptions);
if (fieldType.omitNorms()) {
fieldInfo.setOmitsNorms();
}
final boolean analyzed = fieldType.tokenized() && docState.analyzer != null;
// only bother checking offsets if something will consume them.
// TODO: after we fix analyzers, also check if termVectorOffsets will be indexed.
final boolean checkOffsets = indexOptions == IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS;
/*
* To assist people in tracking down problems in analysis components, we wish to write the field name to the infostream
* when we fail. We expect some caller to eventually deal with the real exception, so we don't want any 'catch' clauses,
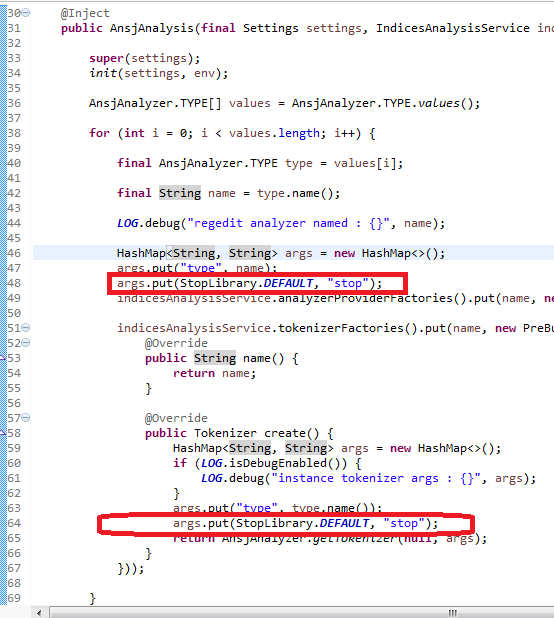
* but rather a finally that takes note of the problem.
*/
boolean succeededInProcessingField = false;
try (TokenStream stream = tokenStream = field.tokenStream(docState.analyzer, tokenStream)) {
// reset the TokenStream to the first token
stream.reset();
invertState.setAttributeSource(stream);
termsHashPerField.start(field, first);
while (stream.incrementToken()) {
int posIncr = invertState.posIncrAttribute.getPositionIncrement();
invertState.position += posIncr;
if (invertState.position < invertState.lastPosition) {
if (posIncr == 0) {
throw new IllegalArgumentException("first position increment must be > 0 (got 0) for field '" + field.name() + "'");
} else {
throw new IllegalArgumentException("position increments (and gaps) must be >= 0 (got " + posIncr + ") for field '" + field.name() + "'");
}
} else if (invertState.position > IndexWriter.MAX_POSITION) {
throw new IllegalArgumentException("position " + invertState.position + " is too large for field '" + field.name() + "': max allowed position is " + IndexWriter.MAX_POSITION);
}
invertState.lastPosition = invertState.position;
if (posIncr == 0) {
invertState.numOverlap++;
}
if (checkOffsets) {
int startOffset = invertState.offset + invertState.offsetAttribute.startOffset();
int endOffset = invertState.offset + invertState.offsetAttribute.endOffset();
if (startOffset < invertState.lastStartOffset || endOffset < startOffset) {
throw new IllegalArgumentException("startOffset must be non-negative, and endOffset must be >= startOffset, and offsets must not go backwards "
+ "startOffset=" + startOffset + ",endOffset=" + endOffset + ",lastStartOffset=" + invertState.lastStartOffset + " for field '" + field.name() + "'");
}
invertState.lastStartOffset = startOffset;
}
invertState.length++;
if (invertState.length < 0) {
throw new IllegalArgumentException("too many tokens in field '" + field.name() + "'");
}
//System.out.println(" term=" + invertState.termAttribute);
// If we hit an exception in here, we abort
// all buffered documents since the last
// flush, on the likelihood that the
// internal state of the terms hash is now
// corrupt and should not be flushed to a
// new segment:
try {
termsHashPerField.add();
} catch (MaxBytesLengthExceededException e) {
byte[] prefix = new byte[30];
BytesRef bigTerm = invertState.termAttribute.getBytesRef();
System.arraycopy(bigTerm.bytes, bigTerm.offset, prefix, 0, 30);
String msg = "Document contains at least one immense term in field=\"" + fieldInfo.name + "\" (whose UTF8 encoding is longer than the max length " + DocumentsWriterPerThread.MAX_TERM_LENGTH_UTF8 + "), all of which were skipped. Please correct the analyzer to not produce such terms. The prefix of the first immense term is: '" + Arrays.toString(prefix) + "...', original message: " + e.getMessage();
if (docState.infoStream.isEnabled("IW")) {
docState.infoStream.message("IW", "ERROR: " + msg);
}
// Document will be deleted above:
throw new IllegalArgumentException(msg, e);
} catch (Throwable th) {
throw AbortingException.wrap(th);
}
}
stream.end();
// TODO: maybe add some safety? then again, it's already checked
// when we come back around to the field...
//add by jkuang
String value = field.stringValue();
invertState.offset += value==null?0:value.length();
invertState.position += invertState.posIncrAttribute.getPositionIncrement();
/* if there is an exception coming through, we won't set this to true here:*/
succeededInProcessingField = true;
} finally {
if (!succeededInProcessingField && docState.infoStream.isEnabled("DW")) {
docState.infoStream.message("DW", "An exception was thrown while processing field " + fieldInfo.name);
}
}
if (analyzed) {
invertState.position += docState.analyzer.getPositionIncrementGap(fieldInfo.name);
invertState.offset += docState.analyzer.getOffsetGap(fieldInfo.name);
}
invertState.boost *= field.boost();
}
}
public WeightedFragInfo( int startOffset, int endOffset, List<SubInfo> subInfos, float totalBoost ){
this.startOffset = startOffset;
this.endOffset = endOffset;
this.totalBoost = totalBoost;
this.subInfos = subInfos;
Collections.sort(this.subInfos, new Comparator<SubInfo>() {
@Override
public int compare(SubInfo o1, SubInfo o2) {
if(o1.getTermsOffsets().size()==0){
return -1;
}else if(o2.getTermsOffsets().size()==0){
return 1;
}else{
return o1.getTermsOffsets().get(0).getStartOffset()-o2.getTermsOffsets().get(0).getStartOffset();
}
}
});
for (SubInfo info:subInfos) {
for (Toffs ot:info.getTermsOffsets()) {
if(this.startOffset>ot.getStartOffset()){
this.startOffset = ot.getStartOffset();
}
if(this.endOffset <ot.getEndOffset()){
this.endOffset = ot.getEndOffset();
}
}
}
}
public List<SubInfo> getSubInfos(){
return subInfos;
}
public float getTotalBoost(){
return totalBoost;
}
public int getStartOffset(){
return startOffset;
}
public int getEndOffset(){
return endOffset;
}
@Override
public String toString(){
StringBuilder sb = new StringBuilder();
sb.append( "subInfos=(" );
for( SubInfo si : subInfos )
sb.append( si.toString() );
sb.append( ")/" ).append( totalBoost ).append( '(' ).append( startOffset ).append( ',' ).append( endOffset ).append( ')' );
return sb.toString();
}
/**
* Represents the list of term offsets for some text
*/
public static class SubInfo {
private final String text; // unnecessary member, just exists for debugging purpose
private final List<Toffs> termsOffsets; // usually termsOffsets.size() == 1,
// but if position-gap > 1 and slop > 0 then size() could be greater than 1
private final int seqnum;
private final float boost; // used for scoring split WeightedPhraseInfos.
public SubInfo( String text, List<Toffs> termsOffsets, int seqnum, float boost ){
this.text = text;
this.termsOffsets = termsOffsets;
this.seqnum = seqnum;
this.boost = boost;
Collections.sort( this.termsOffsets,new Comparator<Toffs>() {
@Override
public int compare(Toffs o1, Toffs o2) {
// TODO Auto-generated method stub
return o1.getStartOffset()-o2.getStartOffset();
}
});
}
public List<Toffs> getTermsOffsets(){
return termsOffsets;
}
public int getSeqnum(){
return seqnum;
}
public String getText(){
return text;
}
public float getBoost(){
return boost;
}
@Override
public String toString(){
StringBuilder sb = new StringBuilder();
sb.append( text ).append( '(' );
for( Toffs to : termsOffsets )
sb.append( to.toString() );
sb.append( ')' );
return sb.toString();
}
}
}
}
protected List<WeightedFragInfo> discreteMultiValueHighlighting(List<WeightedFragInfo> fragInfos, Field[] fields) {
Map<String, List<WeightedFragInfo>> fieldNameToFragInfos = new HashMap<>();
for (Field field : fields) {
fieldNameToFragInfos.put(field.name(), new ArrayList<WeightedFragInfo>());
}
fragInfos: for (WeightedFragInfo fragInfo : fragInfos) {
int fieldStart;
int fieldEnd = 0;
for (Field field : fields) {
if (field.stringValue().isEmpty()) {
fieldEnd++;
continue;
}
fieldStart = fieldEnd;
fieldEnd += field.stringValue().length() + 1; // + 1 for going to next field with same name.
if (fragInfo.getStartOffset() >= fieldStart && fragInfo.getEndOffset() >= fieldStart &&
fragInfo.getStartOffset() <= fieldEnd && fragInfo.getEndOffset() <= fieldEnd) {
fieldNameToFragInfos.get(field.name()).add(fragInfo);
continue fragInfos;
}
if (fragInfo.getSubInfos().isEmpty()) {
continue fragInfos;
}
Toffs firstToffs = fragInfo.getSubInfos().get(0).getTermsOffsets().get(0);
if (fragInfo.getStartOffset() >= fieldEnd || firstToffs.getStartOffset() >= fieldEnd) {
continue;
}
int fragStart = fieldStart;
if (fragInfo.getStartOffset() > fieldStart && fragInfo.getStartOffset() < fieldEnd) {
fragStart = fragInfo.getStartOffset();
}
int fragEnd = fieldEnd;
if (fragInfo.getEndOffset() > fieldStart && fragInfo.getEndOffset() < fieldEnd) {
fragEnd = fragInfo.getEndOffset();
}
List<SubInfo> subInfos = new ArrayList<>();
Iterator<SubInfo> subInfoIterator = fragInfo.getSubInfos().iterator();
float boost = 0.0f; // The boost of the new info will be the sum of the boosts of its SubInfos
while (subInfoIterator.hasNext()) {
SubInfo subInfo = subInfoIterator.next();
List<Toffs> toffsList = new ArrayList<>();
Iterator<Toffs> toffsIterator = subInfo.getTermsOffsets().iterator();
while (toffsIterator.hasNext()) {
Toffs toffs = toffsIterator.next();
if (toffs.getStartOffset() >= fieldEnd) {
// We've gone past this value so its not worth iterating any more.
break;
}
boolean startsAfterField = toffs.getStartOffset() >= fieldStart;
boolean endsBeforeField = toffs.getEndOffset() < fieldEnd;
if (startsAfterField && endsBeforeField) {
// The Toff is entirely within this value.
toffsList.add(toffs);
toffsIterator.remove();
} else if (startsAfterField) {
/*
* The Toffs starts within this value but ends after this value
* so we clamp the returned Toffs to this value and leave the
* Toffs in the iterator for the next value of this field.
*/
toffsList.add(new Toffs(toffs.getStartOffset(), fieldEnd - 1));
} else if (endsBeforeField) {
/*
* The Toffs starts before this value but ends in this value
* which means we're really continuing from where we left off
* above. Since we use the remainder of the offset we can remove
* it from the iterator.
*/
toffsList.add(new Toffs(fieldStart, toffs.getEndOffset()));
toffsIterator.remove();
} else {
/*
* The Toffs spans the whole value so we clamp on both sides.
* This is basically a combination of both arms of the loop
* above.
*/
toffsList.add(new Toffs(fieldStart, fieldEnd - 1));
}
}
if (!toffsList.isEmpty()) {
subInfos.add(new SubInfo(subInfo.getText(), toffsList, subInfo.getSeqnum(), subInfo.getBoost()));
boost += subInfo.getBoost();
}
if (subInfo.getTermsOffsets().isEmpty()) {
subInfoIterator.remove();
}
}
WeightedFragInfo weightedFragInfo = new WeightedFragInfo(fragStart, fragEnd, subInfos, boost);
fieldNameToFragInfos.get(field.name()).add(weightedFragInfo);
}
}
List<WeightedFragInfo> result = new ArrayList<>();
for (List<WeightedFragInfo> weightedFragInfos : fieldNameToFragInfos.values()) {
result.addAll(weightedFragInfos);
}
Collections.sort(result, new Comparator<WeightedFragInfo>() {
@Override
public int compare(FieldFragList.WeightedFragInfo info1, FieldFragList.WeightedFragInfo info2) {
return info1.getStartOffset() - info2.getStartOffset();
}
});
return result;
}
- ElasticSearch之ANSJ分词器搭建搭建,解决ansj停止词bug (qq交流群 189040279)
- ElasticSearch之分词器进阶-修复ansj分词器bug
- ansj 分词
- ansj 分词
- Ansj分词
- ansj分词
- elasticsearch中ANSJ中文分词处理
- Java中文分词器Ansj
- ansj分词器的配置
- 跟益达学Solr5之使用Ansj分词器
- 自然语言处理之分词器ansj和hanlp介绍
- 跟益达学Solr5之使用Ansj分词器
- 开源 Java 中文分词器 Ansj
- Lucene5.5.0 使用ansj分词器
- Java中文分词器Ansj的使用
- Solr整合Ansj中文分词器
- Ansj中文分词说明
- ansj分词使用
- 普元 EOS Platform 7.5 default、governor和workspace部署到同一个tomcat上,如何修改governor和workspace的http访问端口,以便和访问def
- 代码检查工具
- vCenter Converter standalone 转换物理机到虚拟机问题
- bootstrap-table数据循环以及分页
- HDU-1864-最大报销额
- ElasticSearch之ANSJ分词器搭建搭建,解决ansj停止词bug (qq交流群 189040279)
- VMRC开启拷贝粘贴
- 《Linux内核设计与实现》读书笔记(七)- 中断处理
- 利用GlobalMapper实现DGSinfo野外地质填图系统的图像快速配准与集成
- 476. Number Complement
- 移动web开发框架研究
- const char* 转成 CString类型
- eclipse并行和vSphere虚拟机设置问题(一)
- HTML Responsive Web Page


