CBOW
来源:互联网 发布:象牙社区一样的软件 编辑:程序博客网 时间:2024/04/29 06:16
本文简述了以下内容:
神经概率语言模型NPLM,训练语言模型并同时得到词表示
word2vec:CBOW / Skip-gram,直接以得到词表示为目标的模型
(一)原始CBOW(Continuous Bag-of-Words)模型
(二)原始Skip-gram模型
(三)word analogy
神经概率语言模型NPLM
上篇文简单整理了一下不同视角下的词表示模型。近年来,word embedding可以说已经成为了各种神经网络方法(CNN、RNN乃至各种网络结构,深层也好不深也罢)处理NLP任务的标配。word embedding(词嵌入;词向量)是指基于神经网络来得到词向量的模型(如CBOW、Skip-gram等,几乎无一例外都是浅层的)所train出来的词的向量表示,这种向量表示被称为是分布式表示distributed representation,大概就是说单独看其中一维的话没什么含义,但是组合到一起的vector就表达了这个词的语义信息(粒度上看的话,不止词,字、句子乃至篇章都可以有分布式表示;而且,例如网络节点、知识图谱中的三元组等都可以有自己的embedding,各种“xx2vec”层出不穷)。这种基于神经网络的模型又被称作是基于预测(predict)的模型,超参数往往要多于基于计数(count)的模型,因此灵活性要强一些,超参数起到的作用可能并不逊于模型本身。尽管有一批paper去证明了这类神经网络得到词表示模型的本质其实就是矩阵分解,但这并不妨碍它们的广泛应用。
下面就简要介绍利用神经网络来得到词表示的非常早期的工作——神经概率语言模型(NPLM, Neural Probabilistic Language Model),通过训练语言模型,同时得到词表示。
语言模型是指一个词串
因此要想计算出这个概率,那就要计算出
count()是指词串在语料中出现的次数。暂且抛开数据稀疏(如果分子为零那么概率为零,这个零合理吗?如果分母为零,又怎么办?)不谈,如果词串的长度很长的话,这个计算会非常费时。n-gram模型是一种近似策略,作了一个
神经概率语言模型NPLM延续了n-gram的假设:认为目标词
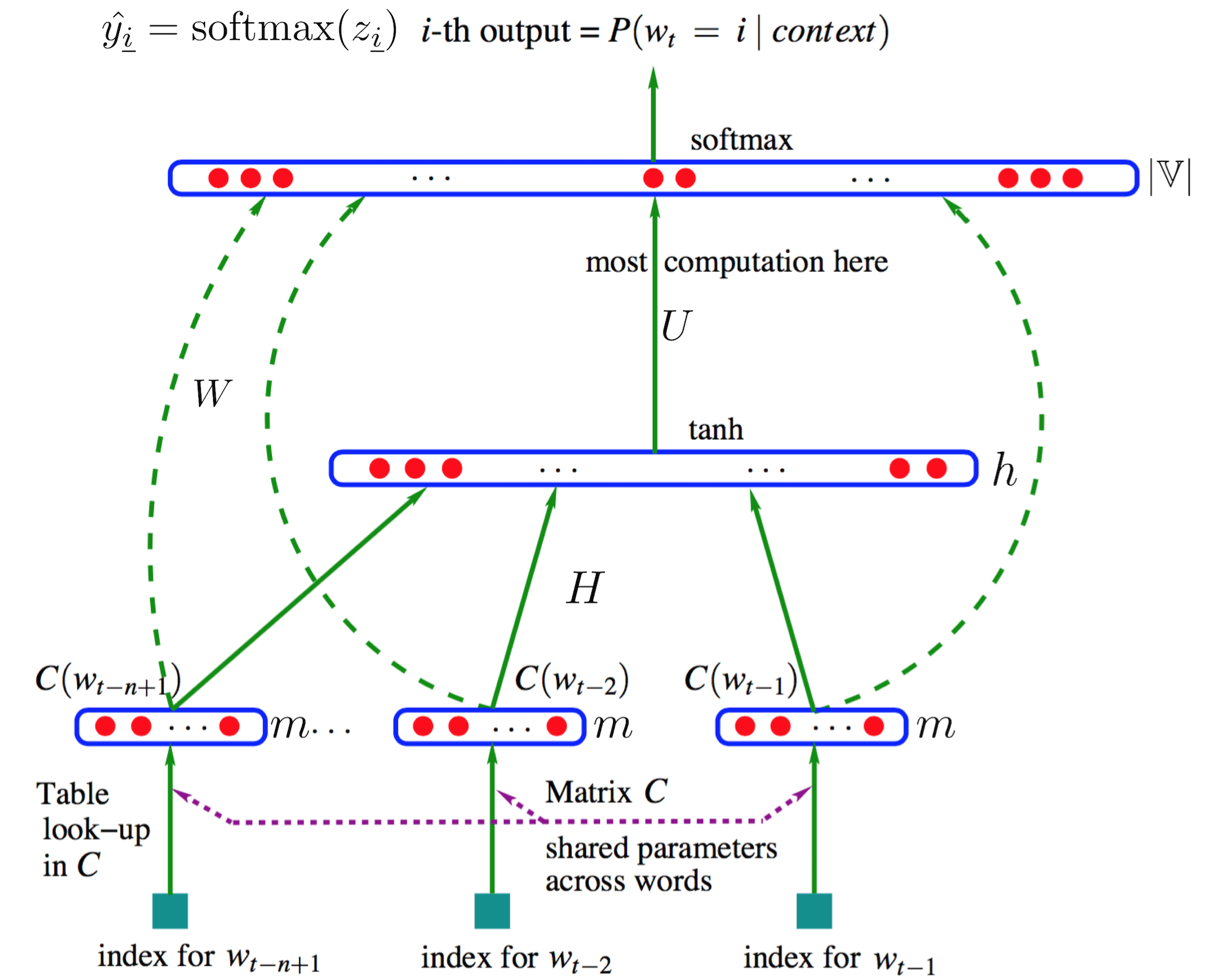
图片来源:[1],加了几个符号
设训练语料为
词表中的每个词的词向量都存在一个矩阵
那么,模型的参数就有:
使用交叉熵损失函数,模型对目标词
那么模型的经验风险为(省略了常系数)
所以接下来就可以使用梯度下降等方法来迭代求取参数了。这样便同时训练了语言模型和词向量。
word2vec:CBOW / Skip-gram
上面介绍的NPLM以训练语言模型为目标,同时得到了词表示。2013年的开源工具包word2vec则包含了CBOW和Skip-gram这两个直接以得到词向量为目标的模型。
像SGNS这些新兴的获得embedding的模型其实不属于字面含义上的“深度”学习,因为这些模型本身都是很浅层的神经网络。但得到它们后,通常会作为输入各种神经网络结构的初始值(也就是预训练,而不采用随机初始化),并随网络参数一起迭代更新进行fine-tuning。就我做过的实验来说,预训练做初始值时通常可以提升任务上的效果,而且fine-tuning也是必要的,不要直接用初始值而不更新了。
首先它获取word embedding(Distributed representation)的方式是无监督的,只需要语料本身,而不需要任何标注信息,训练时所使用的监督信息并不来自外部标注;但之前的pLSA什么的也是无监督的啊,也是稠密向量表示啊。所以我觉得word2vec之所以引爆了DL在NLP中的应用更可能是因为它在语义方面的一些优良性质,比如相似度方面和词类比(word analogy)现象,便于神经网络从它开始继续去提取一些high level的东西,进而去完成复杂的任务。
这里先介绍两种模型的没有加速策略的原始形式(也就是输出层是softmax的那种。对于Skip-gram模型,作者在paper中称之为“impractical”),两种加速策略将在下篇文中介绍。
与NPLM不同,在CBOW / Skip-gram模型中,目标词
在原始的CBOW / Skip-gram模型中,任一个词
与NPLM类似,词表中每个词的词向量都存在一个矩阵中。由于存在两套词向量,因此就有两个矩阵:输入词矩阵
(一)CBOW(Continuous Bag-of-Words)
不带加速的CBOW模型是一个两层结构,相比于NPLM来说CBOW模型没有隐层,通过上下文来预测中心词,并且抛弃了词序信息——
输入层:
输入层到输出层的连接边:输出词矩阵
输出层:
如果要视作三层结构的话,可以认为——
输入层:
输入层到投影层到连接边:输入词矩阵
投影层::
投影层到输出层的连接边:输出词矩阵
输出层:
这样表述相对清楚,将one-hot到word embedding那一步描述了出来。这里的投影层并没有做任何的非线性激活操作,直接就是Softmax层。换句话说,如果只看投影层到输出层的话,其实就是个Softmax回归模型,但标记信息是词串中心词,而不是外部标注。
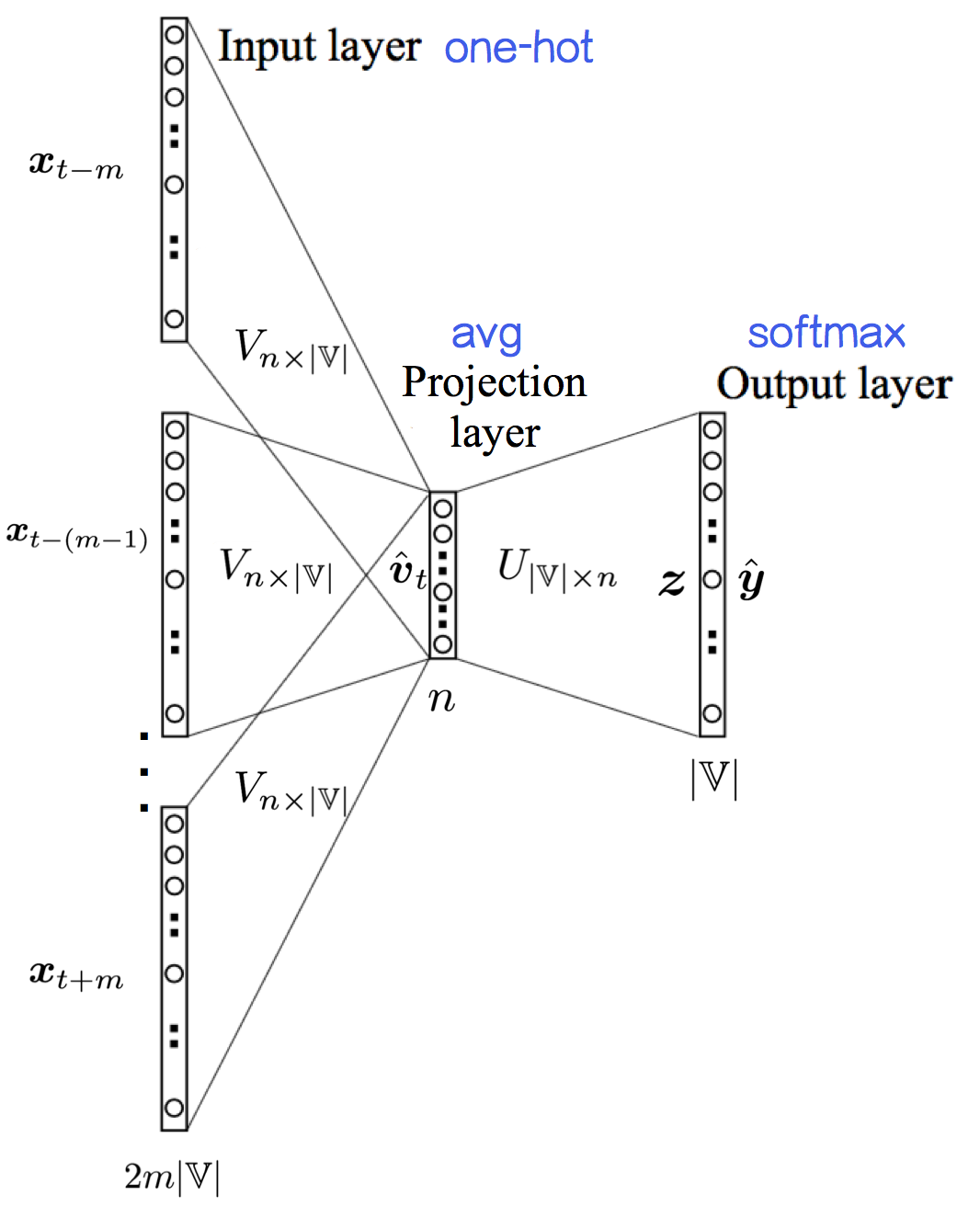
图片来源:[5],把记号都改成和本文一致
首先,将中心词
进而将上下文的输入词向量
这一步叫投影(projection)。可以看出,CBOW像词袋模型(BoW)一样抛弃了词序信息,然后窗口在语料上滑动,就成了连续词袋= =。丢掉词序看起来不太好,不过开个玩笑的话:“研表究明,汉字的序顺并不定一能影阅响读,事证实明了当你看这完句话之后才发字现都乱是的”。
与NPLM不同,CBOW模型没有隐藏层,投影之后就用softmax()输出目标词是某个词的概率,进而减少了计算时间:
那么模型的参数就是两个词向量矩阵:
对于中心词
所以模型的经验风险为
做文本的各位同好应该都知道fastText,它相比于CBOW有两个比较重要的区别:首先,fastText是一个端到端的分类器,用全部窗口词取平均去预测文档的标签,而不是预测窗口中心词;另外一个,是它引入了局部词序,也就是 n-gram 特征,所以train出来的词向量和word2vec有一些不一样的特点。因为Hierarchical Softmax还有其他的trick,它的速度快到难以置信,而且精度并不低,没用过fastText的各位可以跑下实验感受一下。
下面开始是非常无聊的求导练习。。。
如果用SGD来更新参数的话,只需求出模型对一个样本的损失的梯度。也就是说上式的求和号可以没有,直接对
I. 首先是对输出词矩阵
这部分和Softmax回归模型的梯度推导过程是一样一样的。有很多种方法,下面介绍最按部就班的方法。
因为
(1) 对
(2) 对
可见两种情形的结果是统一的,就是误差项。
因此有
那么对于词表中的任一个词
不妨把它们拼接成对矩阵的梯度:
II. 接下来是对输入词矩阵
因为
因此有
那么对于中心词
(二)Skip-gram
不带加速的Skip-gram模型其实和CBOW模型很相似,二者都是用上下文来预测中心词。二者的区别在于,CBOW模型把上下文的

Skip-gram模型中,对于中心词
第二个等号是独立性假设。后面的求梯度过程也是类似的。
下篇博文将简述两种从计算上加速的策略。
观众朋友们可能会问,实验呢?我觉得word embedding的实验还是要结合具体任务,毕竟它通常是作为初始值的。我做实验时都是用gensim包来train词向量,现在TF也有例子,我没对比过。现在感受就是:用pre-train的话比随机初始化要好;fine-tuning做了比不做要好。基本上都属于说了跟没说一样……关于各个超参数的取值,首先我习惯用SGNS(Skip-gram搭配负采样加速),然后诸如维数、窗口大小、最低词频、二次采样的设置等等都要根据语料的实际情况:维数的话,如果不是机器翻译这种特别大的任务一般200以内就够;窗口大小,如果是推特这样的短文本那就不能取太大。调这些参数的trick在网上也有一些其它的博客在写,这里只是笼统的写一点。另外,各个我之前的pre-train都用的是word2vec的,没用过GloVe,如果语料足够大就用语料训练,如果语料不大就用中文维基百科。以后可能会尝试对比一下GloVe做pre-train。
另外我个人有个疑惑,关于word2vec的改进应该有不少paper,如果它们是有效的,为什么没有被写进gensim这样的工具包呢?
(三)word analogy
word analogy是一种有趣的现象,可以作为评估词向量的质量的一项任务。

图片来源:[6]
word analogy是指训练出的word embedding可以通过加减法操作,来对应某种关系。比如说左图中,有
参考:
[1] A Neural Probabilistic Language Model, LMLR2003
[2] Efficient Estimation of Word Representations in Vector Space, ICLR2013
[3] CS224d Lecture Notes1
[4] (PhD thesis)基于神经网络的词和文档语义向量表示方法研究
[5] word2vec Parameter Learning Explained
[6] Linguistic Regularities in Continuous Space Word Representations, NAACL2013
[7] Comparison of FastText and Word2Vec
- CBOW
- NLP基础-CBOW&DEEP CBOW-影评分类
- word2vec (二) CBOW
- cbow和skip-gram
- 轻松理解CBOW模型
- word2vector:NPLM、CBOW、Skip-gram
- CBOW and Skip-gram model
- 谈谈Word2Vec的CBOW模型
- 自己动手写word2vec (四):CBOW和skip-gram模型
- ud730深度学习(二)——Word2Vec and CBOW
- Word2Vec (Part 2): NLP With Deep Learning with Tensorflow (CBOW)
- Word2vec基础介绍(四):CBOW和skip-gram模型
- Word2Vec (Part 2): NLP With Deep Learning with Tensorflow (CBOW)
- [NLP论文阅读]Siamese CBOW: OptimizingWord Embeddings for Sentence Representations
- 词嵌入(word2vec)-CBOW原理通俗解释
- Word2vec之CBOW模型和Skip-gram模型形象解释
- 基于Huffman树的CBOW模型的理解
- What are the continuous bag of words(CBOW) and skip-gram?
- 乐观锁与悲观锁的通俗理解
- 斯特林公式
- 如何使用DOS命令通过FTP进行上传和下载
- NSUserDefaults的写法问题
- Struts2框架搭建-新手教程
- CBOW
- linux 环境安装jdk
- 开发利器总结(一)
- NodeJS通过ffi调用DLL
- 武将属性基础模型
- 组合数算法,紫书P64
- vue组件中camelCased (驼峰式) 命名与 kebab-case(短横线命名)
- 带环链表-LintCode
- java.util.concurrent包下的几个常用类


