【Mongo】存储引擎-WiredTiger概览
来源:互联网 发布:facebook 批量操作软件 编辑:程序博客网 时间:2024/06/05 01:34
一、WiredTiger整体架构
WiredTiger的写操作会先写入Cache,并持久化到WAL(Write ahead log),每60s或log文件达到2GB时会做一次Checkpoint,将当前的数据持久化,产生一个新的快照。
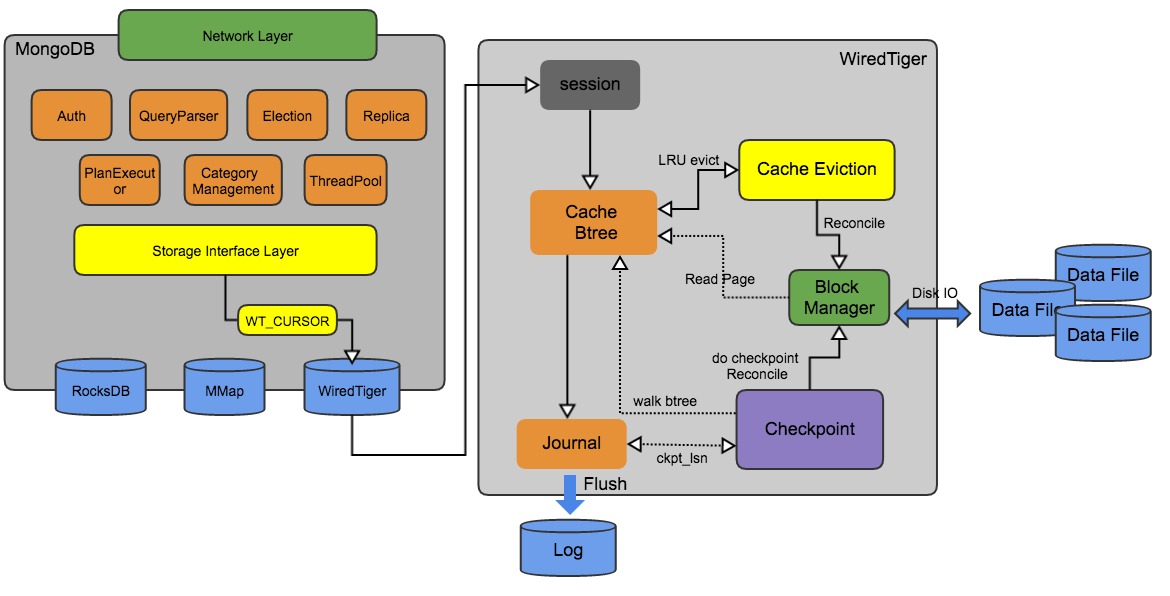
session 模块,负责和wt引擎上层交互的句柄,每个session会关联多个cursor,cursor属于一个sessioncache 模块,主要有内存中的btree page(数据页,索引页,溢出页)构成evict 模块,如果cache内存紧张,触发cache淘汰,便利btree,并根据LRU排序淘汰Journal 模块,WAL log,类似InnoDB的redolog,保证数据持久化,通过定时和定量阈值来flushcheckpoint 模块,类似InnoDB checkpoint机制,异步执行btree刷盘,checkpoint之后通知log模块更新log_ckpt_lsn(lsn概念和InnoDB一致)block manager模块,负责磁盘IO的读写,cache、evict、checkpoint模块均通过该模块访问磁盘
二、Cache Btree
Wiredtiger的Cache采用Btree的方式组织,每个Btree节点为一个page,root page是btree的根节点,internal page是btree的中间索引节点,leaf page是真正存储数据的叶子节点;
btree的数据以page为单位按需从磁盘加载或写入磁盘

持久化时,修改操作不会在原来的leaf page上进行,而是写入新分配的page,每次checkpoint都会产生一个新的root page。这样的好处是对不修改原有page,就能更好的并发。

三、Checkpoint
- 每个客户端的写请求会先通过Journal进行持久化,提供参数 {j: true} ;
- 每60s或(Journal)log文件达到2GB时会做一次Checkpoint,将当前的数据持久化,产生一个新的快照;
- Checkpoint时会遍历所有btree,把btree的所有leaf_page做reconcile操作,然后重新分配root_page; reconcile 操作:把内存里page的修改(保存在page的modify_list中)变成磁盘page的结构写入
- 在一个新的Checkpoint过程中,先前的Checkpoint仍然有效,即使在CheckPoint过程中出现故障,通过重启也能回复到上一次有效的Checkpoint。(加上Journal的log可进行完整数据回复)
- 当一个新Checkpoint可用的时候,释放掉旧的Checkpoint。(同时Journal更新checkpoint offset,即可丢弃之前的journal)
所以写请求写入journal后就可以保证Durability
四、数据丢失问题
Mongo早期的一些默认配置,如果不加修改使用的话,确实有可能导致一些数据丢失问题,但在后面的版本都已修正默认配置。
比如,2.0之前Journal默认是不开启状态,数据在写入内存后即刻返回应用程序,Checkpoint需要60s才持久化,这个时候发生了系统崩溃或者掉电,那么未刷盘的数据就会彻底丢失了。
写关注设置, 2.2之前默认值为{w:0},不确认写入结果直接返回
对复制集来说,建议使用{w: “majority”, j: "true"}
阅读全文
0 0
- 【Mongo】存储引擎-WiredTiger概览
- mongo wiredTiger存储引擎相关
- WiredTiger存储引擎分析
- Mongodb Wiredtiger存储引擎实现原理
- Mongodb Wiredtiger存储引擎实现原理
- MongoDB Wiredtiger存储引擎实现原理
- MongoDB 存储引擎:WiredTiger和In-Memory
- MongoDB 存储引擎Wiredtiger原理剖析
- MongoDB WiredTiger 存储引擎(1) cache_pool设计
- MongoDB 存储引擎:WiredTiger和In-Memory
- MongoDB 存储引擎:WiredTiger和In-Memory
- 解析MongoDB存储引擎WiredTiger:事务实现
- MongoDB 存储引擎:WiredTiger和In-Memory
- WiredTiger引擎
- mongodb 3.0.2与wiredTiger存储引擎安装测试
- MongoDB 3.2版WiredTiger存储引擎性能测试
- Mongodb(1)——存储引擎WiredTiger的使用
- MongoDB WiredTiger 存储引擎cache_pool设计 (下) -- 实践篇
- table布局
- angularjs $watch
- 初步了解JND
- Binary String Matching
- JZOJ 7.12 B组第一题Super Big Stupid Cross
- 【Mongo】存储引擎-WiredTiger概览
- CSS概念、颜色、尺寸单位
- string类,浅拷贝,深拷贝(简洁版),写时拷贝
- Android源码(5) --- Application 启动流程
- css基础知识
- Bootstrap前端框架
- HP QR Code是一个PHP二维码生成类库
- 类的指针成员释放
- 协同过滤算法


