Java中的原子操作
来源:互联网 发布:蜀地割据知乎 编辑:程序博客网 时间:2024/05/17 01:47
Java的指针Unsafe类
Java放弃了指针,获得了更高的安全性和内存自动清理的能力。但是,它还是在一个角落里提供了类似于指针的功能,那就是sun.misc.Unsafe类,利用这个类,可以完成许多需要指针才能提供的功能,例如构造一个对象,但是不调用构造函数;找到对象中一个变量的地址,然后直接给它赋值,无视其final属性;通过地址直接操作数组;或者是进行CAS操作。例子如下:
public class UnSafeExam { public static void main(String[] args) throws InstantiationException, NoSuchFieldException { //获得一个UnSafe实例 Unsafe unsafe = null; try { Field f = Unsafe.class.getDeclaredField("theUnsafe"); f.setAccessible(true); unsafe = (Unsafe) f.get(null); } catch (NoSuchFieldException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } if (unsafe != null) { try { //构造一个对象,且不调用其构造函数 Test test = (Test) unsafe.allocateInstance(Test.class); //得到一个对象内部属性的地址 long x_addr = unsafe.objectFieldOffset(Test.class.getDeclaredField("x")); //直接给此属性赋值 unsafe.getAndSetInt(test, x_addr, 47); System.out.println(test.getX()); } catch (InstantiationException e) { e.printStackTrace(); } catch (NoSuchFieldException e) { e.printStackTrace(); } } //通过地址操作数组 if (unsafe != null) { final int INT_BYTES = 4; int[] data = new int[10]; System.out.println(Arrays.toString(data)); long arrayBaseOffset = unsafe.arrayBaseOffset(int[].class); System.out.println("Array address is :" + arrayBaseOffset); unsafe.putInt(data, arrayBaseOffset, 47); unsafe.putInt(data, arrayBaseOffset + INT_BYTES * 8, 43); System.out.println(Arrays.toString(data)); } //CAS if (unsafe != null) { Test test = (Test) unsafe.allocateInstance(Test.class); long x_addr = unsafe.objectFieldOffset(Test.class.getDeclaredField("x")); unsafe.getAndSetInt(test, x_addr, 47); unsafe.compareAndSwapInt(test, x_addr, 47, 78); System.out.println("After CAS:" + test.getX()); } } static class Test { private final int x; Test(int x) { this.x = x; System.out.println("Test ctor"); } int getX() { return x; } }}47[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]Array address is :16[47, 0, 0, 0, 0, 0, 0, 0, 43, 0]After CAS:78熟悉反射的人应该很快能够理解上面的代码,下面重点说说CAS这个操作。CAS即CompareAndSwap操作,在Unsafe中它有如下形式:
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5);public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);这三个方法都有四个参数,其中第一和第二个参数代表对象的实例以及地址,第三个参数代表期望值,第四个参数代表更新值。CAS的语义是,若期望值等于对象地址存储的值,则用更新值来替换对象地址存储的值,并返回true,否则不进行替换,返回false。
后面我们会看到诸多的原子变量,例如AtomicInteger、AtomicLong、AtomicReference等等都提供了CAS操作,其底层都是调用了Unsafe的CAS,它们的参数往往是三个,对象值、期望值和更新值,其语义也与Unsafe中的一致。
CAS是所有原子变量的原子性的基础,为什么一个看起来如此不自然的操作却如此重要呢?其原因就在于这个native操作会最终演化为一条CPU指令cmpxchg,而不是多条CPU指令。由于CAS仅仅是一条指令,因此它不会被多线程的调度所打断,所以能够保证CAS操作是一个原子操作。补充一点,当代的很多CPU种类都支持cmpxchg操作,但不是所有CPU都支持,对于不支持的CPU,会自动加锁来保证其操作不会被打断。
由此可知,原子变量提供的原子性来自CAS操作,CAS来自Unsafe,然后由CPU的cmpxchg指令来保证
i++不是线程安全的
所谓“线程安全的”,意思是在多线程的环境下,多次运行,其结果是不变的,或者说其结果是可预知的。若某些对变量的操作不能保持原子性,则其操作就不是线程安全的。
为了说明原子性,来给出一个没有实现原子性的例子,例如i++这一条语句,它实际上会被编译为两条CPU指令,因此若一些线程在运行时被从中打断,就会造成不确定的后果,如下:
public class IplusplusExam { private volatile static int i = 0; public static void main(String[] args) throws InterruptedException { ExecutorService service = Executors.newCachedThreadPool(); for (int j = 0; j < 10; j++) { service.execute(() -> { for (int k = 0; k < 10000; k++) { i++; } }); } service.shutdown(); service.awaitTermination(1, TimeUnit.DAYS); System.out.println(i); }}十个线程分别对i变量进行10000次i++操作,若i++是线程安全的,则最终i应该等于100000,但是你会发现每次结果都不一样。
当程序更新一个变量时,如果多线程同时更新这个变量,可能得到期望之外的值,比如变量i=1,A线程更新i+1,B线程也更新i+1,经过两个线程操作之后可能i不等于3,而是等于2。因为A和B线程在更新变量i的时候拿到的i都是1,这就是线程不安全的更新操作,通常我们会使用synchronized来解决这个问题,synchronized会保证多线程不会同时更新变量i。
而从JDK 1.5开始提供了java.util.concurrent.atomic包,这个包中的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。
因为变量的类型有很多种,所以在Atomic包里一共提供了13个类,属于4种类型的原子更新方式,分别是
- 原子更新基本类型
- 原子更新数组
- 原子更新引用
- 原子更新属性(字段)
Atomic包里的类基本都是使用Unsafe实现的包装类。
1 原子更新基本类型类
若要保持一个变量改变数值时的原子性,目前Java最简单的方法就是使用相应的原子变量,例如AtomicInteger,AtomicBoolean和AtomicLong。再来看一个例子:
public class AtomicIntegerExam { public static void main(String[] args) throws InterruptedException { AtomicInteger atomicInteger = new AtomicInteger(0); ExecutorService service = Executors.newCachedThreadPool(); for (int j = 0; j < 10; j++) { service.execute(() -> { for (int k = 0; k < 10000; k++) { atomicInteger.incrementAndGet(); } }); } service.shutdown(); service.awaitTermination(1, TimeUnit.DAYS); System.out.println(atomicInteger.get()); }}这次的结果为保持为100000了。因为AtomicInteger的incrementAndGet()操作是原子性的。观察其内部代码,它使用了Unsafe的compareAndSwapInt()方法。
那么现在整形有AtomicInteger,长整型有AtomicLong,布尔型有AtomicBoolean,那么浮点型怎么办?JDK的说法是程序员可以利用AtomicInteger以及Float.floatToRawIntBits和Float.intBitsToFloat来自己实现一个AtomicFloat;利用AtomicLong以及Double.doubleToRawLongBits和Double.longBitsToDouble来自己实现一个AtomicDouble。在网上可以搜索到相应的实现实现JDK没有提供的AtomicFloat - 杨尚川的个人页面,这里就不再赘述了。
使用原子的方式更新基本类型,Atomic包提供了以下3个类:
- AtomicBoolean:原子更新布尔类型
- AtomicInteger:原子更新整型
- AtomicLong:原子更新长整型
以上3个类提供的方法几乎一模一样,所以本文仅以AtomicInteger为例,常用方法如下:
- int addAndGet(int delta):以原子方式将输入的数值与实例中的值(AtomicInteger里的value)相加,并返回结果
- boolean compareAndSet(int expect,int update):如果输入的数值等于预期值,则以原子方式将该值设置为输入的值
- int getAndIncrement():以原子方式将当前值加1,注意,这里返回的是自增前的值
- void lazySet(int newValue):JDK6所增加,最终会设置成newValue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内还是可以读到旧的值。关于该方法的更多信息可以参考并发编程网翻译的一篇文章《AtomicLong.lazySet是如何工作的?》,文章地址是“http://ifeve.com/howdoes-atomiclong-lazyset-work/”
- int getAndSet(int newValue):以原子方式设置为newValue的值,并返回旧值
那么getAndIncrement是如何实现原子操作的呢?让我们一起看看源码
public final int getAndIncrement() { for (;;) { int current = get(); int next = current + 1; if (compareAndSet(current, next)) return current; }}public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update);}源码中for循环体的
- 第一步先取得AtomicInteger里存储的数值
- 第二步对AtomicInteger的当前数值进行加1操作
- 关键的第三步调用compareAndSet方法来进行原子更新操作,该方法先检查当前数值是否等于current
- 等于:意味着AtomicInteger的值没有被其他线程修改过,则AtomicInteger的当前数值更新成next的值
- 不等:compareAndSet方法会返回false,程序会进入for循环重新进行compareAndSet操作
Atomic包提供了3种基本类型的原子更新,但是Java的基本类型里还有char、float和double等.那么问题来了,如何原子的更新其他的基本类型呢?Atomic包里的类基本都是使用Unsafe实现的,让我们一起看一下Unsafe的源码.
/** * 如果当前数值是expected,则原子的将Java变量更新成x * @return 如果更新成功则返回true */ public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object x); public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x); public final native boolean compareAndSwapLong(Object o, long offset, long expected, long x);我们发现Unsafe只提供了3种CAS方法,再看AtomicBoolean源码,发现它是先把Boolean转换成整型,再使用compareAndSwapInt进行CAS,所以原子更新char、float和double变量也可以用类似思路.
2 原子更新数组
通过原子的方式更新数组里的某个元素,Atomic包提供了以下4个类:
- AtomicIntegerArray:原子更新整型数组里的元素
- AtomicLongArray:原子更新长整型数组里的元素
- AtomicReferenceArray:原子更新引用类型数组里的元素
AtomicIntegerArray类常用方法如下:
- int addAndGet(int i,int delta):以原子方式将输入值与数组中索引i的元素相加
- boolean compareAndSet(int i,int expect,int update):如果当前值等于预期值,则以原子方式将数组位置i的元素设置成update值.
数组中每个元素在改变时都可以保持原子性。。例子如下:
public class AtomicIntegerArrayExam { public static void main(String[] args) throws InterruptedException { AtomicIntegerArray array = new AtomicIntegerArray(5); array.set(0, 0); array.set(1, 0); ExecutorService service = Executors.newCachedThreadPool(); for (int i = 0; i < 10; i++) { service.execute(() -> { for (int j = 0; j < 10000; j++) { array.getAndIncrement(0); } for (int j = 0; j < 10000; j++) { array.getAndIncrement(1); } }); } service.shutdown(); service.awaitTermination(1, TimeUnit.DAYS); System.out.println("array[0] = "+array.get(0)+", array[1] = "+array.get(1)); }}10个线程分别对array[0]和array[1]进行了10000次加1操作,结果符合原子性。还有一点值得注意的是,为了性能考虑,应该尽量使用AtomicIntegerArray[n],而不是AtomicInteger[n],因为后者需要创建n个原子变量实例,而前者只需要创建一个原子变量数组实例,而完成的功能是一样的。
以上几个类提供的方法几乎一样,所以仅以AtomicIntegerArray为例,使用实例代码如下
public class AtomicIntegerArrayTest { static int[] value = new int[] { 1, 2 }; static AtomicIntegerArray ai = new AtomicIntegerArray(value); public static void main(String[] args) { ai.getAndSet(0, 3); System.out.println(ai.get(0)); System.out.println(value[0]); }}输出:
31值得注意的是,数组value通过构造方法传递进去,然后AtomicIntegerArray会将当前数组复制一份,所以当AtomicIntegerArray对内部的数组元素进行修改时,不会影响传入的数组.
3 原子更新引用类型
原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。
Atomic包提供了以下3个类:
- AtomicReference:原子更新引用类型
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
- AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,boolean initialMark)。
例子如下:
public class AtomReferenceExam { public static void main(String[] args) throws InterruptedException { AtomicReference<Element> reference = new AtomicReference<>(new Element(0, 0)); ExecutorService service = Executors.newCachedThreadPool(); for (int i = 0; i < 10; i++) { service.execute(() -> { for (int j = 0; j < 10000; j++) { boolean flag = false; while (!flag) { Element storedElement = reference.get(); Element newElement = new Element(storedElement.x + 1, storedElement.y + 1); flag = reference.compareAndSet(storedElement, newElement); } } }); } service.shutdown(); service.awaitTermination(1, TimeUnit.DAYS); System.out.println("element.x=" + reference.get().x + ",element.y=" + reference.get().y); } private static class Element { int x; int y; public Element(int x, int y) { this.x = x; this.y = y; } }}值得注意的有两点,一是如果有好几个变量要同时进行原子化的改变,那么可以把这几个变量放到一个Java类中,做成一个所谓的POJO(Plain Ordinary Java Object)类,然后使用AtomicReference来操作这个类。
第二点是以下这段代码:
boolean flag = false;while (!flag) { Element storedElement = reference.get(); Element newElement = new Element(storedElement.x + 1, storedElement.y + 1); flag = reference.compareAndSet(storedElement, newElement);}这是一种很通用的写法,在很多情况下,这种类似的写法都被称之为自旋锁(spinLock,我们会在后续的章节中介绍)。在使用AtomicReference的时候,会常常使用这种写法。
以上几个类提供的方法几乎一样,仅以AtomicReference为例
使用示例代码如下
public class AtomicReferenceTest { public static AtomicReference<user> atomicUserRef = new AtomicReference<user>(); public static void main(String[] args) { User user = new User("conan", 15); atomicUserRef.set(user); User updateUser = new User("Shinichi", 17); atomicUserRef.compareAndSet(user, updateUser); System.out.println(atomicUserRef.get().getName()); System.out.println(atomicUserRef.get().getOld()); } static class User { private String name; private int old; public User(String name, int old) { this.name = name; this.old = old; } public String getName() { return name; } public int getOld() { return old; } }}代码中首先构建一个user对象,然后把user对象设置进AtomicReferenc中,最后调用
compareAndSet方法进行原子更新操作,实现原理同AtomicInteger里compareAndSet方法
输出:
Shinichi174 原子更新字段类
4 原子更新字段类
如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic包提供
了以下3个类进行原子字段更新。
- AtomicIntegerFieldUpdater:原子更新整型的字段的更新器
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用CAS进行原子更新时可能出现的ABA问题。
要想原子地更新字段类需要两步:
- 第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。
- 第二步,更新类的字段(属性)必须使用public volatile修饰符。
这些类的应用场景是:如果已经有一个写好的类,但是随着业务场景的变化,其中某些属性在写入的时候需要保持原子性,那么就可以使用以上的类来实现这种原子性,并保持类的原有接口不变。 例子如下:
public class AtomicIntegerFieldUpdaterExam { public static void main(String[] args) throws InterruptedException { Student student = new Student(0, "Alex Wang"); AtomicIntegerFieldUpdater<Student> updater = AtomicIntegerFieldUpdater.newUpdater(Student.class, "id"); ExecutorService service = Executors.newCachedThreadPool(); for (int i = 0; i < 10; i++) { service.execute(new Runnable() { @Override public void run() { for (int j = 0; j < 10000; j++) { updater.getAndIncrement(student); } } }); } service.shutdown(); service.awaitTermination(1, TimeUnit.DAYS); System.out.println(student); } private static class Student { volatile int id; String name; public Student(int id, String name) { this.id = id; this.name = name; } @Override public String toString() { return "Student id = " + id + ",name = " + name; } }}上面的例子中给出了一个原有的类Student,其中属性id是volatile int(注意,要应用原子属性更新器的属性必须是volatile的),为了使这个属性能够被原子化的改变,我们创建了一个AtomicIntegerFieldUpdater,其构造方法为AtomicIntegerFieldUpdater.newUpdater(Student.class, “id”),注意第一个参数是一个class,而第二个参数是属性名字的字符串值(这里显然用到了反射)。接下来就可以使用这个Updater来更新属性值了,其用法类似于AtomicInteger。10个线程分别对这个属性进行了10000次加1操作,结果为100000。
以上3个类提供的方法几乎一样,所以以AstomicIntegerFieldUpdater为例
示例代码
public class AtomicIntegerFieldUpdaterTest { // 创建原子更新器,并设置需要更新的对象类和对象的属性 private static AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater. newUpdater(User.class, "old"); public static void main(String[] args) {// 设置柯南的年龄是10岁 User conan = new User("conan", 10);// 柯南长了一岁,但是仍然会输出旧的年龄 System.out.println(a.getAndIncrement(conan));// 输出柯南现在的年龄 System.out.println(a.get(conan)); } public static class User { private String name; public volatile int old; public User(String name, int old) { this.name = name; this.old = old; } public String getName() { return name; } public int getOld() { return old; } }}输出:
1011AtomicStampedReference带有版本号的原子引用
AtomicStampedReference和AtomicMarkableReference是atomic包中两个比较难以理解的类,它们都是为了解决ABA问题而创建出来的。
1 ABA问题
在介绍AtomicReference的时候已经说过,为了实现原子引用的原子性改变,需要用一种类似于自旋锁的代码写法,如下:
boolean flag = false;while (!flag) { Element oldValue = reference.get(); Element newValue = new Element(…);//如果有其他线程在这里将oldValue从A改为B,做了一些事情,然后又将oldValue改为A,则下面的语句依然能够返回true flag = reference.compareAndSet(oldValue, newValue);}以上情况下,oldValue从A改为B,又从B改为A,不会影响compareAndSet的返回值。但是在某些情况下,会造成不确定的结果,因此影响了线程安全性,这种问题就叫做自旋锁的ABA问题,例如: 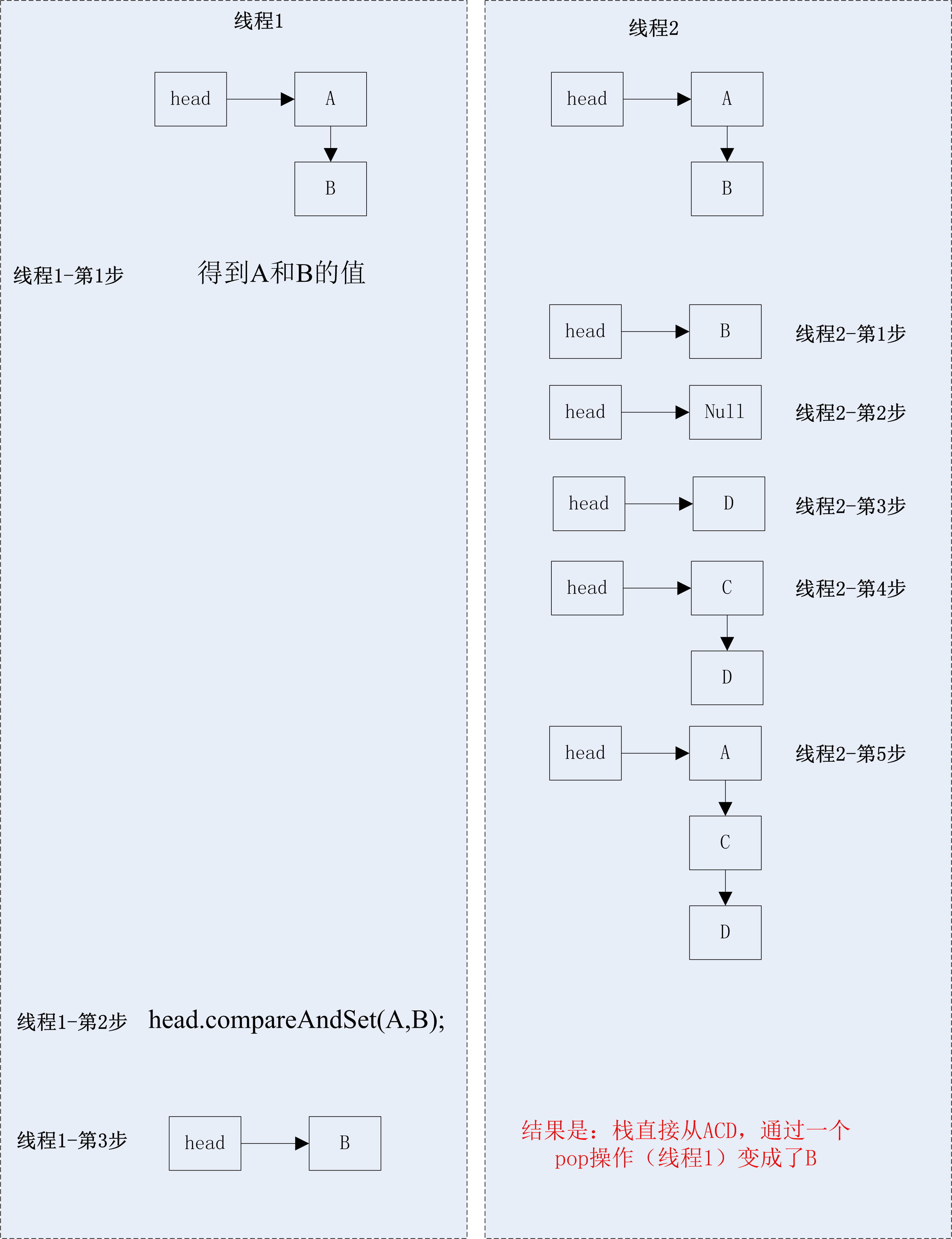
ABA问题一般存在于链表、栈这类的并发数据结构中。从上面的例子中可以看出,由于ABA问题,最后的结果是,在特定的条件下,一个ACD栈(三个元素),经过一个pop操作(线程1)变成了B(一个元素),这显然不是线程安全的。
下面的代码中,我模拟了这个例子(其中很多地方并未充分考虑并发的正确性,主要是为了展示ABA问题):
public class ABAProblem { public static void main(String[] args) throws InterruptedException { MyStack<String> stack = new MyStack<>(); stack.push("B"); stack.push("A"); System.out.println("Stack init:" + stack); ExecutorService service = Executors.newCachedThreadPool(); service.execute(new Runnable() { @Override public void run() { Thread.currentThread().setName("Thread1"); stack.pop(); System.out.println("Thread1 pop :" + stack); } }); service.execute(new Runnable() { @Override public void run() { Thread.currentThread().setName("Thread2"); Node<String> A = stack.pop(); System.out.println("Thread2 pop :" + stack); stack.pop(); System.out.println("Thread2 pop :" + stack); stack.push("D"); System.out.println("Thread2 push D:" + stack); stack.push("C"); System.out.println("Thread2 push C:" + stack); stack.push(A); System.out.println("Thread2 push A:" + stack); } }); service.shutdown(); service.awaitTermination(1, TimeUnit.DAYS); System.out.println("Stack result:" + stack); } static class MyStack<T> { AtomicReference<Node<T>> head = new AtomicReference<>(null); public void push(T value) { Node<T> node = new Node<>(value); push(node); } public void push(Node<T> node) { for (; ; ) { Node<T> tmpHead = head.get(); if (head.compareAndSet(tmpHead, node)) { node.setNext(tmpHead); return; } } } public Node<T> pop() { for (; ; ) { Node<T> node = head.get(); if (node == null) { return null; } Node<T> nextNode = node.getNext(); // add this sleep to cause ABA problem if (Thread.currentThread().getName().equals("Thread1")) { try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } if (head.compareAndSet(node, nextNode)) { return node; } } } @Override public String toString() { StringBuilder sb = new StringBuilder("["); Node<T> node = head.get(); while (node != null) { sb.append(node.getValue()); if (node.getNext() != null) { sb.append(","); } node = node.getNext(); } sb.append("]"); return sb.toString(); } } private static class Node<T> { private T value; private Node<T> next; public Node(T value) { this.value = value; } public Node<T> getNext() { return next; } public void setNext(Node<T> next) { this.next = next; } public T getValue() { return value; } public void setValue(T value) { this.value = value; } }}运行结果是:
Stack init:[A,B]Thread2 pop :[B]Thread2 pop :[]Thread2 push D:[D]Thread2 push C:[C,D]Thread2 push A:[A,C,D]Thread1 pop :[B]Stack result:[B]代码中的push和pop方法都用无限循环的for语句实现,这也是并发中的常见写法,与前面类似自旋锁的while语句实现类似的功能,但由于不需要定义一个boolean变量,因此更加简洁。为了保证ABA问题一定出现,我特意插入了一个针对特定线程的sleep语句。在现实中,出现ABA的几率其实是很小的。
2 用AtomicStampedReference解决ABA问题
ABA问题的实质是:在并发编程中,仅靠检查变量的值是无法知道这个变量是否被改动过的,还要加上一个版本号(当变量改变就改变其版本号)才能确定变量保持不变。AtomicStampedReference实现了此功能,它保存变量引用的同时,还赋予此变量一个版本号。每当变量改动时(这个改动是程序员自定义的,例如存储的数值改变,或者是变量在内存中的位置移动了,或者是变量在某一个数据结构中被移动了),AtomicStampedReference可以同时改动版本号;因此在进行CAS操作时,同时检查引用和版本号,只有同时符合才能成功。如此变可以确保ABA问题不会发生了。
代码进行如下改动(仅改动MyStack):
static class MyStack<T> { //initialStamp = 0 AtomicStampedReference<Node<T>> head = new AtomicStampedReference<>(null, 0); public void push(T value) { Node<T> node = new Node<>(value); push(node); } public void push(Node<T> node) { for (; ; ) { Node<T> tmpHead = head.getReference(); int stamp = head.getStamp(); if (head.compareAndSet(tmpHead, node, stamp, stamp + 1)) { node.setNext(tmpHead); return; } } } public Node<T> pop() { for (; ; ) { Node<T> node = head.getReference(); int stamp = head.getStamp(); if (node == null) { return null; } Node<T> nextNode = node.getNext(); // add this sleep to cause ABA problem if (Thread.currentThread().getName().equals("Thread1")) { try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } if (head.compareAndSet(node, nextNode, stamp, stamp + 1)) { return node; } } } @Override public String toString() { StringBuilder sb = new StringBuilder("["); Node<T> node = head.getReference(); while (node != null) { sb.append(node.getValue()); if (node.getNext() != null) { sb.append(","); } node = node.getNext(); } sb.append("]"); return sb.toString(); }}在每次改动head保存的变量时,都同时给版本号加1,这样就避免了ABA问题的发生,运行结果如下:
Stack init:[A,B]Thread2 pop :[B]Thread2 pop :[]Thread2 push D:[D]Thread2 push C:[C,D]Thread2 push A:[A,C,D]Thread1 pop :[C,D]Stack result:[C,D]另外值得一提的是,AtomicStampedReference还有一个简化版AtomicMarkableReference,它保存的版本号是一个boolean值,适用于某些简化的情景下。
小结
所谓“线程安全的”,就是在并发环境下能够保持运行结果不变。除了原始的synchronize阻塞方法外,使用原子性的语句能够在保持线程安全的前提下提供更好的性能。原子性的基础是CAS语句,而它则是由Unsafe类提供的。有了此利器,JDK提供了AtomicInteger、AtomicBoolean和AtomicLong等类来实现整形、布尔型和长整型变量的原子增减操作;提供了AtomicReference来实现引用类型的原子操作;提供了AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater来实现原有类中某个属性的原子更新操作;提供了AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray等原子数组,数组中每个元素在改变时都可以保持原子性。为了避免ABA问题,提供了AtomicStampedReference和AtomicMarkableReference。
- java中的原子操作
- Java中的原子操作
- java中的原子性操作
- java中的原子操作类
- Java中的原子操作类
- JAVA中的原子操作类
- Java中的原子操作和volatile关键字
- java中的12个原子操作类
- java并发中的原子操作类
- Java原子变量&原子操作
- linux中的原子操作
- Nginx中的原子操作
- Nginx中的原子操作
- Tbb 中的原子操作
- Java并发中的原子操作包java.util.concurrent.atomic
- Java 原子操作
- Java原子操作A
- java原子操作
- 新手上路
- 基础属性文本修饰
- jdk安装(1)
- java 对象存活分析——引用计数法&可达性分析
- 用C语言计算一条语句中的空格、字母、数字的个数。
- Java中的原子操作
- 10.Scala单例对象、伴生对象实战详解
- java 问题分析工具
- python 函数
- HTML基础--(四)
- #终端种类及修改终端命令提示符
- 【Mongo】架构从复制集到分片集群
- VLAN/Trunk以及三层交换
- Isomorphic Strings


