kafka学习内容
来源:互联网 发布:mac版迅雷应版方要求 编辑:程序博客网 时间:2024/06/05 19:39
kafka可以做什么
1.It lets you publish and subscribe to streams of records. In this respect it is similar to a message queue or enterprise messaging system.
2.It lets you store streams of records in a fault-tolerant way.
3.It lets you process streams of records as they occur.
翻译下来就是:
1.kafka可以发布与订阅流式记录数据,这点和消息队列或者企业消息系统很像。
2.kafka是一个可容错的系统
3.kafka按照先到先出处理记录kafka怎样做到
kafka用topic来对消息分类,每个topic可以有一个或者多个订阅者,对每一个topic维护一个可配置数目的分区(partition)。对每一个partition,新纪录会追加到后面。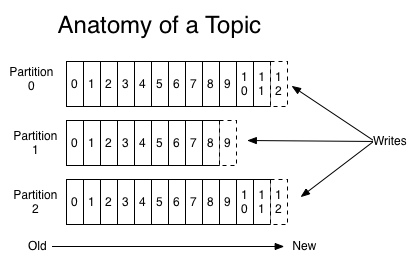
Partition中的每条Message由offset来表示它在这个partition中的偏移量,这个offset不是该Message在partition数据文件中的实际存储位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。因此,可以认为offset是partition中Message的id。partition中的每条Message包含了以下三个属性:offset,MessageSize,data;其中offset为long型,MessageSize为int32,表示data有多大,data为message的具体内容。因为消息的有序性,加上kafka为消息建立了索引与分段机制,因此查询速度比较快。
对每一个consumer,kafka会根据其设置的offset位置开始读取数据。对于一直处于监听的consumer,kafka给出的数据一定是顺序的,服务器也会存储该consumer已经消费数据的offset,下次启动时如果consumer没有设置读取offset值,则从原位置后面开始读取。
kafka如何配置
kafka的文件目录为:
配置文件目录为:
比较重要的配置文件是log4j.properties,server.properties, zookeeper.properties。
log4j.properties是日志记录文件,方便查验程序运行时bug;
server.properties是服务配置文件(grep -v ‘#’ server.properties | sort)


broker.id=0group.initial.rebalance.delay.ms=0log.dirs=/root/data/kafka_2.11-0.11.0.0/data/kafka-logslog.retention.check.interval.ms=300000log.retention.hours=168log.segment.bytes=1073741824host.name=192.168.185.68 advertised.host.name=192.168.185.68 num.io.threads=8num.network.threads=3num.partitions=1num.recovery.threads.per.data.dir=1offsets.topic.replication.factor=1socket.receive.buffer.bytes=102400socket.request.max.bytes=104857600socket.send.buffer.bytes=102400transaction.state.log.min.isr=1transaction.state.log.replication.factor=1zookeeper.connect=192.168.185.68:2181,192.168.185.69:2181,192.168.185.70:2181zookeeper.connection.timeout.ms=6000broker.id在集群中唯一标注一个节点,所以对于slave节点该需要用新值代替;此外host.name,advertised.host.name也需要根据相应机器配置。
当配置完成后,所有机器分别启动zookeeper,然后启动kafka server。
4.kafka如何工作
启动kafka server后,可以在命令行里面测试一下
发送命令:./bin/kafka-console-producer.sh –broker-list 192.168.185.68:9092 –topic test
消费命令:./bin/kafka-console-consumer.sh –zookeeper 192.168.185.68:2181 –topic test –from-beginning
可以看到消费命令设定了消费起点位置!实际中不可能这样通信,因此我们根据kafka提供的kafka java客户端编程发送与消费程序,代码如下:
配置文件:
package com.blake.kafka;import java.util.Properties;public abstract class KafkaProperties { final static int kafkaServerPort = 9092; final static int zkConnectPort = 2181; final static String zkConnect = System.getProperty(Constants.server) + ":" + zkConnectPort; final static String groupId = "group_new"; final static String kafkaServerURL = System.getProperty(Constants.server) + ":" + kafkaServerPort; final static int kafkaProducerBufferSize = 64 * 1024; final static int connectionTimeOut = 20000; final static int reconnectInterval = 10000; final static String clientId = "SimpleConsumerDemoClient"; protected final Properties props = new Properties(); protected final String topic; public KafkaProperties(String topic) { this.topic = topic; props.put("metadata.broker.list", kafkaServerURL); props.put("bootstrap.servers", kafkaServerURL); props.put("bootstrap.servers", kafkaServerURL); props.put("zookeeper.connect", zkConnect); props.put("group.id", groupId); props.put("zookeeper.session.timeout.ms", "40000"); props.put("zookeeper.sync.time.ms", "200"); props.put("auto.commit.interval.ms", "1000"); props.put("enable.auto.commit", "true"); //鑷姩commit props.put("auto.commit.interval.ms", "1000"); //瀹氭椂commit鐨勫懆鏈� props.put("session.timeout.ms", "30000"); //consumer娲绘�ц秴鏃舵椂闂� props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("serializer.class", "kafka.serializer.StringEncoder"); props.put("key.deserializer.encoding", "UTF8"); props.put("value.deserializer.encoding", "UTF8"); }}produce:
package com.blake.kafka;import org.apache.kafka.clients.producer.Callback;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.clients.producer.RecordMetadata;public class Producer extends KafkaProperties { private final KafkaProducer<Integer, String> producer; public Producer(String topic) { super(topic); producer = new KafkaProducer<Integer, String>(props); } public void sendMessage(String message) { ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>(topic, message); producer.send(record, new Callback(){ public void onCompletion(RecordMetadata metadata, Exception e) { if(e != null) e.printStackTrace(); System.out.println("The offset of the record we just sent is: " + metadata.partition() +" "+ metadata.offset()); } }); try { Thread.sleep(100); } catch (InterruptedException e1) { e1.printStackTrace(); } }}consumer:
package com.blake.kafka;import java.util.Arrays;import java.util.List;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;public class Consumer extends KafkaProperties{ private final KafkaConsumer<Integer, String> consumer; private volatile boolean isStop = false; public Consumer(List<String> topics) { super(null); consumer = new KafkaConsumer<>(props); consumer.subscribe(topics); } public Consumer(String topic) { super(topic); consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList(topic)); } public void listening(Callback callback) { while (!isStop) { ConsumerRecords<Integer, String> records = consumer.poll(100); for (ConsumerRecord<Integer, String> record : records){ try{ callback.onCompletion(record.value()); }catch (Exception e){ e.printStackTrace(); } } } } public void stopListening() { this.isStop = true; }}参考文献:
1. http://liyonghui160com.iteye.com/blog/2084354
2. https://kafka.apache.org/documentation/#introduction
- kafka学习内容
- kafka学习
- kafka 学习
- kafka学习
- kafka学习
- kafka学习
- kafka学习
- Kafka学习
- kafka学习
- kafka学习
- kafka学习
- kafka学习
- kafka学习七:kafka 运维
- 学习kafka:log4j写入kafka
- Kafka学习笔记:初识Kafka
- Kafka学习笔记
- kafka学习之路
- kafka学习之二
- 【POJ3461】Oulipo
- 用#define实现宏并求最大值和最小值
- 样式设计中总结的一些要点
- 在ArcGIS中如何画一个五等分的圆
- jquery id选择器和class选择器的区别
- kafka学习内容
- AtCoder Beginner Contest 067 b snake toy
- Apache Kafka -1 介绍
- eclipse解决tomcat端口被占用:Port 8005 required by Tomcat v7.0 Server at localhost is already i
- MySQL 中的字符集和校对规则
- springmvc中url-url-pattern /和/*的区别
- 安卓图片适配相关
- 利用原生JS实时监听input框输入值
- hdu 4717 n个点距离


