Hadoop技术
来源:互联网 发布:python库中文 编辑:程序博客网 时间:2024/06/08 05:03
Hadoop主从结构
HDFS的体系架构
整个Hadoop的体系结构主要是通过HDFS来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的(在最新的Hadoop2.2版本已经实现多个NameNode的配置-这也是一些大公司通过修改hadoop源代码实现的功能,在最新的版本中就已经实现了)。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。HDFS支持文件形式的数据。
从内部来看,文件被分成若干个数据块,这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间,如打开、关闭、重命名文件或目录等,也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写,并在NameNode的统一调度下进行数据库的创建、删除和复制工作。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
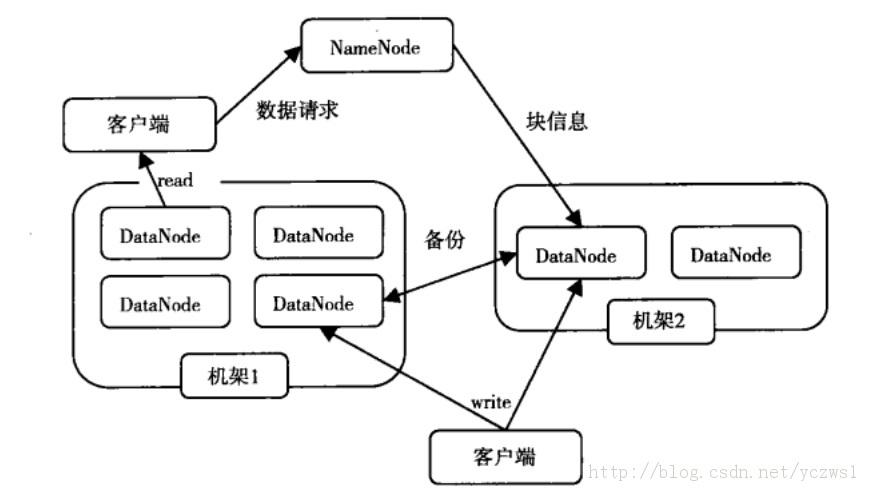
hdfs构造图
读写策略
文件写入:
1) Client向NameNode发起文件写入的请求。
2) NameNode根据文件大小和文件块配置情况,返回给Client它管理的DataNode的信息。
3) Client将文件划分为多个block,根据DataNode的地址,按顺序将block写入DataNode块中。
文件读取:
1) Client向NameNode发起读取文件的请求。
2) NameNode返回文件存储的DataNode信息。
3) Client读取文件信息。
HDFS作为分布式文件系统在数据管理方面可借鉴点:
文件块的放置:一个Block会有三份备份,一份在NameNode指定的DateNode上,一份放在与指定的DataNode不在同一台机器的DataNode上,一根在于指定的DataNode在同一Rack上的DataNode上。备份的目的是为了数据安全,采用这种方式是为了考虑到同一Rack失败的情况,以及不同数据拷贝带来的性能的问题。
详细来说
一 写入数据
当没有配置机架信息时,所有的机器hadoop都默认在同一个默认的机架下,名为“/default-rack”,这种情况下,任何一台 datanode机器,不管物理上是否属于同一个机架,都会被认为是在同一个机架下,此时,就很容易出现之前提到的增添机架间网络负载的情况。在没有机架信息的情况下,namenode默认将所有的slaves机器全部默认为在/default-rack下
而当Hadoop集群中配置了机架感知信息以后,hadoop在选择三个datanode时,就会进行相应的判断:
1.如果上传本机不是一个datanode,而是一个客户端,那么就从所有slave机器中随机选择一台datanode作为第一个块的写入机器(datanode1)。
注意:而此时如果上传机器本身就是一个datanode(例如mapreduce作业中task通过DFSClient向hdfs写入数据的时候),那么就将该datanode本身作为第一个块写入机器(datanode1)。
2.随后在datanode1所属的机架以外的另外的机架上,随机的选择一台,作为第二个block的写入datanode机器(datanode2)。
3.在写第三个block前,先判断是否前两个datanode是否是在同一个机架上,如果是在同一个机架,那么就尝试在另外一个机架上选择第三个datanode作为写入机器(datanode3)。而如果datanode1和datanode2没有在同一个机架上,则在datanode2所在的机架上选择一台datanode作为datanode3。
4.得到3个datanode的列表以后,从namenode返回该列表到DFSClient之前,会在namenode端首先根据该写入客户端跟 datanode列表中每个datanode之间的“距离”由近到远进行一个排序。如果此时DFS写入端不是datanode,则选择datanode列表中的第一个排在第一位。客户端根据这个顺序有近到远的进行数据块的写入。在此,判断两个datanode之间“距离”的算法就比较关键,hadoop目前实现如下,以两个表示datanode的对象DatanodeInfo(node1,node2)为例:
a)首先根据node1和node2对象分别得出两个datanode在整个hdfs集群中所处的层次。这里的层次概念需要解释一下:每个datanode在hdfs集群中所处的层次结构字符串是这样描述的,假设hdfs的拓扑结构如下:
每个datanode都会对应自己在集群中的位置和层次,如node1的位置信息为“/rack1/datanode1”,那么它所处的层次就为2,其余类推。得到两个node的层次后,会沿着每个node所处的拓朴树中的位置向上查找,如“/rack1/datanode1”的上一级就是“ /rack1”,此时两个节点之间的距离加1,两个node分别同上向上查找,直到找到共同的祖先节点位置,此时所得的距离数就用来代表两个节点之间的距离。所以,如上图所示,node1和node2之间的距离就为4.
5.当根据“距离”排好序的datanode节点列表返回给DFSClient以后,DFSClient便会创建BlockOutputStream,并将这次block写入pipeline中的第一个节点(最近的节点)。
6.写完第一个block以后,依次按照datanode列表中的次远的node进行写入,直到最后一个block写入成功,DFSClient返回成功,该block写入操作结束。
通过以上策略,namenode在选择数据块的写入datanode列表时,就充分考虑到了将block副本分散在不同机架下,并同时尽量的避免了之前描述的过多的网络开销。
以下是资料来源网站。
http://www.linuxidc.com/Linux/2015-02/112775.htm
http://blog.csdn.net/norriszhang/article/details/39697005
- 技术-Hadoop
- Hadoop技术
- hadoop streaming 技术整理
- hadoop技术好文章
- Hadoop相关技术站点
- Hadoop相关技术
- Hadoop技术原理总结
- Hadoop技术博客推荐
- Hadoop技术框架
- hadoop 机架感知技术
- hadoop技术基本架构
- Hadoop技术原理总结
- Hadoop技术博客
- Hadoop技术原理总结#
- Hadoop技术操作记录
- Hadoop技术预览
- Hadoop技术原理总结
- hadoop技术原理
- 洛谷P1967货车运输(最大生成树 && LCA倍增)
- this is test
- JMeter基础之一 一个简单的性能测试
- javascript递归创建导航菜单
- Android测试思路
- Hadoop技术
- JVisualVM 远程连接 JMX 和 jstatd
- Tree Grafting,树转换成二叉树,tree recovery,遍历顺序确定二叉树
- fastjson使用技巧整理
- poj 2155 Matrix(树状数组)
- hive weekofyear 怪异的姿势
- hdu1521-dp
- java基础之一 对象,接口
- 工厂方法模式


