“智能问诊”项目——数据获取(1)
来源:互联网 发布:手机淘宝购物 编辑:程序博客网 时间:2024/05/01 15:55
首先确定需求:从“用药参考”上获取药品的名称、适应症等信息保存到本地,为数据处理做准备
通过观察可以发现,不同药品的网址存在一定规律,即http://drugs.medlive.cn/drugref/html/2.shtml,“.shtml”前面的数字代表不同药品(按拼音顺序排列?)
这里我们把药品的范围限定在西药,经过多次试验可以发现其范围区间为2到14578,也就是说这一万四千多种药即是我们要爬取的目标
如果之前没有用python写过爬虫的话,在正式开始写之前还需要做一些准备工作,也就是安装Scrapy
http://www.jianshu.com/p/a03aab073a35这里有详细的教程
但是我在用这个教程的过程中安装Command Line Tools时出了点小问题,于是就直接按照http://railsapps.github.io/xcode-command-line-tools.html的方法装的Command Line Tools
除此之外如果按照默认路径安装Scrapy会出现安装失败的情况。参照http://blog.csdn.net/tangch0516/article/details/51378664即可解决
接下来就可以着手写爬虫了
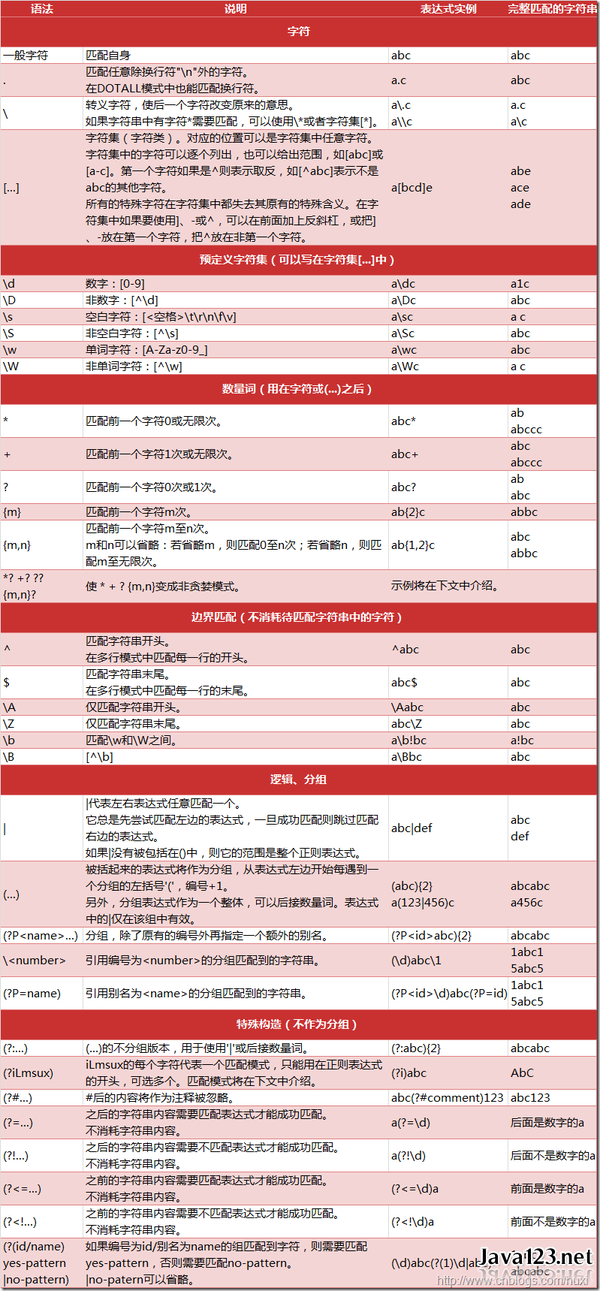
首先在chrome浏览器中打开开发者界面,先看一下内页的结构,然后使用左上角的页面元素选择器找到所需元素所在标签。
我们可以发现药品的通用名称均为该格式,参考之前安卓开发所用的爬虫,其正则表达式应为
<label class=\"w110\">【通用名称】</label>\\s*\\s*(.*?)\\s*\\s*<
(.*?)为要匹配的内容
具体写法参照下图
源码如下:
import reimport urllib.requestimport urllib #网址url1 = "http://drugs.medlive.cn/drugref/html/"url2 = ".shtml"for num in range(2,14579): url = url1 + str(num) + url2 try: #抓取页面 urlop = urllib.request.urlopen(url,timeout=100) except Exception: print("超时") continue #判断是否为html页面 if 'html' not in urlop.getheader('Content-Type'): continue #避免程序异常中止, 用try..catch处理异常 try: #转换为utf-8码 data = urlop.read().decode('utf-8') #print(data) except: continue # 正则表达式提取页面中所有队列, 并判断是否已经访问过, 然后加入待爬队列 linkre1 = re.compile("<label class=\"w110\">【通用名称】</label>\\s*\\s*(.*?)\\s*\\s*<") for x in linkre1.findall(data):##返回所有有匹配的列表 print(x) linkre2 = re.compile("适应症:</a>\\s*</div>\\s*<div class=\"more-infomation\">\\s*<p>(.*?)</p>\\s*</div>") for x in linkre2.findall(data):##返回所有有匹配的列表 print(x) print(url)在爬取的过程中发现某些网页显示超时,这说明某些网页404了,可能是该药品有过改动导致url失效阅读全文
0 0
- “智能问诊”项目——数据获取(1)
- “智能问诊”项目——数据获取(2)
- “智能问诊”项目——数据获取(3)
- “智能问诊”项目——数据匹配(1)
- “智能问诊”项目——数据处理(1)
- “智能问诊”项目——机器学习(1)
- “智能问诊”项目——数据处理(2)
- 实验室智能管理系统(1)——项目介绍
- 江苏省职业健康监护平台数据交换方案 UploadEntity06问诊
- Android开发智能机器人聊天项目(1)- 异步请求数据
- 练手小项目(1)——智能聊天机器人
- 桌面智能盆栽——【1】项目背景
- STM32项目(五)——智能回收箱
- STM32项目(七) —— 智能仓库管理系统
- 智能路由器项目—(1)在RT5350上移植openwrt
- 项目 - 智能交通(1)
- 《商务智能 管理视角》——(四)数据挖掘(1)
- 【ML项目】基于网络爬虫和数据挖掘算法的web招聘数据分析(一)——数据获取与处理
- 文件的输入和输出
- LOJ#117 有源汇有上下界最小流
- 02_MyBatis_crud操作
- ngx_debug_point
- Android content provider 获取手机联系人
- “智能问诊”项目——数据获取(1)
- 高性能Java解析器实现过程详解
- ffmpeg常用基本命令
- Json数据
- PWM的基本原理及其应用实例
- docker 之cp命令使用
- redis整合spring实现对数据的缓存
- jvm虚拟机GC(仅做记录)
- Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network


