zookeeper学习点
来源:互联网 发布:下载漫画的软件 编辑:程序博客网 时间:2024/06/03 19:30
该博文以四个问题为切入点分析zookeeper的相关内容,作为自己学习zookeeper的初步认知。
zookeeper是什么?
zookeeper是管理分布式集群的重要开源工具!它的特点是管理、开源。所以它是集群的管理者,相当于有一个仓储管理员管理着各个仓库。zookeeper是管理者,有时候一个管理者也会忙不过来或者调休的时候,则需要多个管理者,因此zookeeper可以以集群方式工作,所以zookeeper可以是单机版,也可以是集群版。这样说来在一个分布式集群中,我们拥有管理集群加上工作集群。工作集群的每个节点对zookeeper而言就是一个客户端。zookeeper可以干什么?
zookeeper作为管理者可以有不同的功能,比如对hadoop而言,我们需要保证集群中一定有且只有一个namenode,对于hbase则保证只有一个HMaster,而对于kafka来说则需要保证对每一个topic下面的partition都有一个leader去控制该partition的所有处理过程并且在该leader失效时候完成新的leader选举。综上所言,zookeeper完成的是集群的配置管理工作,确保集群的特性!可以得出zookeeper实现了一个分布式锁。当指定了集群的管理者后,对数据的处理只能有该管理者操作,确保了多机器数据操作的正确性。
zookeeper为什么可以做到?
zookeeper集群存在两种角色leader与learner,learner角色分为observer与follower。无论任何机器的数据有变更,都会将信息同步到其它机器。
作为leader职责有负责投票的发起与决议,更新系统状态
作为observer职责有接收客户端请求,将写请求转发给leader,只同步leader的状态不参与投票,目的是提高读取速度。
作为follower职责有接收客户端请求并返回结果,参与选举投票.每一个zookeeper都可以作为服务端为客户端提供服务,所有的写请求都会转发给leader,由leader指定follower完成数据写请求。由于每台zookeeper机器都有所有信息的副本,因此读请求可以直接在该zookeeper上进行。
作为写请求,zookeeper会将写同步到所有节点,zookeeper采用一个自定义的信息原子操作协议,保证zookeeper本地的副本不会出现不一致现象。当leader接收到一个写请求,它会计算写之后的状态,封装成一个事务进行。
zookeeper怎样做到?
zookeeper拥有层次的命名空间,和linux文件系统类似,但是zookeeper的znode兼具文件和目录的特点,既可以存储数据又可以索引下级节点。我们看一看kafka使用的zookeeper节点信息。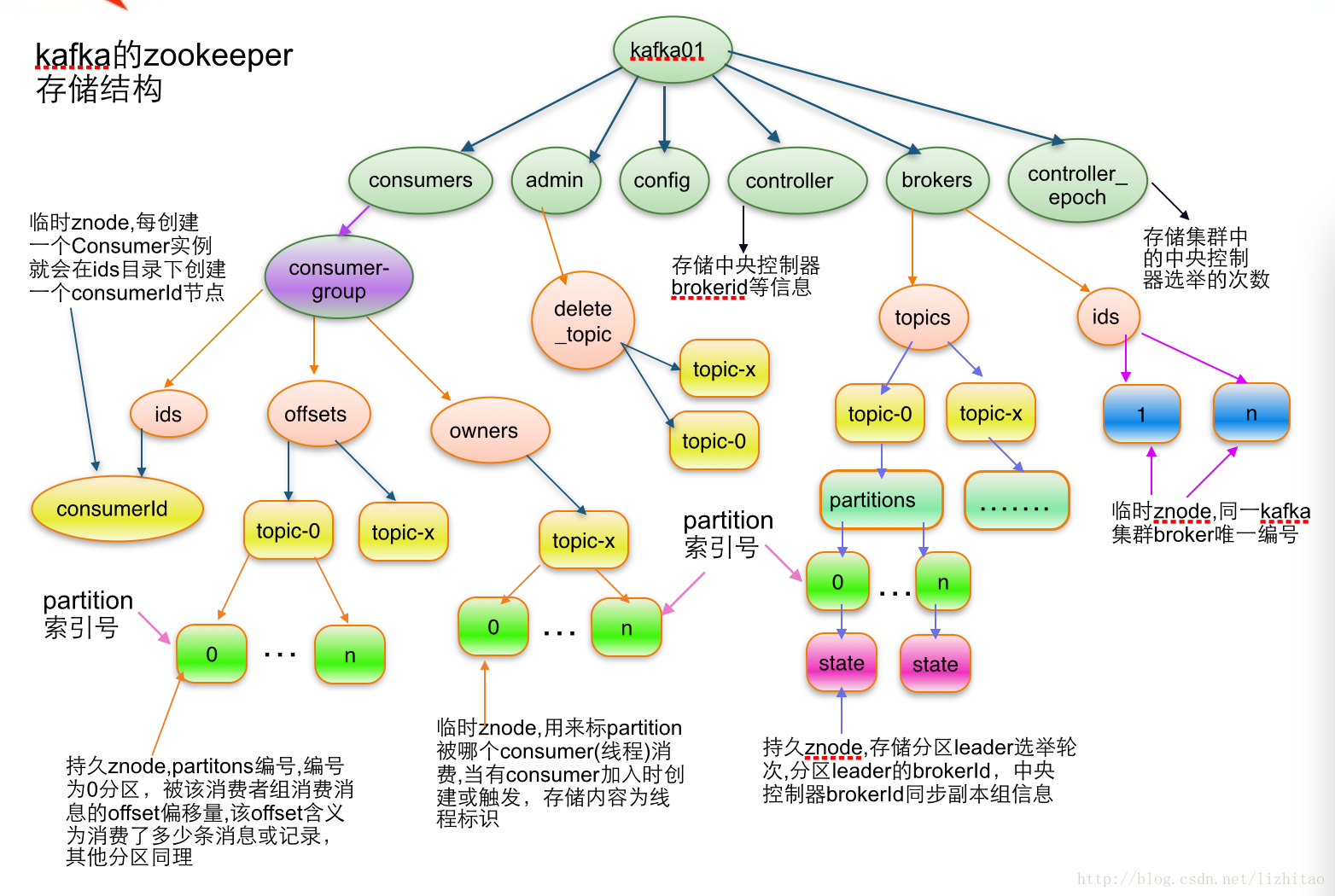
图中每个节点是一个znode,每个znode又三部分组成:
stat: znode的版本,权限等信息
data: znode的关联数据
children: znode的子节点
znode是客户端访问znode的主要实体。客户端可以通过各种操作来控制znode信息。首先我们可以在节点上设置watch,当节点发生变化时候,会触发watch所对应的操作,zookeeper会向客户端发送且只发送一条消息(watch只能被触发一次);其次znode的节点操作都是原子性的,读取会读所有信息,写会替换节点的所有数据,节点也会有自己的ACL去规定用户的访问权限;最后znode存在两种节点,临时节点与永久节点,对于kafka而言,每台kafka作为zookeeper的客户端,信息注册在znode中作为一类临时节点,临时节点与客户端有关联,生命周期依赖创建它们的会话,一旦会话结束,临时节点会自动删除。这也就解释了zookeeper为什么能够感知节点下线。
综上所言可以得知,zookeeper管理的命名空间可以完成分布式集群的控制管理。其最大的特点在于进行leader选取和配置控制,原子性的操作可以保证写一致性,多集群又可以保证高效的读。
- zookeeper学习点
- zookeeper 学习记录4(项目使用几点小结)
- Zookeeper学习9_zookeeper项目使用几点小结
- zookeeper注意几点
- zookeeper注意几点
- zookeeper那点事
- zookeeper技术点介绍
- zookeeper安装注意点
- zookeeper学习
- ZooKeeper学习
- zookeeper学习
- zookeeper学习
- zookeeper 学习
- zookeeper学习
- Zookeeper学习
- zookeeper学习
- Zookeeper学习
- zookeeper学习
- 自定义view onMeaure
- map沉淀复制/reduce滚雪球
- python之路——函数式编程
- jquery.printArea改进
- 人工智能+
- zookeeper学习点
- c++ winpcap开发(5)
- 自定义Dialog
- MySQL事务的可串行化
- 一分钟了解“matlab把一个矩阵矩阵范围拉伸到minVal~maxVal的范围内”
- TensorFlow 之命令行参数
- SHUOJ几队周尼玛
- 日常问题总结 一
- Performance Comparison of H.265_MPEG-HEVC, VP9, and H.264/MPEG-AVC Encoders


