学习mongodb笔记(四)——查询
来源:互联网 发布:淘宝主图视频手机拍摄 编辑:程序博客网 时间:2024/05/21 22:23
MongoDB 查询文档使用 find() 方法。除了 find() 方法之外,还有一个 findOne() 方法,它只返回一个文档。。find() 方法以非结构化的方式来显示所有文档。
MongoDB 查询数据的语法格式如下:
db.collection.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
>db.col.find().pretty()
下面介绍一些常规的用法:
1.1 集合查询方法 find():
find的第一个参数是查询条件,其形式也是一个文档,决定了要返回哪些文档,空的査询文档{}会匹配集合的全部内容。要是不指定査询文档,默认就是{},如同SQL中"SELECT * FROM TABLENAME"语句。
//将返回集合中所有文档db.collection.find()//或者db.collection.find({})
第一个参数若为键/值对时,查询过程中就意味着执行了条件筛选,就如同我们使用Linq查询数据库一样。下面查询操作将返回user集合中age键值为16的文档集合。
//mongo dbdb.user.find({age:16})//Linq to sqldbContext.user.select(p=>p.age==16)
上面的查询默认执行“==”操作(就如同linq中 p.age==16),文档中若存在相同键的值和查询文档中键的值相等的话,就会返回该文档。
第一个参数若包含多个键/值对(逗号分隔),则相当于查询AND组合条件,“条件1 AND条件2 AND…AND 条件N".例如查询年龄为28且性别为男性的文档集合:
//mongo dbdb.user.find({age:28,sex:"male"})//Linq to sqldbContext.user.select(p=>p.age==28&&p.sex=="male")//SQLSELECT * FROM user WHERE age=28 AND sex="male"
指定返回的键
我们可以通过find 的第二个参数来指定返回的键。
若find不指定第二个参数,查询操作默认返回查询文档中所有键值。像SQL中我们可以指定查询返回字段一样 ,mongo中也可以指定返回的键,这样我们就可以避免查询无用键值查询所消耗的资源、会节省传输的数据量和内存消耗。
集合user包含 _id,name,age,sex,email等键,如果查询结果想只显示集合中的"name"和"age"键,可以使用如下查询返回这些键,。
> db.users.find({}, {"name" : 1, "age" : 1})上面查询结果中,"_id"这个键总是被返回,即便是没有指定也一样。但是我们可以显示的将其从查询结果中移除掉。
> db.users.find({}, {"name" : 1, "age" : 1, "_id":0})
在第二个参数中,指定键名且值为1或者true则是查询结果中显示的键;若值为0或者false,则为不显示键。文档中的键若在参数中没有指定,查询结果中将不会显示(_id例外)。这样我们就可以灵活显示声明来指定返回的键。
我们在使用RDMS时,有时会对表中多个字段之间进行比较。如表store中,有销售数量soldnum和库存数量stocknum两个字段,我们要查询表中销售数量等于库存数量的记录时可以使用下面的sql语句:
SELECT * FROM store WHERE soldnum=stocknum
那么换成mongodb呢,使用find()能实现类似的功能吗?
> db.store.find ({ "soldnum" : "stocknum"})//或者> db.store.find ({ "stocknum":"soldnum" })结果是不行的!!我们可以使用$where运算符来进行相应的操作。
1.2 查询内嵌文档
查询文档有两种方式,一种是完全匹查询,另一种是针对键/值对查询。
> db.profile.find(){ "_id" : ObjectId("51d7b0d436332e1a5f7299d6"), "name" : { "first" : Barack", "last" : "Obama" } }>内嵌文档的完全匹配查询和数组的完全匹配查询一样,内嵌文档内键值对的数量,顺序都必须一致才会匹配:

> db.profile.find({ name : { first : "Barack", last : "Obama" } });{ "_id" : ObjectId("51d7b0d436332e1a5f7299d6"), "name" : { "first" : Barack", "last" : "Obama" } }>//无任何返回值> db.profile.find({ name : { last : "Obama" , first : "Barack"} });>
推荐采用针对键/值对查询,通过点表示法来精确表示内嵌文档的键:
//查询结果一样db.profile.find({ "name.first" : "Barack" , "name.last" : "Obama"});//或者db.profile.find({ "name.last" : "Obama" , "name.first" : "Barack"} );
运行结果:

査询文档可以包含点,来表达“深入内嵌文档内部”的意思,点表示法也是待插入的文档不能包含的原因。当内嵌文档变得复杂后,如键的值为内嵌文档的数组,内嵌文档的匹配需要些许技巧,例如使用$elemMatch操作符。
集合blogs有如下文档:
{ "content" : ".....", "comment" : [ { "author" : "zhangsan", "score" : 3, "comment" : "shafa!" }, { "author" : "lisi", "score" : 5, "comment" : "lzsb!" } ]}
我们想查询评论中用户“zhangsan”是否有评分超过4分的评论内容,但我们利用“点表示法”直接写是有问题的,这条查询条件和数组中不同的文档进行了匹配!
> db.blogs.find({"comment.author":"zhangsan", "comment.score":{"$gte":4}});
上面的结果不是我们期望的,下面使用“$elemMatch”操作符即可将一组条件限定到数组中单条文档的匹配上:
> db.blogs.find({"comment":{"$elemMatch":{"author":"zhangsan","score":{"$gt":4}}}});> db.blogs.find({"comment":{"$elemMatch":{"author":"zhangsan","score":{"$gt":2}}}});
1.3 查询操作符
下面我们将配合查询操作符来执行复杂的查询操作,比如元素查询、 逻辑查询 、比较查询操作。
我们使用下面的比较操作符"$gt" 、"$gte"、 "$lt"、 "$lte"(分别对应">"、 ">=" 、"<" 、"<="),组合起来进行范围的查找。例如查询年龄为16-18岁(包含16但不含18)的用户:
>db.user.find( { age: { $gte: 16 ,$lt:18} } 我们可以使用"$ne"来进行"不相等"操作。例如查询年龄不为18岁的用户:
>db.user.find( { age: {$ne:18} } 精确匹配日期要精确到毫秒,然而我们通常只是想得到关于一天、一周或者是一个月的数据,我们可以使用"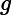
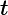
 、
、
lt"进行范围査询。例如,要査找在1990年1月1日出生的用户:
> start = new Date("1990/01/01")> db.users.find({"birthday" : {"$lt" : start}})
键值为null查询操作
如何检索出sex键值为null的文档,我们使用"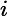
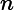 、
、
where"操作符,"$in"判断键值是否为null,"$exists"判定集合中文档是否包含该键。
//集合中有一条sex键值为null的文档{"name":"xiaoming","age":20,"sex":"male"}{"name":"xiaohong","age":22,"sex":"female"}{"name":"lilei","age":24,"sex":null}//返回文档中存在sex键,且值为null的文档 db.users.find({sex:{$in:[null],$exists:true }})//返回文档中存在birthday键,且值为null的文档 //文档没有birthday键,所以结果为空db.users.find({birthday:{$in:[null],$exists:true }})
运行截图:

我们也可以运行如下语句:
> db.users.find({sex:null}) 查询结果跟语句"db.users.find({sex:{
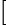

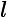


exists:true }})"一样

但是当为我们运行下面语句时,发现查询结果跟语句"db.users.find({birthday:{
exists:true }})"不一样!
> db.users.find({birthday:null})查询返回了所有的文档!

因为null不仅仅匹配自身,而且匹配键“不存在的”文档,集合众文档都不存在"birthday"键,都匹配查询条件,所以上面的语句会返回所有的文档!
我们最好使用db.users.find({sex:{
exists:true }})这种格式。
下面先向集合inventory插入3条数据(下面的演示基于此数据),文档内容如下:
{"name":"t1","amount":16,"tags":[ "school", "book", "bag", "headphone", "appliances" ]}
{"name":"t2","amount":50,"tags":[ "appliances", "school", "book" ]}
{"name":"t3","amount":58,"tags":[ "bag", "school", "book" ]}

"$all"
匹配那些指定键的键值中包含数组,而且该数组包含条件指定数组的所有元素的文档,数组中元素顺序不影响查询结果。
语法: { field: { $all: [ <value> , <value1> ... ] }查询出在集合inventory中 tags键值包含数组,且该数组中包含appliances、school、 book元素的所有文档:
db.inventory.find( { tags: { $all: [ "appliances", "school", "book" ] } } )该查询将匹配tags键值包含如下任意数组的所有文档:
[ "school", "book", "bag", "headphone", "appliances" ][ "appliances", "school", "book" ]查询结果:

文档中键值类型不是数组,也可以使用$all操作符进行查询操作,如下例所示"$all"对应的数组只有一个值,那么和直接匹配这个值效果是一样的。
//查询结果是相同的,匹配amount键值等于50的文档db.inventory.find( { amount: {$all:[50]}} )db.inventory.find( { amount: 50}} )

要是想查询数组指定位置的元素,则需使用key.index语法指定下标,例如下面查询出tags键值数组中第2个元素为"school"的文档:
> db.inventory.find({"tags.1":"school"})数组下标都是从0开始的,所以查询结果返回数组中第2个元素为"school"的文档:

"$size"
语法:{field: {$size: value} }查询集合中tags键值包含有3个元素的数组的所有文档:
> db.inventory.find({tags:{$size:3}})文档"{"name":"t1","amount":16,"tags":[ "school", "book", "bag", "headphone", "appliances" ]}",tags键值数组包含四个元素,所以不匹配查询条件。查询结果:

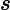
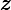
 必须制定一个定值,不能接受一个范围值,不能与其他查询子句组合
必须制定一个定值,不能接受一个范围值,不能与其他查询子句组合 比如
比如
gt")。但有时查询需求就是需要一个长度范围,这种情况创建一个计数器字段,当你增加元素的同时增加计数器字段值。
//每一次向指定数组添加元素的时候,"count"键值增加1(充当计数功能)db.collection.update({ $push : {field: value}, $inc :{count : 1}})//比较count键值实现范围查询db.collection.find({count : {$gt:2}})
"$in"
语法: { field: { $in: [<value1>, <value2>, ... <valueN> ] } }"$nin"
匹配键不存在或者键值不等于指定数组的任意值的文档。类似sql中not in(SQL中字段不存在使用会有语法错误).
语法: { field: { $nin: [ <value1>, <value2> ... <valueN> ]} }
查询出amount键值为16或者50的文档:
db.inventory.find( { amount: { $in: [ 16, 50 ] } } )
//查询出amount键值不为16或者50的文档db.inventory.find( { amount: { $nin: [ 16, 50 ] } } )//查询出qty键值不为16或50的文档,由于文档中都不存在键qty,所以返回所有文档db.inventory.find( { qty: { $nin: [ 16, 50 ] } } )

文档中键值类型不是数组,也可以使用$all操作符进行查询操作,如下例所示"$in"对应的数组只有一个值,那么和直接匹配这个值效果是一样的。
//查询结果是相同的,匹配amount键值等于50的文档db.inventory.find( { amount: {$in:[50]}} )db.inventory.find( { amount: 50}} )
"$and"
指定一个至少包含两个表达式的数组,选择出满足该数组中所有表达式的文档。$and操作符使用短路操作,若第一个表达式的值为“false”,余下的表达式将不会执行。
语法: { $and: [ { <expression1> }, { <expression2> } , ... , { <expressionN> } ] }查询name键值为“t1”,amount键值小于50的文档:
db.inventory.find({ $and: [ { name: "t1" }, { amount: { $lt:50 } } ] } )
对于下面使用逗号分隔符的表达式列表,MongoDB会提供一个隐式的$and操作:
//等同于{ $and: [ { name: "t1" }, { amount: { $lt:50 } } ] } db.inventory.find({ name: "t1" , amount: { $lt:50 }} )

"$nor"
执行逻辑NOR运算,指定一个至少包含两个表达式的数组,选择出都不满足该数组中所有表达式的文档。
语法: { $nor: [ { <expression1> }, { <expression2> }, ... { <expressionN> } ] }查询name键值不为“t1”,amount键值不小于50的文档:
db.inventory.find( { $nor: [ { name: "t1" }, { qty: { $lt: 50 } } ] } )
若是文档中不存在表达式中指定的键,表达式值为false; false nor false 等于 true,所以查询结果返回集合中所有文档:
db.inventory.find( { $nor: [ { sale: true }, { qty: { $lt: 50 } } ] } )
"$not"
执行逻辑NOT运算,选择出不能匹配表达式的文档 ,包括没有指定键的文档。$not操作符不能独立使用,必须跟其他操作一起使用(除$regex)。
语法: { field: { $not: { <operator-expression> } } }查询amount键值不大于50(即小于等于50)的文档数据
db.inventory.find( { amount: { $not: { $gt: 50 } } } ) //等同于db.inventory.find( { amount: { $lte: 50 } } )

查询条件中的键gty,文档中都不存在无法匹配表示,所以返回集合所有文档数据。
db.inventory.find( { gty: { $not: { $gt: 50 } } } ) 
"$or"
执行逻辑OR运算,指定一个至少包含两个表达式的数组,选择出至少满足数组中一条表达式的文档。
语法: { $or: [ { <expression1> }, { <expression2> }, ... , { <expressionN> } ] }查询集合中amount的键值大于50或者name的键值为“t1”的文档:
db.inventory.find( { $or: [ { amount: { $gt: 50 } }, { name: "t1" } ] } )
"$exists"
如果$exists的值为true,选择存在该字段的文档;若值为false则选择不包含该字段的文档(我们上面在查询键值为null的文档时使用"$exists"判定集合中文档是否包含该键)。
语法: { field: { $exists: <boolean> } }
//查询不存在qty字段的文档(所有文档)db.inventory.find( { qty: { $exists: false } })//查询amount字段存在,且值不等于16和58的文档db.inventory.find( { amount: { $exists: true, $nin: [ 16, 58 ] } } )

如果该字段的值为null,$exists的值为true会返回该条文档,false则不返回。
//向集合中插入一条amount键值为null的文档{"name":"t4","amount":null,"tags":[ "bag", "school", "book" ]}//0条数据db.inventory.find( { amount: { $exists: false } } )//所有的数据db.inventory.find( { amount: { $exists: true } } )

"$mod"
匹配字段值对(divisor)取模,值等于(remainder)的文档。
语法: { field: { $mod: [ divisor, remainder ]} }查询集合中 amount 键值为 4 的 0 次模数的所有文档,例如 amount 值等于 16 的文档
db.inventory.find( { amount: { $mod: [ 4, 0 ] } } )
有些情况下(特殊情况键值为null时),我们可以使用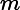

 操作符替代使用求模表达式的
操作符替代使用求模表达式的
where操作符,因为后者代价昂贵。
db.inventory.find( { $where: "this.amount % 4 == 0" } )
注意:返回结果怎么不一样。因为有一条文档的amount键值为null,javascript中null进行数值转换,会返回"0"。所以该条文档匹配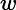
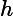
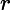 操作符求模式了表达式。当文档中字段值不存在,就可以使用
操作符求模式了表达式。当文档中字段值不存在,就可以使用
mod替代$where的表达式.
"$regex"
操作符查询中可以对字符串的执行正则匹配。 MongoDB使用Perl兼容的正则表达式(PCRE)库来匹配正则表达式.
我们可以使用正则表达式对象或者$regex操作符来执行正则匹配:
//查询name键值以“4”结尾的文档db.inventory.find( { name: /.4/i } );db.inventory.find( { name: { $regex: '.4', $options: 'i' } } );

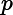 (使用
(使用
regex )
- i 如果设置了这个修饰符,模式中的字母会进行大小写不敏感匹配。
- m 默认情况下,PCRE 认为目标字符串是由单行字符组成的(然而实际上它可能会包含多行).如果目标字符串 中没有 "\n"字符,或者模式中没有出现“行首”/“行末”字符,设置这个修饰符不产生任何影响。
- s 如果设置了这个修饰符,模式中的点号元字符匹配所有字符,包含换行符。如果没有这个修饰符,点号不匹配换行符。
- x 如果设置了这个修饰符,模式中的没有经过转义的或不在字符类中的空白数据字符总会被忽略,并且位于一个未转义的字符类外部的#字符和下一个换行符之间的字符也被忽略。 这个修饰符使被编译模式中可以包含注释。 注意:这仅用于数据字符。 空白字符 还是不能在模式的特殊字符序列中出现,比如序列 。
注:JavaScript只提供了i和m选项,x和s选项必须使用$regex操作符。
"$where"
操作符功能强大而且灵活,他可以使用任意的JavaScript作为查询的一部分,包含JavaScript表达式的字符串或者JavaScript函数。
新建fruit集合并插入如下文档:
//插入两条数据db.fruit.insert({"apple":1, "banana": 4, "peach" : 4})db.fruit.insert({"apple":3, "banana": 3, "peach" : 4})
比较文档中的两个键的值是否相等.例如查找出banana等于peach键值的文档(4种方法):
//JavaScrip字符串形式db.fruit.find( { $where: "this.banana == this.peach" } )db.fruit.find( { $where: "obj.banana == obj.peach" } )//JavaScript函数形式db.fruit.find( { $where: function() { return (this.banana == this.peach) } } )db.fruit.find( { $where: function() { return obj.banana == obj.peach; } } )

查出文档中存在的两个键的值相同的文档,JavaScript函数会遍历集合中的文档:
>db.fruit.find({$where:function () { for (var current in this) { for (var other in this) { if (current != other && this[current] == this[other]) { return true; } } } return false; }});
注意:我们尽量避免使用" 査询,因为它们在速度上要比常规査询慢很多。每个文档都要从
査询,因为它们在速度上要比常规査询慢很多。每个文档都要从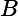
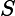

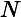 转换成
转换成
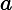
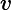
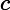 对象,然后通过
对象,然后通过
where"的表达式来运行;同样还不能利用索引。
"$slice (projection)"
$slice操作符控制查询返回的数组中元素的个数。
语法:db.collection.find( { field: value }, { array: {$slice: count } } );此操作符根据参数"{ field: value }" 指定键名和键值选择出文档集合,并且该文档集合中指定"array"键将返回从指定数量的元素。如果count的值大于数组中元素的数量,该查询返回数组中的所有元素的。
$slice接受多种格式的参数 包含负数和数组:
//选择comments的数组键值中前五个元素。db.posts.find( {}, { comments: { $slice: 5 } } );//选择comments的数组键值中后五个元素。db.posts.find( {}, { comments: { $slice: -5 } } );
下面介绍指定一个数组作为参数。数组参数使用[ skip , limit ] 格式,其中第一个值表示在数组中跳过的项目数,第二个值表示返回的项目数。
//选择comments的数组键值中跳过前20项之后前10项元素db.posts.find( {}, { comments: { $slice: [ 20, 10 ] } } );//选择comments的数组键值中倒数第20项起前10项元素db.posts.find( {}, { comments: { $slice: [ -20, 10 ] } } );
"$elemMatch(projection)"
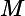 投影操作符将限制查询返回的数组字段的内容只包含匹配
投影操作符将限制查询返回的数组字段的内容只包含匹配
elemMatch条件的数组元素。
注意:
- 数组中元素是内嵌文档。
- 如果多个元素匹配$elemMatch条件,操作符返回数组中第一个匹配条件的元素。
假设集合school有如下数据:
{ _id: 1, zipcode: 63109, students: [ { name: "john", school: 102, age: 10 }, { name: "jess", school: 102, age: 11 }, { name: "jeff", school: 108, age: 15 } ]}{ _id: 2, zipcode: 63110, students: [ { name: "ajax", school: 100, age: 7 }, { name: "achilles", school: 100, age: 8 }, ]}{ _id: 3, zipcode: 63109, students: [ { name: "ajax", school: 100, age: 7 }, { name: "achilles", school: 100, age: 8 }, ]}{ _id: 4, zipcode: 63109, students: [ { name: "barney", school: 102, age: 7 }, ]}
下面的操作将查询邮政编码键值是63109的所有文档。 $elemMatch操作符将返回 students数组中的第一个匹配条件(内嵌文档的school键且值为102)的元素。
db.school.find( { zipcode: 63109 },{ students: { $elemMatch: { school: 102 } } } );查询结果:
_id为1的文档,students数组包含多个元素中存在school键且值为102的元素,$elemMatch只返回一个匹配条件的元素。
_id为3中的文档,因为students数组中元素无法匹配$elemMatch条件,所以查询结果不包含"students"字段。

$elemMatch可以指定多个字段的限定条件,下面的操作将查询邮政编码键值是63109的所有文档。 $elemMatch操作符将返回 students数组中的第一个匹配条件(内嵌文档的school键且值为102且age键值大于10)的元素。
db.school.find( { zipcode: 63109 },{ students: { $elemMatch: { school: 102, age: { $gt: 10} } } } );_id等于3 和4的文档,因为students数组中没有元素匹配的$elemMatch条件,查询结果不包含“ students”字段。

1.4.1 游标
数据库使用游标返回find的执行结果。客户端对游标的实现通常能够对最终结果进行有效控制,从shell中定义一个游标非常简单,就是将查询结果分配给一个变量(用var声明的变量就是局部变量),便创建了一个游标,如下所示:
这么做的好处就是可以一次查看一条结果。如果将上面查询结果放在全局变量中或者根本就没有放在变量中,MongoDB shell会自动迭代,自动显示最开始的若干文档。可以使用游标的next()方法获得下一条数据。使用hasNext()方法查看游标里面是否还有数据。
调用find()方法时,shell并不立即查询数据库,而是等待真正开始要求获得结果时才发送查询,这样在执行之前可以给查询附加额外的选项。几乎游标对象的每个方法都返回游标本身,这样就可以按任意顺序组成方法链。例如,下面几种表达式是等价的。
- > var cursor=db.users.find().sort({"age":1}).limit(10).skip(10)
- > var cursor=db.users.find().skip(10).limit(10).sort({"age":1})
此时上面的查询还没有向数据库发送请求,他们只是在构造查询。现在,假设我们执行如下操作:
- > cursor.hasNext()
这时,查询被发往服务器。shell立刻获得100条数据或者前4M数据(两种之间取小者),这样下次调用next或者hasNext时就不必再次连接服务器获取结果了。当客户端用光了第一组结果,shell会再一次联系数据库。
1.4.2、游标的生命周期
看待游标有两种角度:“客户端游标”以及“客户端请求过去的服务器端游标”,在服务器端,游标消耗内存和其他资源。所以我们讨论就讨论服务器端的,客户端的没有什么意义。当客户端向服务器发起一次查询find()就代表在服务器端创建了一个游标,下面三种情况会让游标销毁。
- 当游标遍历尽了以后,或者客户端发来消息要求终止,数据库会释放这些资源。
- 当客户端的游标不在作用域内时,驱动程序会向服务器发送一条特别消息,让其销毁游标。
- 当服务器端10分钟以内不对游标进行操作,即使客户端游标在作用域内或者还没有迭代完,数据库也会自动销毁游标。
1.4.3、imit、skip和sort
- limit:用来限制返回的结果,返回匹配文档的上限
- skip:跳过前面多少个文档
- sort : 排序的参数
这些选项必须在查询发送到服务器之前指定
参考实例:分页查询users集合的第二页每页10条记录,并指定对age进行升序
- > var cursor=db.users.find().skip(10).limit(10).sort({"age":1})
- > cursor.forEach(function(user){
- ... print("userName:"+user.name+" age:"+user.age);
- ... });
返回结果如下:
- userName:user2088 age:11
- userName:user2212 age:12
- userName:user2371 age:13
- userName:user2655 age:14
- userName:user2681 age:15
- userName:user2855 age:16
- userName:user3186 age:17
- userName:user3332 age:18
- userName:user3383 age:19
- userName:user3465 age:20
1.4.4、怎么对mongodb进行分页
当使用skip略过少量文档还是不错的。但是要是数量非常多的话,skip会变得相当慢,例如想返回第10000页(每页20条记录),MongoDB必须先找到200000条记录,然后再抛弃199920条数据,这种分页需求在业内也有一个名词叫做“深分页”。大多数数据库都会再索引中保存更多的元数据,用于处理skip(Solr 4.7.1也引入了游标处理这种深分页),所以要尽量避免滤过太多数据。
既然MongoDB的skip不适合做深分页,那怎么做呢?
答:MongoDB能不能做深分页这取决于查询本身。
根据一般业务来讲,可以找到一种方法在不使用skip的情况下实现分页,这主要取决于查询本身。
参考实例
例如要按照"date"降序显示文档列表。可以按照如下方式获取结果的第一页:
- > db.users.find().sort({"create":-1}).limit(10)
然后利用上次查询的最后一个文档中的"date"值作为查询条件,来获取下一页:
- var lastTime=users.last.date;--这个可以根据实际情况获得,我这里只是随便写写,让你感受到这种思想。
获取下一页:
- db.users.find({"create":{"$gt":lastTime}}).sort("create":-1}).limit(10)
这种分页查询中就没有了skip了。
优化深分页的核心思想(包括关系型数据库,以及其他NoSql数据库):减少当前查询在结果集里面存放的数据。
- 学习mongodb笔记(四)——查询
- MongoDB学习笔记(四)MongoDB查询集合中的文档
- 学习MongoDB 四: MongoDB查询(一)
- mongodb 学习四(查询实战部分)MongoDB嵌套查询
- MongoDB学习笔记<四>
- mongoDB学习笔记四
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB学习笔记(查询)
- MongoDB 学习笔记(四):索引
- Qt动态类型转换
- 动态规划(2)
- #424
- 【Java集合源码剖析】TreeMap源码剖析
- 深入理解Java:类加载机制及反射
- 学习mongodb笔记(四)——查询
- numpy 索引array的骚操作
- QString 类型转换
- 【数论】埃氏筛
- 汇编角度看C中的堆与栈
- Cnskype for Business即时协同办公对公司沟通的重要性
- 硬件电路设计报告总结
- 日志定时压缩清理shell脚本(日志文件后缀格式如xxxxx.log.2017-07-10)
- AngularJS 控制器


