solr学习(4.1)-solr4.7中文分词器(ik-analyzer)配置
来源:互联网 发布:淘宝上全球购什么意思 编辑:程序博客网 时间:2024/05/16 16:56
solr本身对中文分词的处理不是太好,所以中文应用很多时候都需要额外加一个中文分词器对中文进行分词处理,ik-analyzer就是其中一个不错的中文分词器。
一、版本信息
solr版本:4.7.0
需要ik-analyzer版本:IK Analyzer 2012FF_hf1
ik-analyzer下载地址:http://code.google.com/p/ik-analyzer/downloads/list
二、配置步骤
下载压缩解压后得到如下目录结构的文件夹:

我们把IKAnalyzer2012FF_u1.jar拷贝到solr服务的solr\WEB-INF\lib下面。
我们把IKAnalyzer.cfg.xml、stopword.dic拷贝到需要使用分词器的core的conf下面,和core的schema.xml文件一个目录。

修改core的schema.xml,在<types></types>配置项间加一段如下配置:
<!-- 我添加的IK分词 --> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType>
我们就多了一种text_ik的field类型了,该类型使用的分词器就是ik-analyzer。
我们在这个core的schema.xml里面配置field类型的时候就可以使用text_ik了,同时,把需要分词的字段,比如name字段type设置为text_ik,

<field name="name" type="text_ik" indexed="true" stored="true" required="true" multiValued="false" />
修改完后,需要重启solr相关的服务。
4. 重启服务
注意:如果之前已经创建了索引,需要将之前的索引删掉,重新创建分词后的索引。
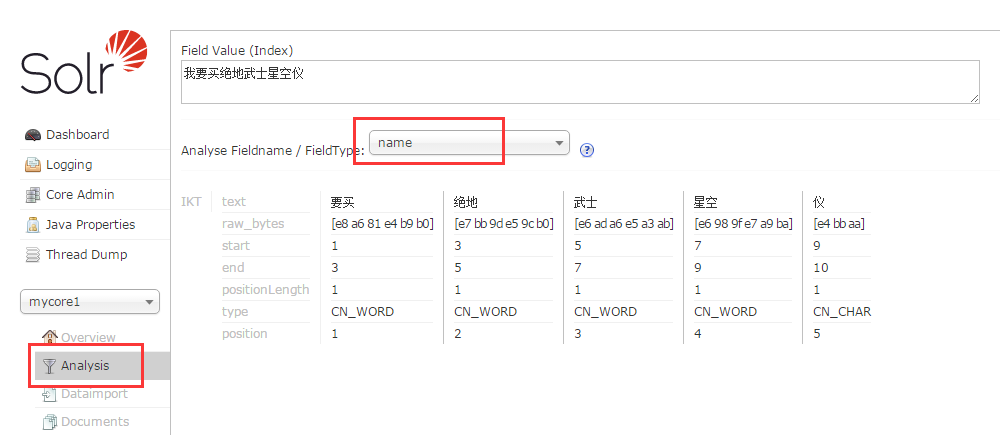
5. 在admin后台, analysis 下查看分词效果
1. 中文分词效果
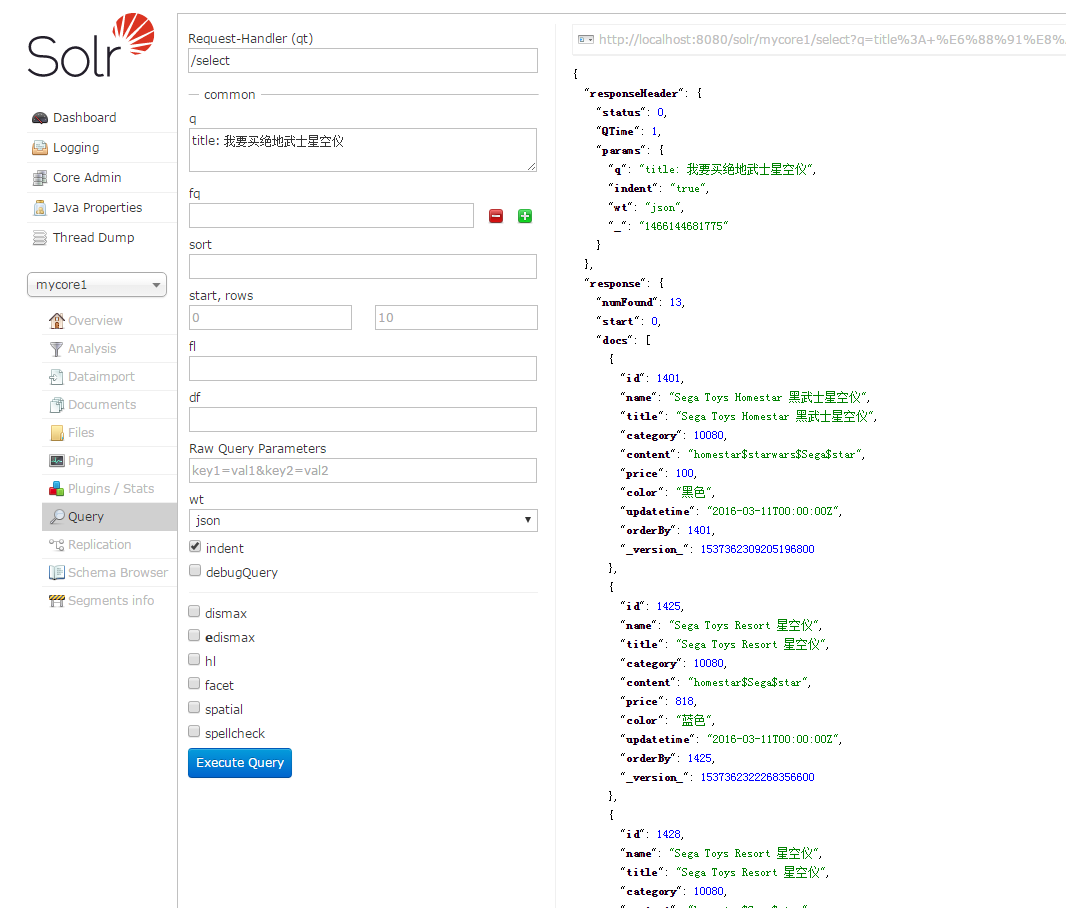
2. 索引查询效果
6. 配置IKAnalyzer分词器的扩展词典,停止词词典
1. 将 文件夹下的IKAnalyzer.cfg.xml , ext.dic和stopword.dic 三个文件 复制到/webapps/solr/WEB-INF/classes 目录下,并修改IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 扩展配置</comment> <!--用户可以在这里配置自己的扩展字典 --> <entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> </properties>
2. 在ext.dic 里增加自己的扩展词典,例如,婴儿奶粉3段
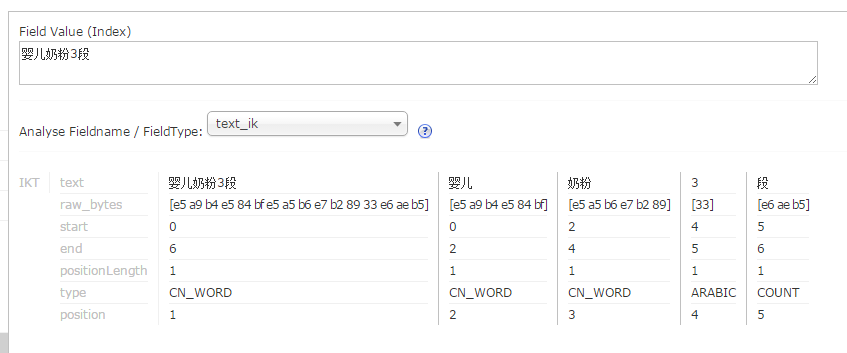
注意: 记得将stopword.dic,ext.dic的编码方式为UTF-8 无BOM的编码方式。
- solr学习(4.1)-solr4.7中文分词器(ik-analyzer)配置
- solr4.7中文分词器(ik-analyzer)配置
- solr4.7中文分词器(ik-analyzer)配置
- solr4.7中文分词器(ik-analyzer)配置
- solr4.7中文分词器(ik-analyzer)配置
- solr4.7中文分词器(ik-analyzer)配置
- solr4.7中文分词器(ik-analyzer)配置
- solr配置中文分词器IK Analyzer
- solr配置中文IK Analyzer分词器
- Solr学习之十二:IK Analyzer中文分词配置
- Solr配置中文分词器IK Analyzer详解
- solr中MMSEG4j、IK Analyzer中文分词器安装配置
- Solr配置中文分词器IK Analyzer详解
- 爬坑 solr-4.10 配置中文分词器ik-analyzer
- solr-4.6配置中文分词器ik-analyzer
- Solr 5.0.0配置中文分词器IK Analyzer
- Solr配置IK Analyzer分词器
- (二)solr-4.5.1中文分词器(IK-Analyzer)配置
- 群体智能——粒子仿真系统
- hdu1002
- Git服务器端配置
- linux复习——I/O复用
- JUC集合-01之 总体框架
- solr学习(4.1)-solr4.7中文分词器(ik-analyzer)配置
- 机器学习算法(八)贝叶斯算法族、朴素贝叶斯
- JDBC连接数据库代码和步骤
- HDU 1242
- 广度优先搜索解决迷宫问题
- Datawindow Grid风格放按钮时不触发buttonclick事件
- php截取字符串(中文字符截取mb_substr)
- 使用GDB调试Android NDK native程序
- JUC集合-01之 框架补充


