矩阵分解在推荐系统的应用以及python代码的实现
来源:互联网 发布:善用佳软 知乎 编辑:程序博客网 时间:2024/05/19 20:42
矩阵分解在打分预估系统中得到了成熟的发展和应用,为了方便以后复习,先总结如下。
打分矩阵R(n,m)是n行和m列,n表示user个数,m行表示item个数,例如R(5,6)
item1item2item3item4item5item6
user1 544350
user2 045 031
user3540 130
user4045315
user5103 505
其中,为了表示方便0表示没有打分,根据目前的矩阵R(5,6)如何得到分值为0的用户的打分值?
矩阵分解的思想可以解决这个问题,其实这种思想可以看作是有监督的机器学习问题
具体的:
R(n,m)~=P(n,K)*Q(K,m)
其中 ~=表示约等于(由于编辑器使用的不熟悉),矩阵P(n,K)表示n个user和K个特征之间的关系矩阵,这K个特征是一个中间变量,矩阵Q(K,m)的转置是矩阵Q(m,K),矩阵Q(m,K)表示m个item和K个特征之间的关系矩阵,这里的K值是自己控制的,可以使用交叉验证的方法获得最佳的K值。为了得到近似的R(n,m),必须求出矩阵P和Q,怎么求它们呢?
令
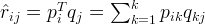
如果R(i,j)已知,则R(i,j)的误差平方和为
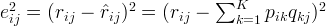
为了防止过拟合,增加正则化项:
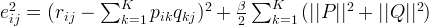
使用梯度下降法获得修正的p和q分量:
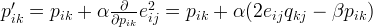 纠错:中间等式前面的alph前面应该是负号,代表负梯度方向
纠错:中间等式前面的alph前面应该是负号,代表负梯度方向
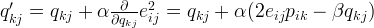 纠错:中间等式前面的alph前面应该是负号,代表负梯度方向
纠错:中间等式前面的alph前面应该是负号,代表负梯度方向
不停的迭代直到sum(e^2) <=阈值,
K=2 得到结果是
item1 item2 item4 item5item6 item7
user1 [[ 5.25600533 4.30482789 4.76151949 2.04197028 3.77745497 1.59709987]
user2 [ 4.92136216 3.986272 4.40232802 1.81776335 3.57447488 1.37667655]
user3 [ 4.70259529 3.66136084 4.02053168 1.42409487 3.54021725 0.92110655]
user4 [ 3.24257645 3.95178917 4.57037303 4.00482228 1.23685399 4.44552925]
user5 [ 0.94314043 2.66249238 3.23566396 4.36964834 -0.91695287 5.33276304]]
K=3 得到结果是
item1 item2 item4 item5item6 item7
user1 [[ 5.35081468 4.21628989 3.92966236 2.8616707 4.42764467 3.67424467]
user2 [ 3.65150782 4.00536042 4.98203391 -0.24263616 2.84660098 1.11289902]
user3 [ 4.55129228 3.73496981 3.86823535 1.11434568 3.71657794 2.03034916]
user4 [ 1.57844524 3.97142414 5.03277248 3.35320963 1.08371548 4.62480722]
user5 [ 0.93799194 2.70958606 2.97752303 4.67356409 0.67601902 5.28834503]]
python 源代码如下:
import numpydef matrix_factorization(R, P, Q, K, steps=5000, alpha=0.0002, beta=0.02): Q = Q.T for step in xrange(steps): for i in xrange(len(R)): for j in xrange(len(R[i])): if R[i][j] > 0: eij = R[i][j] - numpy.dot(P[i,:],Q[:,j]) for k in xrange(K): P[i][k] = P[i][k] + alpha * (2 * eij * Q[k][j] - beta * P[i][k]) Q[k][j] = Q[k][j] + alpha * (2 * eij * P[i][k] - beta * Q[k][j]) eR = numpy.dot(P,Q) e = 0 for i in xrange(len(R)): for j in xrange(len(R[i])): if R[i][j] > 0: e = e + pow(R[i][j] - numpy.dot(P[i,:],Q[:,j]), 2) for k in xrange(K): e = e + (beta/2) * ( pow(P[i][k],2) + pow(Q[k][j],2) ) if e < 0.001: break return P, Q.T###############################################################################if __name__ == "__main__": R = [ [5,4,4,3,5,0], [0,4,5,0,3,1], [5,4,0,1,3,0], [0,4,5,3,1,5], [1,0,3,5,0,5], ] R = numpy.array(R) N = len(R) M = len(R[0]) K = 2 P = numpy.random.rand(N,K) Q = numpy.random.rand(M,K) nP, nQ = matrix_factorization(R, P, Q, K) print R T = numpy.dot(nP,nQ.T) print T
参考文章:http://www.quuxlabs.com/blog/2010/09/matrix-factorization-a-simple-tutorial-and-implementation-in-python/#source-code
adding biases
然而,上面仅仅考虑了q和p直接相互影响,而没有考虑user和item项目本身的属性,比如,总体的平均分是all_mean,
user是一位严厉的顾客,那么打分自然要低于打分的平均分,一个item比其他item更流行,其得分高于打分的
平均分,则:
r_exp(u,i) = u + b(i) + b(u) + q(i)p(u)

其中 u是所有打过分的打分item的打分的平均值,b(i)为item比平均值的偏差,b(u)表示个人打分习惯和
平均打分的偏差
优化目标函数是:
min ∑ (r(u,i) - all_mean - b(u) - b(i) - p(u)q(i))^2 + lamda*(||p(u)||^2 + ||q(i)||^2 + (b(u))^2 + (b(i))^2)参考文章:matrix factorization techniques for recommender systems该源代码在我的github,https://github.com/zhangqianjin/recommender-system/ ,欢迎大家交流学习
- 矩阵分解在推荐系统的应用以及python代码的实现
- 矩阵分解在推荐系统的应用
- 矩阵分解在推荐系统中的应用
- 矩阵分解在推荐系统中的应用
- 矩阵分解在推荐系统中的应用
- 矩阵分解在推荐系统中的应用
- 基于矩阵分解的推荐算法(java代码实现)
- 基于矩阵分解的推荐系统
- 浅谈矩阵分解在推荐系统中的应用
- 浅谈矩阵分解在推荐系统中的应用(转发)
- 浅谈矩阵分解在推荐系统中的应用
- 矩阵分解(MATRIX FACTORIZATION)在推荐系统中的应用
- 浅谈矩阵分解在推荐系统中的应用
- 谈矩阵分解在推荐系统中的应用
- 矩阵分解SVD在推荐系统中的应用
- 浅谈矩阵分解在推荐系统中的应用
- 数据挖掘算法-矩阵分解在推荐系统中的应用
- 浅谈矩阵分解在推荐系统中的应用
- Makefile 文件怎么写
- Spring的Resource的方法
- C/C++ | 27-19 写出程序把一个链表中的接点顺序倒排
- Python学习(三)——字典、有序字典、集合
- Vim代码补全插件YouCompleteMe的自动化安装[转]
- 矩阵分解在推荐系统的应用以及python代码的实现
- tcpcopy的工作原理
- C/C++ | 28-20 写出程序删除链表中的所有节点
- redis windows系统下安装
- H
- HDU 2017 多校联赛2 1001 Is Derek lying?
- Floyd算法
- C/C++ | 29-21 两个字符串,s,t;把t字符串插入到s字符串中,s字符串有足够的空间存放t字符串
- html5


