练习(三)
来源:互联网 发布:金字塔期货交易软件 编辑:程序博客网 时间:2024/06/07 00:57
1、以下程序的输出是
2、针对以下代码,判断下列说法哪个是正确的(注意是地址):______。
3、下列C程序执行后c输出结果为( )
6、下列代码的运行结果是()
8、对于下面的代码,说法正确的是____。
16、哪个操作符不能被重载?
18、下列 C 代码中,不属于未定义行为的有___
20、下面程序的输出结果是21、以下代码输出什么____. 22、由多个源文件组成的C程序,经过编辑、预处理、编译,链接等阶段会生成最终的可执行程序。下面哪个阶段可以发现被调用的函数未定义?23、若要重载+、=、<<、=和[]运算符,则必须作为类成员重载的运算符是
13、
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
classBase { public: Base(intj): i(j) {} virtual~Base() {} voidfunc1() { i *= 10; func2(); } intgetValue() { return i; } protected: virtualvoidfunc2() { i++; } protected: inti;};classChild: publicBase { public: Child(intj): Base(j) {} voidfunc1() { i *= 100; func2(); } protected: voidfunc2() { i += 2; }};intmain() { Base * pb = newChild(1); pb->func1(); cout << pb->getValue() << endl; deletepb; }11
101
12
102
1
2
3
4
constcharstr1[]=”abc”;constcharstr2[]=”abc”;constchar*p1 = “abc”;constchar*p2 = “abc”;str1和str2地址不同,P1和P2地址相同。
str1和str2地址相同,P1和P2地址相同。
str1和str2地址不同,P1和P2地址不同。
str1和str2地址相同,P1和P2地址不同。
1
2
3
4
5
6
7
8
9
#include<stdio.h>#include<stdlib.h>voidmain(){ inta = -3; unsigned intb = 2; longc = a + b; printf("%ld\n",c);}-1
4294967295
0x7FFFFFFF
0xFFFFFFFF
4、Which of the following statements are true?
We can create a binary tree from given inorder and preorder traversal sequences.
We can create a binary tree from given preorder and postorder traversal sequences.
For an almost sorted array, insertion sort can be more effective than Quicksort.
Suppose T(n) is the runtime of resolving a problem with n elements, T(n) = Θ(1) if n = 1; T(n) = 2T(n/2) + Θ(n) if > 1; so T(n) is Θ(n log n).
None of the above.
5、
输出结果是
1
2
3
4
5
6
#define F(X,Y) (X)--, (Y)++, (X)*(Y);…inti, a = 3, b = 4;for( i = 0; i<5; i++) F(a,b) ;printf(“%d, %d”, a, b);3, 4
3, 5
-2, 5
-2, 9

gstrin
string
srting
stirng
7、() 的作用是将源程序文件进行处理,生成一个中间文件,编译系统将对此中间文件进行编译并生成目标代码。
编译预处理
汇编
生成安装文件
编译
1
2
3
4
5
6
char* s1 = "Hello world";chars2[] = "Hello world";s1[2] = 'E'; // 1s2[2] = 'E'; // 2*(s1 + 2) = 'E'; // 3*(s2 + 2) = 'E'; // 4语句2、4是非法的
语句3、4是非法的
语句1、3是非法的
仅语句1是非法的
仅语句2是非法的
语句1~4都是合法的
9、以下代码实现了从表中删除重复项的功能,请选择其中空白行应填入的正确代码()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<typenameT>voidremoveDuplicates(list<T> &aList){ T curValue; list<T>::iterator cur, p; cur = aList.begin(); while(cur != aList.end()) { curValue = *cur; //空白行 while(p != aList.end()) { if(*p == curValue) { //空白行 } else { p++; } } }}p=curr+1;aList.erase(p++);
p=++curr;aList.erase(p++);
p=curr+1;aList.erase(p);
p=++curr;aList.erase(p);
10、以下代码是否完全正确,执行可能得到的结果是____。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
classA{ inti;};classB{ A *p;public: B(){p=newA;} ~B(){deletep;}};voidsayHello(B b){}intmain(){ B b; sayHello(b);}程序正常运行
程序编译错误
程序崩溃
程序死循环
11、在下列排序算法中,哪几个算法的时间复杂度与初始排序无关()
插入排序
堆排序
冒泡排序
归并排序
选择排序
12、关于引用与指针的区别,下面叙述错误的是:
引用必须被初始化,指针不必。
指针初始化以后不能被改变,引用可以改变所指的对象。
删除空指针是无害的,不能删除引用。
不存在指向空值的引用,但是存在指向空值的指针。
13、有如下C++代码:
1
2
3
4
5
6
7
8
9
structA{ voidfoo(){printf("foo");} virtualvoidbar(){printf("bar");} A(){bar();}};structB:A{ voidfoo(){printf("b_foo");} voidbar(){printf("b_bar");}};那么
1
2
3
A *p=newB;p->foo();p->bar();输出为:
barfoob_bar
foobarb_bar
barfoob_foo
foobarb_fpp
14、词法分析器用于识别()
句子
句型
单词
生产式
15、对于派生类的构造函数,在定义对象时构造函数的执行顺序为?
1:成员对象的构造函数
2:基类的构造函数
3:派生类本身的构造函数
1:成员对象的构造函数
2:基类的构造函数
3:派生类本身的构造函数
123
231
321
213
, (逗号)
()
. (点)
[]
->
17、如果A,B,C为布尔型变量,“^”和“v”分别代表布尔类型的“与”和“或”,下面那一项是正确的()
I.A^(BvC)=(A^B)v(A^C)II.Av(B^C)=(AvB)^(AvC)III.(B^A)vC=Cv(A^B)
只有I
只有II
只有I和II
I,II,III;
int i=0;i=(i++);
char *p=”hello”;p[1]=’E’;
char *p=”hello”;char ch=*p++;
int i=0;printf(“%d%d\n”,i++,i--);
都是未定义行为
都不是未定义行为
19、关于struct和class,下列说法正确的是()
struct的成员默认是public,class的成员默认是private
struct不能继承,class可以继承
struct可以有无参构造函数
struct的成员变量只能是public
1
2
3
char*p1= “123”, *p2 = “ABC”, str[50]= "xyz";strcpy(str+2,strcat(p1,p2));cout << str;xyz123ABC
z123ABC
xy123ABC
出错
1
2
3
4
5
6
main(){ inta[5]={1,2,3,4,5}; int*p=(int*)(&a+1); printf("%d",*(p-1));}1
2
5
出现错误
预处理
编译
链接
执行
+和=
=和<<
==和<<
=和[]
解析:
1、
类的指针指向派生类的对象
基类指针调用其虚成员函数,则会调用其真正指向对象的成员函数,而不是基类中定义的成员函数,若不是虚函数,则不管基类指针指向的是哪个派生对象,调用的都是基类中定义的那个函数
2、
- str1和str2毫无干系,他们都是字符常量数组,恰巧存储的值相同而已。"abc"和str1 str2都存储在常量区。str1 str2的地址就是str1[0] str2[0]的地址,即数组首元素所在的地址。
- 后面的两个“abc”存储在常量区,因为他们是字面值(常量),但是p1 p2存储在栈中。其中p1和p2的值不同,但是他们指向同一块静态存储区域。也就是"abc"的地址。
3、
无符号和有符号整数进行运算时,有符号整数会被提升为无符号整数。
-3对应的二进制表示是0xfffffffd,和2相加表示0xffffffff。
输出结果取决于long是32位,还是64位。这个取决于编译器和机器。
long是有符号的整型。
如果是32位,0xfffffff在补码表示法(最高位是负数位)下是等于-1.
如果是64位,0xfffffff是属于long的正整数范围(负数位在第64位),等于4294967295。
(如果你的编译出来是32位的long,你可以用longlong测试一下就能得到这个数。因为 long long 无论在32位机器或者64位机器都是占用8个字节64位)
4、
常见算法
折半搜索
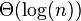 情形二(k = 0)二叉树遍历
情形二(k = 0)二叉树遍历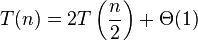
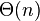 情形一归并排序
情形一归并排序
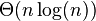 情形二(k = 0)
情形二(k = 0)
情形二(k = 0)二叉树遍历情形一归并排序情形二(k = 0)在算法分析中,主定理(英语:master theorem)提供了用渐近符号表示许多由分治法 得到的递推 关系式的方法。此方法经由经典算法教科书《算法导论》而为人熟知。不过,并非所有递推关系式都可应用主定理。该定理的推广形式包括Akra-Bazzi定理。
假设有递推关系式 ,其中
,其中 为问题规模,
为问题规模, 为递推 的子问题数量,
为递推 的子问题数量, 为每个子问题的规模(假设每个子问题的规模基本一样),
为每个子问题的规模(假设每个子问题的规模基本一样), 为递推 以外进行的计算工作。
为递推 以外进行的计算工作。
a≥1,b>1为常数,f(n) 为函数,T(n) 为非负整数 。则有以下结果:
(1)若 那么
那么
(2)若 那么
那么
(3)若 且对于某个常数
且对于某个常数 和所有充分大 的
和所有充分大 的 有
有 那么
那么
这里是情况2,且a=b,所以有T(n) = O(n logn)
5、
使用宏定义F(x,y) -> #define F(X,Y) (X)--, (Y)++, (X)*(Y)
展开后如下:
inti, a = 3, b = 4;
for( i = 0; i<5; i++)
(a)--,(b)++,(a)*(b);
printf(“%d, %d”, a, b);
(a)--,(b)++,(a)*(b);
是逗号表达式,按从左往右逐个计算表达式,整个表达式最终结果(a)*(b)的值(这部分对a和b值无影响)
计算 了5次for循环的(a)--和(b)++ 的到a=-2,b = 9;
6、
根据栈操作
POP(s,x)是出栈 ,把栈S中出栈一个元素给到x。
Push(s,r)是进栈,让r进入s栈。
栈服从先进后出原则。
7、
这题目有问题!详见 http://m.blog.csdn.net/article/details?id=16820035
这题目有问题!详见 http://m.blog.csdn.net/article/details?id=16820035
8、
指针指向字符串时,字符串是常量,存储在常量区,而指针存储在栈区,不能对其操作修改。
指针指向字符串时,字符串是常量,存储在常量区,而指针存储在栈区,不能对其操作修改。
9、
当使用一个容器的insert或者erase函数通过迭代器插入或删除元素"可能"会导致迭代器失效
iterator失效主要有两种情况:
1、iterator变量已经变成了“野指针”,对它进行*,++,--都会引起程序内存操作异常;
2、iterator所指向的变量已经不是你所以为的那个变量了。
不同的容器,他们erase()的返回值的内容是不同的,有的会返回被删除元素的下一个的iterator,有的则会返回删除元素的个数。
对于非结点类,如数组类的容器 vector,string,deque 容器标准写法是这样:
1
2
3
4
5
6
7
8
9
10
//vector<int> m_vector; for(vector<int>::iterator iter = m_vector.begin(); iter != m_vector.end();){ if(需要删除) { iter=m_vector.erase(iter); } else ++iter;}数组型数据结构:该数据结构的元素是分配在连续的内存中,insert和erase操作,都会使得删除点和插入点之后的元素挪位置,所以,插入点和删除掉之后的迭代器全部失效,也就是说insert(*iter)(或erase(*iter)),然后在iter++,是没有意义的。解决方法:erase(*iter)的返回值是下一个有效迭代器的值。 iter =cont.erase(iter);
对于结点类容器(如:list,map,set)是这样:
1
2
3
4
5
6
7
8
9
10
//map<int,int> m_map;for(map<int,int>::iterator iter = m_map.begin(); iter != m_map.end(); ){ if(需要删除) { m_map.erase(iter++); } else ++iter;}链表型数据结构:对于list型的数据结构,使用了不连续分配的内存,删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.解决办法两种,erase(*iter)会返回下一个有效迭代器的值,或者erase(iter++).
树形数据结构: 使用红黑树来存储数据,插入不会使得任何迭代器失效;删除运算使指向删除位置的迭代器失效,但是不会失效其他迭代器.erase迭代器只是被删元素的迭代器失效,但是返回值为void,所以采用erase(iter++)。
10、
默认的拷贝构造函数是浅拷贝,直接把指针的值复制了一份。
调用sayHello,离开作用域,调用析构函数delete了一次。main函数中,又delete了一次。因此程序崩溃
11、选快希堆不稳(是不稳定的排序), 堆归选基均不变(运行时间不发生变化,与初始状态无关)
12、指针在建立后会被分配一块空间,用于存储其所指向的地址,因为指针是有对应内存空间的,因此指针值(指向的内存空间)是可以改变的;而引用则不行,引用没有内存空间,仅仅是被引对象内存空间的别名,改变引用如&a=4实际上等价于a=4,改变的是被引对象的值,不改变该引用所指的内存空间;
指向空值的引用是没有意义的(因为引用对象不能改变,也就是这个引用永远指向null,那这个引用根本就没有存在的必要);指向空值的指针是有意义的,尤其在指针被删除后,如果不对指针进行赋值,则指针的值将会由系统随机指定,这样后续如果有对指针的操作的话,将会带来很大的风险。因此指针被删除后必须赋值为null;
因为引用无法改变,因此不进行初始化的引用没有意义;因为指针可以改变,因此指针可以不进行初始化,可以在后续程序中动态改变;
总结一下引用和指针的区别:
1、引用是直接访问,指针是间接访问
2、引用是变量的别名,本身不单独分配自己的内存空间。指针有自己的内存空间。
3、引用一旦初始化,不能再引用其他变量。而指针可以!
A *p=newB;// A类指针指向一个实例化对象B, B类继承A类,先调用父类的无参构造函数,bar()输出bar,B类没有自己显示定义的构造函数。
p->foo();//执行B类里的foo()函数,因为foo不是虚函数,所以直接调用父类的foo函数,输出foo
p->bar();//执行B类的bar()函数, 该函数为虚函数,调用子类的实现,输出b_bar
14、词法分析器的工作是低级别的分析:将字符或者字符序列转化成记号.。在谈论词法分析时,使用术语“词法记号”(简称记号)、“模式”和“词法单元”表示特定的含义。
在分析时,一是把词法分析器当成语法分析的一部分,另一种是把词法分析器当成编译程序的独立部分。在前一种情况下,词法分析器不断地被语法分析器调用,每调用一次词法分析器将从源程序的字符序列拼出一个单词,并将其Token值返回给语法分析器。后一种情况则不同,词法分析器不是被语法分析器不断地调用,而是一次扫描全部单词完成编译器的独立一遍任务。
15、理解:1.类的构造函数可能使用类的对象成员,因此类的对象成员→类的构造函数
2.派生类的构造函数可能使用父类的对象成员,因此基类的构造函数→派生类的构造函数
3.析构和构造刚好相反~
16、c++不能重载的运算符有.(点号),::(域解析符),?:(条件语句运算符),sizeof(求字节运算符),typeid,static_cast,dynamic_cast,interpret_cast(三类类型转换符)。
17.
18.
C语言中的未定义行为(Undefined Behavior)是指C语言标准未做规定的行为。同时,标准也从没要求编译器判断未定义行为,所以这些行为有编译器自行处理,在不同的编译器可能会产生不同的结果,又或者如果程序调用未定义的行为,可能会成功编译,甚至一开始运行时没有错误,只会在另一个系统上,甚至是在另一个日期运行失败。当一个未定义行为的实例发生时,正如语言标准所说,“什么事情都可能发生”,也许什么都没有发生。
所以,避免未定义行为,是个明智的决定。本文将介绍几种未定义行为,同时欢迎读者纠错和补充。
1.同一运算符中多个操作数的计算顺序(&&、||、?和,运算符除外)
例如:x = f()+g(); //错误
f()和g()谁先计算由编译器决定,如果函数f或g改变了另一个函数所使用变量的值,那么x的结果可能依赖于这两个函数的计算顺序。
参考: 《C程序设计语言(第2版)》 P43
2.函数各参数的求值顺序
例如: printf("%d,%d\n",++n,power(2,n)); //错误
在不同的编译器可能产生不同的结果,这取决于n的自增运算和power调用谁在前谁在后。
需要注意的是,不要和逗号表达式弄混,都好表达式可以参考这篇文章:c语言中逗号运算符和逗号表达式
参考: 《C程序设计语言(第2版)》 P43
3.通过指针直接修改 const 常量的值
直接通过赋值修改const变量的值,编译器会报错,但通过指针修改则不会,例如:
int main() { const int a = 1; int *b = (int*)&a; *b = 21; printf("%d, %d", a, *b); return 0; }
1
2
3
4
5
6
7
8
9
int main ( )
{
const int a = 1 ;
int * b = ( int * ) & a ;
* b = 21 ;
printf ( "%d, %d" , a , * b ) ;
return 0 ;
}
a输出值也由编译器决定。
19、1.不同点
structclass默认继承权限publicprivate默认数据访问控制publicprivate模板参数不能定义可以用于定义模板参数2.相同点
可以有数据成员,方法,构造函数等。
20、
char* strcat(char *,const char*)//第一个参数所指向的内容必须可以修改,可以赋值为在栈上分配的数组
strcat(p1,p2)试图修改p1的内容,p1指向文字常量区,其指向的内容无法修改
21、选择c,&a表示一个指向大小为5数组的指针,那么&a+1就是表示一个指向大小为5的下一个数组的指针,也就是数组a最后一个元素的下一个位置,那么int*p=(int*)(&a+1)进行强制类型转换,将指向数组的指针转换为指向第二个数组中首元素的指针,所以p-1则是指向第一个数组中最后一个元素的指针,所以输出是5。p定义是int *,p+i或者p-i编译器按p+i*4或p-i*4来算。 &a的类型是 int [5],指向五个int空间的指针,所以a+1编译器做 a地址+4*5来算,那么p-1最后指向a[4] 22、
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//预处理:处理#include、宏替换和条件编译//编译:生成目标文件(.cpp->.o)//链接:链接多个目标文件//例子://main.cppintmain(){ fun();}//编译不可通过,提示函数fun()未声明voidfun();intmain(){ fun();}//编译可通过,链接不可通过,提示函数fun()未定义
23、
(3) 对于复合的赋值运算符如+=、-=、*=、/=、&=、!=、~=、%=、>>=、<<=建议重载为成员函数。
(4) 对于其它运算符,建议重载为友元函数。
(1)只能使用成员函数重载的运算符有:=、()、[]、->、new、delete。
(2)单目运算符最好重载为成员函数。 (3) 对于复合的赋值运算符如+=、-=、*=、/=、&=、!=、~=、%=、>>=、<<=建议重载为成员函数。
(4) 对于其它运算符,建议重载为友元函数。
运算符重载的方法是定义一个重载运算符的函数,在需要执行被重载的运算符时,系统就自动调用该函数,以实现相应的运算。也就是说,运算符重载是通过定义函数实现的。运算符重载实质上是函数的重载。重载运算符的函数一般格式如下:
函数类型 operator 运算符名称 (形参表列)
{
对运算符的重载处理
}
重载为类成员函数时参数个数=原操作数个数-1(后置++、--除外)
重载为友元函数时 参数个数=原操作数个数,且至少应该有一个自定义类型的形参
阅读全文
0 0
- 查询练习(三)
- MapReduce练习(三)
- Scala练习(三)
- 听课练习(三)
- JavaScript练习(三)
- C练习(三)
- RecyclerView 练习(三)
- acm练习(三)
- python练习(三)
- 练习(三)
- python练习(三)
- javscript练习(三)
- 练习(三)
- 笔试题练习(三)
- awk 实例练习 (三)
- Jquery选择器练习(三)
- 菜鸟练习PAT(三)
- 练习代码(三)复用类
- 在HTML中使用JavaScript(总结自JavaScript高级程序设计)
- 离散事件模拟-银行管理
- hdu 6053 TrickGCD [2017 Multi-University Training Contest
- Ubuntu 14.04的基本配置
- HDU 6053 TrickGCD DP(筛法)
- 练习(三)
- session共享机制
- 程序员眼中世界上最远的距离
- Android 性能优化<九> RecyclerView替代Listview用法
- js基础 事件基础一
- C++实现顺序表基本函数以及增删查改
- C# DataSet和DataTable详解(一)
- 购物车
- 权限,网络请求,判断,XlistVIew的依赖


