Bagging 与Boosting 特点分析
来源:互联网 发布:网络推广活动方案 编辑:程序博客网 时间:2024/06/06 11:00
- bagging的偏差和方差
对于bagging来说,每个基模型的权重等于1/m且期望近似相等(子训练集都是从原训练集中进行子抽样),故我们可以进一步化简得到:
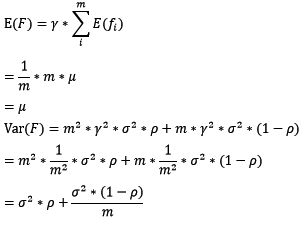
根据上式我们可以看到,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
Random Forest是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。Random Fores中基模型是树模型,在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,第一项显著减少,第二项稍微增加,整体方差仍是减少。
- boosting的偏差和方差对于boosting来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对boosting化简公式为:
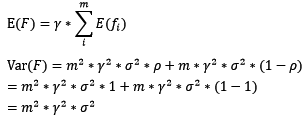
通过观察整体方差的表达式,我们容易发现,若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,boosting框架中的基模型必须为弱模型。
因为基模型为弱模型,导致了每个基模型的准确度都不是很高(因为其在训练集上的准确度不高)。随着基模型数的增多,整体模型的期望值增加,更接近真实值,因此,整体模型的准确度提高。但是准确度一定会无限逼近于1吗?仍然并不一定,因为训练过程中准确度的提高的主要功臣是整体模型在训练集上的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于boosting框架的Gradient Tree Boosting模型中基模型也为树模型,同Random Forrest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
参考:http://www.cnblogs.com/jasonfreak/p/5657196.html- Bagging 与Boosting 特点分析
- mallet源码分析之bagging与boosting
- bootstrps、bagging 与boosting
- bootstrps 、bagging与 boosting
- bootstrps 、bagging与 boosting
- bootstrps 、bagging与 boosting
- bootstrps 、bagging与 boosting
- Boosting与Bagging
- boosting与bagging理解
- Bagging 与Boosting
- bagging 与 boosting的区别
- 区分Bootstrps、Bagging与 Boosting
- boosting-bagging
- Bagging,Boosting
- 机器学习(五):Bagging与Boosting
- 集成学习之Bagging与Boosting
- bootstrap, boosting, bagging 几种方法的区别与联系
- Boosting和Bagging
- 出栈序列的统计
- 拥塞控制算法测试——Planetlab平台实验
- 8.2常用类(Object类,Scanner类)
- Java源码阅读-ArrayList
- go学习(五)——基本数据类型转换
- Bagging 与Boosting 特点分析
- HDU1282 最简单的计算机
- 利用可变参数实现求平均值
- HDU-1284-钱币兑换问题(完全背包)
- 单例模式的懒汉模式和饿汉模式
- 哲学家就餐问题
- 如何设置无需fn直接按F1~F10(HP Pavilion Notebook )
- 杭电acm—1013 Digital Roots
- 机器学习算法(3:决策树算法)


