从InnoDB了解MVCC
来源:互联网 发布:fc2live直播域名 编辑:程序博客网 时间:2024/06/03 22:55
一、MVCC简介
MVCC (Multiversion Concurrency Control),即多版本并发控制技术,它使得大部分支持行锁的事务引擎,不再单纯的使用行锁来进行数据库的并发控制,取而代之的是把数据库的行锁与行的多个版本结合起来,只需要很小的开销,就可以实现非锁定读,从而大大提高数据库系统的并发性能
读锁:也叫共享锁、S锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S 锁。这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
写锁:又称排他锁、X锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
表锁:操作对象是数据表。Mysql大多数锁策略都支持(常见mysql innodb),是系统开销最低但并发性最低的一个锁策略。事务t对整个表加读锁,则其他事务可读不可写,若加写锁,则其他事务增删改都不行。
行级锁:操作对象是数据表中的一行。是MVCC技术用的比较多的,但在MYISAM用不了,行级锁用mysql的储存引擎实现而不是mysql服务器。但行级锁对系统开销较大,处理高并发较好。
二、MVCC实现原理
innodb MVCC主要是为Repeatable-Read事务隔离级别做的。在此隔离级别下,A、B客户端所示的数据相互隔离,互相更新不可见
了解innodb的行结构、Read-View的结构对于理解innodb mvcc的实现由重要意义
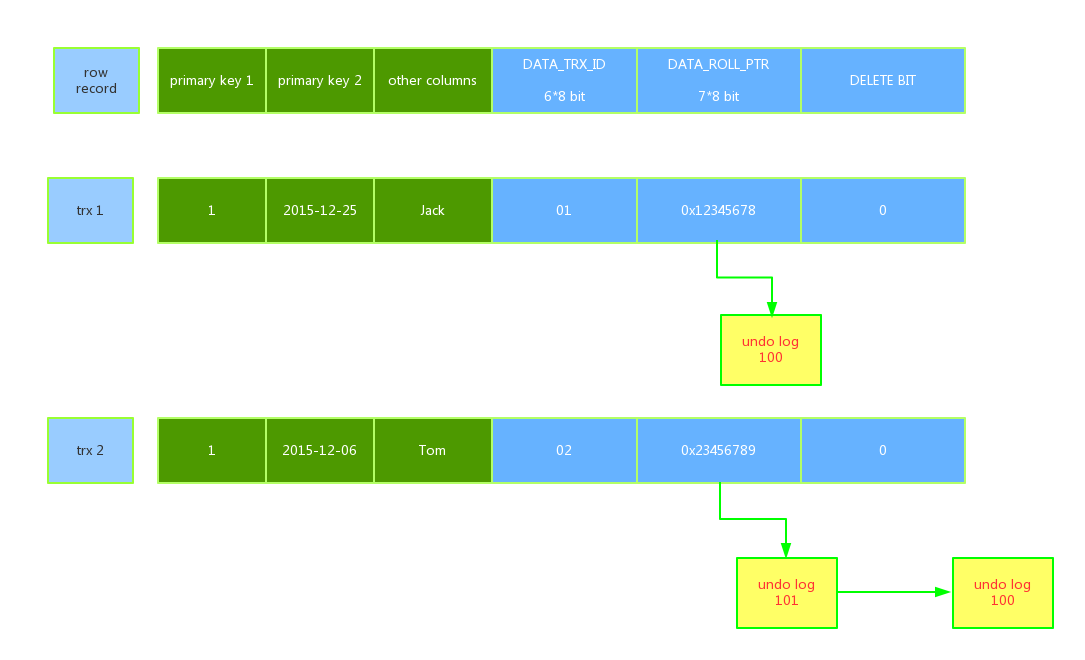
innodb存储的最基本row中包含一些额外的存储信息 DATA_TRX_ID,DATA_ROLL_PTR,DB_ROW_ID,DELETE BIT
6字节的DATA_TRX_ID 标记了最新更新这条行记录的transaction id,每处理一个事务,其值自动+1
7字节的DATA_ROLL_PTR 指向当前记录项的rollback segment的undo log记录,找之前版本的数据就是通过这个指针
- 6字节的DB_ROW_ID,当由innodb自动产生聚集索引时,聚集索引包括这个DB_ROW_ID的值,否则聚集索引中不包括这个值.,这个用于索引当中
DELETE BIT位用于标识该记录是否被删除,这里的不是真正的删除数据,而是标志出来的删除。真正意义的删除是在commit的时候
具体的执行过程
begin->用排他锁锁定该行->记录redo log->记录undo log->修改当前行的值,写事务编号,回滚指针指向undo log中的修改前的行
上述过程确切地说是描述了UPDATE的事务过程,其实undo log分insert和update undo log,因为insert时,原始的数据并不存在,所以回滚时把insert undo log丢弃即可,而update undo log则必须遵守上述过程
下面分别以select、delete、 insert、 update语句来说明
SELECT
Innodb检查每行数据,确保他们符合两个标准:
1、InnoDB只查找版本早于当前事务版本的数据行(也就是数据行的版本必须小于等于事务的版本),这确保当前事务读取的行都是事务之前已经存在的,或者是由当前事务创建或修改的行
2、行的删除操作的版本一定是未定义的或者大于当前事务的版本号,确定了当前事务开始之前,行没有被删除
符合了以上两点则返回查询结果。
INSERT
InnoDB为每个新增行记录当前系统版本号作为创建ID。
DELETE
InnoDB为每个删除行的记录当前系统版本号作为行的删除ID。
UPDATE
InnoDB复制了一行。这个新行的版本号使用了系统版本号。它也把系统版本号作为了删除行的版本。
说明
insert操作时 “创建时间”=DB_ROW_ID,这时,“删除时间 ”是未定义的;
update时,复制新增行的“创建时间”=DB_ROW_ID,删除时间未定义,旧数据行“创建时间”不变,删除时间=该事务的DB_ROW_ID;
delete操作,相应数据行的“创建时间”不变,删除时间=该事务的DB_ROW_ID;
select操作对两者都不修改,只读相应的数据
三、对于MVCC的总结
- 每行数据都存在一个版本,每次数据更新时都更新该版本
- 修改时Copy出当前版本随意修改,各个事务之间无干扰
- 保存时比较版本号,如果成功(commit),则覆盖原记录;失败则放弃copy(rollback)
- 事务以排他锁的形式修改原始数据
- 把修改前的数据存放于undo log,通过回滚指针与主数据关联
- 修改成功(commit)啥都不做,失败则恢复undo log中的数据(rollback)
四. MVCC全称是Multi-Version Concurrency Control,即多版本并发控制。
这是种很常用的技术,现在几乎所有的关系数据库都支持它。平时它默默工作,像个透明人,似乎不用关心它的细节。但是当我们偶尔在数据库里面遇到一些奇怪问题时,却不得不需要关注它。因为很可能这些“奇怪”的问题,不过是MVCC里的正常行为;而且,MVCC的设计思路还能在我们日常的开发中起到一些借鉴作用。所以,对于大部分开发者而言,了解MVCC还是挺有意义的。
说起来,MVCC是怎么产生的呢?其实看名字就能猜到啦,和并发有关。
这东西的原理挺简单,我们自己也能设计哦:
首先我们回顾一下,以前教科书里的数据库系统,它的并发是怎么实现的呢?
如图,当一个事务要读loan_id=1001的这行行数据时,会对其加读锁(S);而另一个事务要修改这行数据时,会要求对其加写锁(X)。
这样一来,并发读是可以的,但是读和写互相阻塞,性能较低。
然后,有人想到了多版本的方式来提高性能,灵感就是CopyOnWrite:
如图,修改数据时,写事务会插入并锁定一条新的数据(sn=2),并不会影响旧数据(sn=1)。
所以,读事务不需要加锁,当写事务没有提交时,可以继续读版本1的数据;而写事务提交并释放锁以后,读事务就可以读版本2的数据了。
这里读和写的事务不再相互阻塞,而且写不需要加锁,并发性能得到了提高。
接下来再处理下一致性的问题,于是表可以变成这样:

从上图可以看出,对读事务而言,只需要读每一条loan_id的最大有效数据,也就是sn<=2的数据;而写事务,会创建一个新版本3,并在提交修改时,将新版本的status从pending修改为success使其生效。
而在读事务的执行过程中,如果写事务完成了版本3的提交,读事务能否读到版本3的数据呢?答案当然是不能。读事务应该在最开始获得有效的最大sn,也就是版本2。之后即使写事务提交了版本3,读事务仍会以版本2作为最大有效版本。这样可以保证读数据的一致性。也就是说,即使读到的是较老版本的数据,也比读到一半老版本一半新版本的数据好。因为失去一致性的数据其实是错误的。
到此为止,一个简单的MVCC就倒腾出来了。是不是很简单呢?这个设计简单但实用,其实在许多数据仓库里还这么用着呢。
不过这个设计确实太简单,还有一些重要问题需要解决:
1. 无效的老版本数据怎么处理?对数据仓库,可以一直保留;但对普通应用,通常不合适。
2. 并发修改怎么处理?对数据仓库,修改的事务只需要一个,就是ETL job;但对普通应用,显然不够啊。
好啦,接下来,我们还是去看看别人家孩子吧。毕竟别人家孩子早就会打酱油了,咱们还是别光自己折腾啦。
首先,我们来看一下Mysql InnoDB的MVCC实现。
关于InnoDB,在《高性能MySql》里面有段简化描述:
它通过两个隐藏列实现。两个列一个保存了行的创建时间,另一个保存了过期时间(实际保存的是系统版本号,不过可以等价看做时间)。
每开始一个新的事务,这个版本号就会增加,并且将当前版本号作为事务版本号。
在InnoDB默认repeatable-read隔离级别下,它的工作方式是:
查询数据:它会检索创建时间在事务版本号之前的数据,也就是select * from table where create_version<=${version},所以新事务创建的数据是不可见的;同时会检查数据的删除时间,保证新的删除操作不可见。最终相当于select * from table where create_version<=${version} and (delete_version is null or delete_version>${version})
删除数据:把当前数据的删除时间设置为当前事务版本号。
插入数据:创建一条新的数据,创建时间就是当前事务版本号。
更新数据:删除和插入的综合,删除原数据并且插入一条新数据。
这是一个简单有效的MVCC模型……不过等一下,这看起来和我们的设计不是差不多吗?我书读得少不要骗我,这好像也没有解决之前我们提出的问题啊?
但其实呢,这段描述只是为了方便读者理解,InnoDB实际的实现……不是这样的。这个,书读得多也会被骗的……
所以呢,接下来我们只好稍微深入下细节了,看看InnoDB其实是怎么实现并解决我们提出的问题的。
首先,它的隐藏列实际不是创建时间和删除时间,而是当前事务id列和删除标志位。
这两个列更像我们之前自己的设计了吧?它们也能提供在简化模型里提到的那些功能。而且事务id还有更多的作用,这个后面会提到。
现在再看看我们先前提出的第一个问题,失效的数据怎么办?是不是可以定期去各表里扫描回收呢?
是的,这是个很好的办法,它确实要扫描回收。不过呢,它稍微聪明一些。它并不到各个表里扫描,而是去undo log里扫描。而在这之前,它已经将老版本的数据移动到了undo log。
这里可能需要为了解数据库较少的同学补充一点数据库undo log和redo log的知识:
undo log:用于事务回滚,里面放着修改前的数据,需要回滚事务时可以根据它把修改前的数据替换回去;
redo log:重做日志,用于恢复,可以认为它是数据的保护者。数据修改时,通常不会马上写入磁盘,而会记录到redo log并只修改内存里缓存的数据。当修改操作被写入redo log后,就可以认为修改不会丢失了。而对数据的磁盘持久化,可以放到后面更合适的时候。这主要是性能考虑:磁盘数据的修改,容易导致随机写入,远比redo log的顺序写入慢。这里需要提醒下:undo log同样需要redo log的保护,对undo的修改同样会记录redo log。在需要恢复系统的时候,会根据redo log恢复到当前状态(此时undo log的恢复同样依赖redo log),再根据undo log回滚没有提交的事务。
好,回到我们关于回收失效数据的话题吧。
所以呢,其实旧版本的数据,是保存在undo log里面的。当一条数据被修改的时候,旧版本的数据会被移动到undo log,而新的修改会在原位置进行。而每条数据还有一个隐藏列,称为回滚指针,会指向被移动到undo log里的这条旧数据。当我们需要读取这条旧数据的时候,就需要先找到现在最新版的数据,然后根据这条数据的回滚指针,去查找undo log里的旧数据。如果这条旧数据的版本还是太新,不是我们想要的怎么办呢?它也有指向更旧数据的回滚指针,而更旧的数据也在之前就被移动到了undo log里,我们继续回溯就好了。
而失效数据的回收,是通过Purge后台进程实现的。Purge进程定期扫描undo log,按照从旧到新的顺序,检查每条记录是否应被清理回收。在扫描前,它会先取得当前活动事务列表,借此判断扫描到的记录是不是失效数据,并清理回收。
这里再提出一个小问题,我们什么情况下会需要读取undo log里面的旧数据呢?
其实常见读取数据有两种方式:
一致读:也叫快照读。当我们根据where条件查找数据时,或者单纯的select数据时,在MVCC里采用的是一致读。此时是根据我们事务启动时的时间点,读取该时间点的一个数据快照(snapshot)。如果新修改发生在我们的读事务启动之后,或者新修改所属的事务还没有提交,这些新修改对我们都应该是不可见的。所以我们不能读最新的数据,而需要根据回滚指针读取旧数据。
当前读:在真正需要修改数据时,肯定不能按照快照获取的数据进行修改,否则会丢失修改。这时就需要读取该数据现在的最新值,并且在最新值基础上进行修改,这就是当前读。如果此时最新值所属的事务还没有提交,就必须等待其回滚或提交。
我们之所以需要读取undo log里面的旧数据,就是因为很多时候我们都在使用一致读。一致读不需要对数据加锁,有很好的性能。
接下来我们再看看先前提出的第二个问题,在MVCC下的并发修改怎么实现呢?
还是靠加锁。
1. 对该数据加写锁(X)
2. 记录redo log
3. 复制修改前的旧值到undo log
4. 在原来数据的位置修改数据,并修改回滚指针指向undo log中的旧值。
如果是修改主键的话,因为InnoDB在主键上有聚簇索引 ,修改步骤会有点差别。但修改主键本身不是好的设计,所以我们不讨论。
这里又有个小问题,一致性读时InnoDB的事务隔离是怎么实现的呢?
对没有提交的事务,虽然它的事务id比我们的事务id更小,它的修改仍然应该对我们不可见。
这时,就需要前面提到的,每条数据上的隐藏列——事务id列的帮助了。
当我们的事务开启时,会取得当前活动事务列表。根据这份列表,就可以排除没有提交的修改数据。这时,通过比对数据上记录的事务id和活动事务列表,就能判断该数据是否可见:
1. 如果是当前事务自己的修改,可见;
2. 如果大于当前事务id,不可见(repeatable-read);
3. 如果小于最小活动事务id,可见;
4. 其他情况,需要和活动事务列表做详细比对。
好啦,我们现在总算解决了我们前面提到的几个问题,新的方案可以投入使用了(撒花)。看起来别人家孩子果然是比较强啊。其实除InnoDB外的其他数据库,对MVCC的实现也有自己的一些特点,但我们这里就不研究其差异了,大家有兴趣的话可以自己去看看。
原文:http://www.sohu.com/a/158299643_575744
- 从InnoDB了解MVCC
- InnoDB MVCC
- mvcc innodb
- MySQL InnoDB MVCC原理
- InnoDB MVCC浅谈
- MySQL InnoDB MVCC原理
- innodb mvcc理解
- MySQL InnoDB MVCC深入浅出
- innodb的MVCC功能
- InnoDB MVCC浅谈
- mysql innodb mvcc理解
- mysql Innodb和mvcc
- InnoDB MVCC 要点摘录
- InnoDB的MVCC
- innodb mvcc实现机制
- MVCC实现-MYSQL INNODB MVCC实现
- InnoDB中MVCC的实现
- InnoDB MVCC实现、Undo作用
- 关于接水问题心得
- jQuery基础(2)
- 自然语言处理(简称NLP)
- 如何清空<div>标签中的内容 而不清除<div>标签
- GHGL项目总结-DB2
- 从InnoDB了解MVCC
- 『数论』乘法逆元
- osg 相机操作
- 自然语言处理怎么最快入门?
- Objective
- 关于synchronized关键字小谈
- 编写自己的代码库(javascript常用实例的实现与封装)
- Node.Js学习之连接SQLServer数据库
- Android 网络编程(三)HttpURLConnection


