八大排序算法总结
来源:互联网 发布:淘宝骗手机 编辑:程序博客网 时间:2024/06/16 21:47
经典的排序算法
这些天复习了排序这个模块,排序算法在程序员的日常工作中是必不可少的,有时候我们不知不觉就用到了排序,这是因为高级语言系统已经比较完美的封装和优化了排序算法,并且在笔试,面试等方面我们都能见到它的身影。下面结合那本大三的教材:严版的《数据结构》,来说一说这几个经典的排序算法,如果有不对的欢迎指正!
首先我们还是先说基础概念(按书上说的),万变离不开概念,没有概念没有规矩,那可不行。
一、冒泡排序
二、直接选择排序
三、直接插入排序
四、希尔排序
五、堆排序
六、归并排序
七、快速排序
八、各种算法效率比拼
1:内部排序和外部排序(我们重点说内部排序(因为我们最常用到))
2:排序的方法
3:稳定性
4:图表帮助大家记忆:
O(n2)
O(n) O(n2) 稳定
希尔排序
O(n1.3) O(n) O(n2) 不稳定
选择排序
直接选择
O(n2) O(n2) O(n2) 不稳定
堆排序
O(nlog2n) O(nlog2n) O(nlog2n) 不稳定
交换排序
冒泡排序
O(n2) O(n) O(n2) 稳定
快速排序
O(nlog2n) O(nlog2n) O(n2) 不稳定
归并排序
O(nlog2n) O(nlog2n) O(nlog2n) 稳定
基数排序
O(d(r+n))
O(d(n+rd)) O(d(r+n)) 稳定
一、冒泡排序

1 //冒泡排序 2 void bubbling(int arr[], int n){ 3 int i, j, temp; 4 for (j = 0; j < n - 1; j++){ 5 for (i = 0; i < n - 1 - j; i++){ 6 if(arr[i] > arr[i + 1]){ 7 temp = arr[i]; 8 arr[i] = arr[i + 1]; 9 arr[i + 1] = temp;10 }11 }12 } 13 }
二、直接选择排序
是一种选择排序,总的来说交换的少,比较的多,如果排序的数据是字符串的话比建议使用这种方法。
1:简要过程:
首先找出最大元素,与最后一个元素交换(arr[n-1]),然后再剩下的元素中找最大元素,与倒数第二个元素交换....直到排序完成。
2:排序效率:
一趟排序通过n-1次的关键字比较,从n-i-1个记录中选择最大或者最小的元素并和第i个元素交换,所以平均为n(n-1)/2,时间复杂度为O(n2),也不是个省油的灯,效率还是比较低。
3:排序过程图:(选择小元素,图片来源百度搜索)
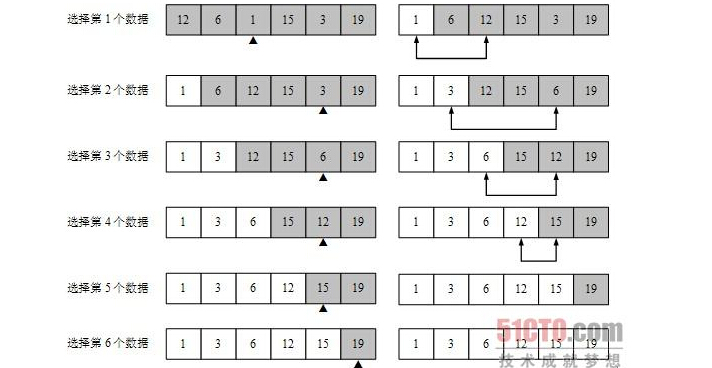
4:具体算法实现:
1 //直接选择排序 2 void directDialing(int arr[], int n){ 3 int i,j,k,num; 4 for(i = 0; i < n; i++){ 5 num = 0; 6 for(j = 0; j < n-i; j++){ 7 if(arr[j] > arr[num]){ 8 num = j; 9 } 10 }11 k = arr[n-i-1];12 arr[n-i-1] = arr[num];13 arr[num] = k;14 }15 }
三、直接插入排序
是一种简单的排序方法,算法简洁,容易实现
1:简要过程:
每步将一个待排序元素,插入到前面已经排序好的元素中,从而得到一个新的有序序列,直到最后一个元素加入进去即可。
2:排序效率:
空间上直接插入排序只需要一个辅助空间,时间上:花在比较两个关键字的大小和移动记录,逆序时比较次数最大:(n+2)(n-1)/2,平均:n2/4,所以直接插入排序时间复杂度也是O(n2)
3:排序过程图:

4:具体算法实现:
1 //直接插入排序 2 void insert(int arr[], int n){ 3 int m,i,k; 4 for(i = 1; i < n; i++){ 5 m = arr[i]; 6 for(k = i-1; k >= 0; k--){ 7 if(arr[k] > m){ 8 arr[k+1] = arr[k]; 9 }else{10 break;11 }12 }13 arr[k+1] = m;14 }15 }1:简要过程:
选择一个增量序列a1,a2,…,ak,其中ai>aj,ak=1;按增量序列个数k,对序列进行k 趟排序;每趟排序,根据对应的增量ai,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。2:排序效率:
3:排序过程图:

1 //希尔排序 2 void Heer(int arr[], int n){ 3 int i,j,k,num; 4 k = n/2; 5 while(k > 0){ 6 for(i = k; i < n; i++){ 7 num = arr[i]; 8 for(j = i - k;j >= 0; j -= k){ 9 if(arr[j] > num){10 arr[j+k] = arr[j];11 }else{12 break;13 }14 }15 arr[j+k] = num; 16 }17 k = k/2;18 }19 }
五、堆排序
先说说堆的定义:n个元素的序列{k1,k2,. . . kn}当且仅当满足以下条件时称之为堆:
ki <= k2i ki >= k2i
ki <= k2i+1 ki >= k2i+1
若将这样的序列对用的一维数组看成一个完全二叉树则堆的定义看出:完全二叉树非终节点的值均不大于(不小于)其左右两个孩子的节点值。
大顶堆和小顶堆:堆顶元素取最小值的是小顶堆,取最大值的是大顶堆。
1:简要过程:
(1) 建堆:对初始序列建堆的过程,就是一个反复进行筛选的过程。n 个结点的完全二叉树,则最后一个结点是第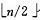 (既是程序中的n * 2 +1)个结点的子树。筛选从第个结点为根的子树开始,该子树成为堆。之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
(既是程序中的n * 2 +1)个结点的子树。筛选从第个结点为根的子树开始,该子树成为堆。之后向前依次对各结点为根的子树进行筛选,使之成为堆,直到根结点。
(2) 调整堆:k个元素的堆,输出堆顶元素后,剩下k-1 个元素。将堆底元素送入堆顶(最后一个元素与堆顶进行交换),堆被破坏,其原因仅是根结点不满足堆的性质。将根结点与左、右子树中较小元素的进行交换。若与左子树交换:如果左子树堆被破坏,即左子树的根结点不满足堆的性质,则重复调整堆,.若与右子树交换,如果右子树堆被破坏,即右子树的根结点不满足堆的性质。则重复调整堆。对不满足堆性质的子树进行上述交换操作,直到叶子结点,堆被建成。
2:排序效率:
堆排序的方法对记录较少的文件并不值得提倡,但对于数据较大的文件还是很有效的,时间主要花在初始建堆和交换元素后调整堆上。对深度为k的堆比较算法最多为2(k-1)次,含有n个元素深度为h的堆时总共进行的关键字比较不超过4n,由此可见最坏的情况下,时间复杂度为O(nlogn)并且仅需要一个辅助控间,速度已经是相当快了。
3:排序过程图(图片来源百度,帮助理解):

4:具体算法实现:
1 //堆调整 2 void adjust(int arr[], int n, int length){ 3 int max,b; 4 while(n * 2 +1 <= length){//说明存在左节点 5 max = n * 2 + 1; 6 if(n * 2 + 2 <= length){//说明存在右节点 7 if(arr[max] < arr[n * 2 + 2]){ 8 max = n * 2 + 2; //跟新最小的值 9 } 10 } 11 if(arr[n] > arr[max]){12 break;//顺序正确,不需要再调整 13 }else{14 b = arr[n];15 arr[n] = arr[max];16 arr[max] = b;17 n = max;18 }19 }20 } 21 22 //堆排序 23 void stack(int arr[], int length){24 int i,k,m = 0;25 for(i = length/2-1; i >=0; i--){26 adjust(arr,i,length-1);27 } 28 //调整堆29 for(i = length-1 ;i >= 0; i--){ 30 //调整后把最后一个和第一个交换,每次调整少一个元素,依次向前 31 k = arr[i];32 arr[i] = arr[0];33 arr[0] = k;34 adjust(arr,0,i-1);35 }36 }
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- 八大排序算法总结
- Word Break
- 简单计算机的js
- 交叉验证
- CC3200 TI RTOS LPDS模式
- 第一篇文章
- 八大排序算法总结
- WEB窗口
- Spring MVC 项目中配置log4j 出现错误log4j:ERROR Failed to excute sql
- The number on the board
- AngularJS入门-(12)http
- 阮一峰大神的前端全栈教程
- Hdu6063 RXD and math(2017多校第3场)
- 解决Android拍照6.0以上动态获取权限问题
- Webproject 每次运行都停到 workerDone(this);


