Hadoop之HDFS存储及读取机制
来源:互联网 发布:入党申请书 知乎 编辑:程序博客网 时间:2024/05/19 00:43
什么是HDFS?
首先HDFS称为分布式文件系统,是一个高容错性的系统。
分布式文件系统,首先其中有几点。分别是:
- 分布式。
- 文件。
- 系统
即横跨在多台计算机上的同一个文件存储系统。存储在分布式文件系统上的数据自动分布在不同的节点上。
由于是分布式文件系统,所以元数据与数据文件是分离存储的
- NameNode
- DataNode
在传统的文件系统里,因为文件系统不会跨越多台机器,元数据和数据存储在同一台机器上。
为了构建一个分布式文件系统,让客户端在这种系统中使用简单,并且不需要知道其他客户端的活动,那么元数据需要在客户端以外维护。HDFS的设计理念是拿出一台或多台机器来保存元数据,并让剩下的机器来保存文件的内容。
存储在HDFS上的每份数据片有多份副本(replica)保存在不同的服务器上。在本质上,NameNode是HDFS的Master(主服务器),DataNode是Slave(从服务器)。
NameNode和DataNode是HDFS的两个主要组件。其中,元数据存储在NameNode上,而数据存储在DataNode的集群上。 NameNode不仅要管理存储在HDFS上内容的元数据,而且要记录一些事情,比如哪些节点是集群的一部分,某个文件有几份副本等。它还要决定当集群的节点宕机或者数据副本丢失的时候系统需要做什么。
HDFS写入过程
NameNode负责管理存储在HDFS上所有文件的元数据,它会确认客户端的请求,并记录下文件的名字和存储这个文件的DataNode集合。它把该信息存储在内存中的文件分配表里。
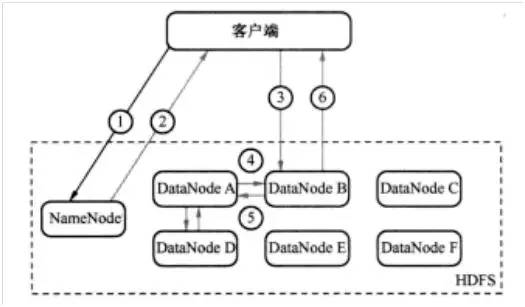
例如,客户端发送一个请求给NameNode,说它要将“demo.txt”文件写入到HDFS。那么,其执行流程如图1所示。具体为:
第一步:客户端发消息给NameNode,说要将“demo.txt”文件写入。(如图1中的①)
第二步:NameNode发消息给客户端,叫客户端写到DataNode A、B和D,并直接联系DataNode B。(如图1中的②)
第三步:客户端发消息给DataNode B,叫它保存一份“demo.txt”文件,并且发送一份副本给DataNode A和DataNode D。(如图1中的③)
第四步:DataNode B发消息给DataNode A,叫它保存一份“demo.txt”文件,并且发送一份副本给DataNode D。(如图1中的④)
第五步:DataNode A发消息给DataNode D,叫它保存一份“demo.txt”文件。(如图1中的⑤)
第六步:DataNode D发确认消息给DataNode A。(如图1中的⑤)
第七步:DataNode A发确认消息给DataNode B。(如图1中的④)
第八步:DataNode B发确认消息给客户端,表示写入完成。(如图1中的⑥)
Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); Path file = new Path("demo.txt"); FSDataOutputStream outStream = fs.create(file); outStream.writeUTF("Welcome to HDFS Java API!!!"); outStream.close(); HDFS写入过程
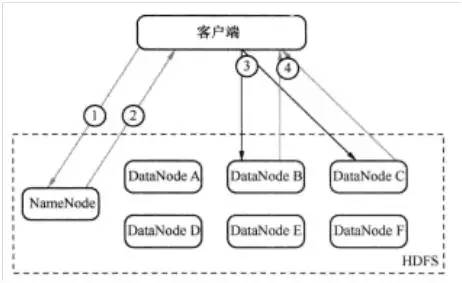
为了理解读的过程,可以认为一个文件是由存储在DataNode上的数据块组成的。客户端查看之前写入的内容的执行流程如图2所示,具体步骤为:
第一步:客户端询问NameNode它应该从哪里读取文件。(如图2中的①)
第二步:NameNode发送数据块的信息给客户端。(数据块信息包含了保存着文件副本的DataNode的IP地址,以及DataNode在本地硬盘查找数据块所需要的数据块ID。) (如图2中的②)
第三步:客户端检查数据块信息,联系相关的DataNode,请求数据块。(如图2中的③)
第四步:DataNode返回文件内容给客户端,然后关闭连接,完成读操作。(如图2中的④)
客户端并行从不同的DataNode中获取一个文件的数据块,然后联结这些数据块,拼成完整的文件。
- Hadoop之HDFS存储及读取机制
- Hadoop中HDFS的存储机制
- Hadoop的HDFS文件存储实现机制
- Hadoop中HDFS的存储机制
- Hadoop中HDFS的存储机制
- Hadoop中的HDFS的存储机制
- Hadoop学习笔记之HDFS读取
- Hadoop学习之HDFS文件读取
- Hadoop之HDFS文件读取流程
- Hadoop之客户端读取HDFS中的数据
- Hadoop的HDFS机制
- hadoop HDFS存储原理
- 【Hadoop】数据存储----HDFS
- hadoop HDFS存储原理
- hadoop HDFS存储原理
- hadoop hdfs存储原理
- hadoop HDFS存储原理
- Hdfs存储机制
- iosprotocolbuffer
- 文件查找
- AC自动机模板
- 对v7包下的AlertDialog(弹出框)在实际开发中遇到的小问题进行阐述
- Pytorch实现CNN卷积神经网络
- Hadoop之HDFS存储及读取机制
- 并发与计算机体系结构
- Spring集成Quartz定时任务&&Cron表达式详解
- java中互锁代码测试
- 写简历方法
- Android进阶之路
- Tracking Area Update (TAU) procedure
- 01背包问题
- Myeclipse、eclipse安装lombok


