总结:Distributed systems for fun and profit
来源:互联网 发布:启动sql server服务 编辑:程序博客网 时间:2024/05/17 01:20
在分布式系统的学习过程中,无论是读论文还是做项目,总能看到好多名词:Consistency, failure detector, order, timer;好多问题:Consensus, broadcast; 好多结论:FLP, CAP。了解单一名词的意义比较容易,但这些名词背后和分布式系统的联系,和商业分布式系统是如何利用这些理论的,一直不是很直观。啃了好多论文,却是只见树木,不见森林。偶然间翻阅到一个大神写的博客,刚好串起了这个领域里的一些知识点。
需要说明的是,因为大神写的也不是正式的论文,里面难免有不严谨的地方。而我这篇博客也只是总结性质,又加上了自己的理解,难免有不严谨甚至错误的地方,发现之后再补充完善。附上原文链接,感兴趣的同学可以之间看原文教程:
http://book.mixu.net/distsys/
1. Distributed systems 介绍
一般来说,我们利用分布式系统是为了:
Storage:扩展存储能力
Computation:扩展计算能力
当一个网站的数据量很小的时候,没有必要使用分布式系统,单点系统更加简单可靠。但当数据量增大到一定数目时,单点系统可能会不足,而更换更好的单点系统又过于昂贵。这时候,我们可以采用分布式系统。之所以要使用分布式系统,根源在于数据量和业务量的扩张。
1.1 分布式系统想要达成的目标
Scalability:
“Is the ability of a system,network, or process, to handle a growing amount of work in a capable manner or its ability to be enlarged to accommodate that growth。”
一个系统处理 “增长” 的能力(即增长之后性能不会受太大影响)。“增长”可以划分为三个维度:
Size scalability:增加nodes,可以使系统线性增长,增加dataset不会增加latency
Geographic scalability:
Administrative scalability:增加nodes不应该增加administrative costs
Performance(and latency):
Is characterized by the amount of useful work accomplished by a computer system compared to the time and resources used.
Performance就是看反应时间和消耗的资源。具体来说:
Low latency: 延迟
High throughout:吞吐量
Low utilization of computing resource: 资源利用率
Availability:
The proportion of time a system is in a functioning condition. If a user cannot access the system, it is said to be unavailable.
一个系统可用的时间所占的比例。
从技术角度来说,availability 与 fault tolerant 相关。一个系统容错能力强,它的availability也就可能越高。
Fault tolerance:
Ability of a system to behave in a well-defined manner once faults occur.
一个系统在出现错误时依然可以”behave in a well-defined manner”.
这里所说的容错,是容纳你能考虑到的错误。定义所有你能想到的faults,之后用系统或算法来“容忍”它们。注意,你不能“容忍”没有定义的faults。
1.2 分布式系统中的模型
Abstractions and Models:
System model (asynchronous / synchronous)
Failure model: (crash-fail, partitions, Byzantine)
Consistency model:(strong, weak, eventual)
理想状态下,我们想让分布式系统“表现得好像一个单系统”。但事与愿违,不同种类的failures让这个目标实现起来很困难。比如当出现partition(分区)的时候,你是要为了availability接受用户请求呢,还是为了safety拒绝用户。关于权衡分布式系统各个方面的表现,最著名的就是CAP理论。
1.3 分布式系统常用技术
Design techniques: partition and replicate
在节点之间如何分发数据是很重要的,它决定了如何定位数据以及我们如何处理它们。分布式系统中关于数据有两种technique:
Partition:把数据且分开,便于并行处理
Replication:把数据拷贝多份便于fault tolerance
在设计分布式系统时,要想着这两种方式。这是解决分布式问题的两大法宝,针对对两个技术,有若干算法。
Partition的好处是:
Performance:限制数据块大小,提高处理效率
Availability: 一个数据分块,提高availability(一部分的损坏不会影响其余部分)
Replication允许我们达到availability, performance,fault-telerance。
Afraid of loss of availability? 备份!
Slow computation? 在多个系统中进行计算
Slow I/O? 在本地缓存中备份数据。
但replication的引入也引起了consistency的问题。所以定义了不同级别的consistency model:
Strong model可以让程序员感觉不到replication的存在。
weak model会让程序员看到一些内部状态,但是又提供了更短的latency和更高的 availability
2. Up and down the level of abstraction
为了更好地描述分布式系统,需要定义一系列的抽象来描述系统的特征
System model
Nodes in the system model
Communication link between nodes
Timing / Ordering assumptions
在这些假设和抽象的基础之上,我们又介绍了几个很重要的问题和结论
The consensus problem
FLP and CAP
Consistency model
A system model
A set of assumptions about the environment and facilities on which a distributed system is implemented.
System model 是为了抽象地描述一个分布式系统的特征。它一组assumptions,包括了各种特性:同步异步?通
一个System model也有强弱信延迟情况?之分,而一个健壮的system model是用了尽量弱的假设来构建的,这样的话,针对这个模型所做的算法也更能适应其他模型。
Nodes in our system model
Nodes 是用来执行程序,储存数据,提供时钟的。它可以执行一系列的指令。
Nodes 可以有不同的Failure:
Crash-recovery. Node只可能停止工作。在停止工作后有方法可以恢复
Byzantine fault tolerance. 真实的系统中,很少应用byzantine fualt tolerance,引文它太过复杂和昂贵。
Communication links in our system model
这个特征是用来描述信道的,例如信道是否可靠?
最多常用的设定是,一个系统中的不同节点之间有不同的信道,每个信道是FIFO的,每条接受到的消息必须是发送过的,消息不能丢失。
当节点还能工作,网络又断了的时候,network partition就出现了。
Timing / ordering assumptions
Synchronous:一条消息有确认的延迟上限。
Asynchronous: 一条消息没有确定的延迟上限。
The consensus problem:
Consensus 问题就是所有的节点对某个值打成了共识。
Some computers (or nodes) achieve consensus if they all agree on some value. More formally:
Agreement: 所有正常的节点都同意
Integrity:所有的正常节点只能对最多一个值打成一致
Termination:最终总会达成一致
Validity:如果所有节点都提出V, 那么系统要决定是V
Consensus 问题是很多商业分布式系统的核心。 而consensus问题跟atomic broadcast和atomic commit都是相关联的。
Two impossibility results:
两个著名的“不可能推论”:FLP 和 CAP
FLP:
Assumption:
Asynchronous: 异步
Failure crash:只考虑crash
Message isn’t be lost:通信健壮
At most one process may fail:至多一个进程出问题
推论:
没有一个consensus算法。
FLP告诉我们,当消息时延没上限没有的时候(异步系统),不存在一个完美的consensus算法。 话句话说,在一个收窄的异步模型当中(异步环境并且至多一个节点宕机),一个consensus算法不能同时满足satety和liveness。
CAP:
Consistency, availability, partition tolerance不能同时达到

Consistency: 所有节点在看同一数据在同一时刻应该是同一状态(注意,这里的consistency和ACID中的不太一样)。
Availability: 节点失效不会阻止幸存节点继续工作。(针对节点失效)
Partition tolerance: 在消息丢失(网络故障或者单点故障)时,系统可以继续工作。(针对消息丢失)
不同的算法侧重点也不一样:
CA: 一些full strict quorum protocols。 比如two-phase commit
CP: 大部分的quorum protocols. 比如Paxos, RAFT
AP:protocols using conflict resolution. 比如 Dynamo,Gossip.
CA和CP在consistency方面都提供了 strong consistency。但他们的容错能力是不一样的,
CA不能容忍任何一个单点错误,而CP可以容忍一半以下的单点错误(参照Paxos)。
而在现有的分布式体系中,常常需要保证分区容错性,所以大多数情况下我们都需要在conssitency和availability中作抉择:
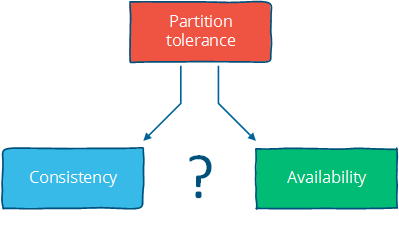
不同级别的consistency:
Strong consistency models (capable of maintaining a single copy)
Linearizable consistency: 每个节点按原有的时间顺序执行指令
Sequential consistency:每个节点按同样的时间顺序执行指令
Weak consistency models(not strong)
Client-centric consistency:
Causal consistency :
Eventual consistency :
简单来说,Strong consistency可以让我们把系统的所有节点等效想象成一个。 而weak consistency会出现不同的异常,但我们可以通过编码来处理这些异常。
3. Time and order
本章讲了一个分布式系统中的时间和顺序。对于order,定义的是先后顺序。而对于time来说,除了先后顺序以外,还包含了interpretation(如何解释时间),duration(定义事件间隔)
3.1 Order
对于order,有两种常见的order
Partial order
Total order
有个很简单的数学表示:
Definition(partial order): A binary relation R on a set A is a partial order if and only if it is
(1) reflexive: a <= a
(2) antisymmetric: a<=b AND b<= a => a=b
(3) transitive: a<=b AND b<=c => a<=c
Definition(total order):A binary relation R on a set A is a total order if and only if it is
(1) a partial order, and
(2) for any pair of elements a and b of A, < a, b > R or < b, a >
R.
比较起来,partial order定义了关系R的特性,而Total order强制每两个事件之间都应该存在关联。
3.2 Time
在不同的分布式系统中,time的流动速率可能是不一样的。“时间是按相同的速率在流动吗?”
“Global clock”: yes
“Local clock” : no, but…...
“No clock” : no!
这三种时钟,对应了三个系统模型
Synchronous: 支持Total Order
Partially synchronous:一种Partial order. 本地有序,跟远程无序。
Asynchronous:另一种Partial order. 本地有序,远程需要交互才能确定顺序。
Global clock:
理想状态下,这是指分布式的每个节点共享同一个时钟,保证”total order”,即系统范围内的任意两个操作都可以被赋予顺序。
Cassandra就是建立在同步时钟的基础上,它利用全局的时间戳来判断那个写操作生效。
换句话说,你可以比较两个不同节点上的时间戳来判断顺序

“Local Clock”:
Local clock 是指每个节点有一个本地时钟(注意,时钟的表现形式有多种,比如时间戳),我们保证本地的每两个操作都是可以被赋予顺序的。它提供了一种(注意,是一种!)“partial order”:本地的所有事件都是有序的,跨节点之间的事件时无序的。
换句话说,你不能通过比较本地时间戳和远程时间戳来判断两个操作的顺序,你不能直接比较两个不同节点上的时间戳。
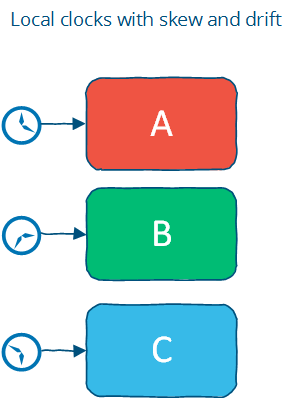
“No Clock”:
这里的没有时钟clock,我们可以使用Vector clock或者causality(意味着我们不能定义间隔的长短)。它提供了另一种partial order:可以确定本地的顺序,跨节点之间的顺序需要由message change来确定。它不能使用duration!
3.3 如何使用Order和Time?
How is time used in a distributed system?
Order在分布式系统中非常重要:
确定操作的顺序可以保证正确性
确定操作的顺序可以解决资源争夺时候的先后问题
而一个Global clock可以确定整个系统的的order(即使节点之间没有交流)。如果没有Global clock,我们需要通过communication 来确定顺序。
而Time可以用在failure detector上。Time 可以用在确定“high latency”还是”link is down”。即通过延迟来判断系统究竟是延迟多了,还是宕机了。这里,就引入了一个问题, failure detector!
3.4 系统中的逻辑时钟
但是,在整个系统中使用真的时钟很昂贵。
Lamport clock:
A Lamport clock is simple. Each process maintains a counter using the following rules:
Whenever a process does work, increment the counter
Whenever a process sends a message, include the counter
When a message is received, set the counter tomax(local_counter, received_counter) + 1
弱点:比方说出现了partition 情况,这个时钟就出现问题了。
Vector clock:
即给每节点都定一个计数,相当于每个节点都维护自己的一个lamport clock。
弱点:每个节点都要占一位,太昂贵了。 有很多研究致力于减少时钟的位数。
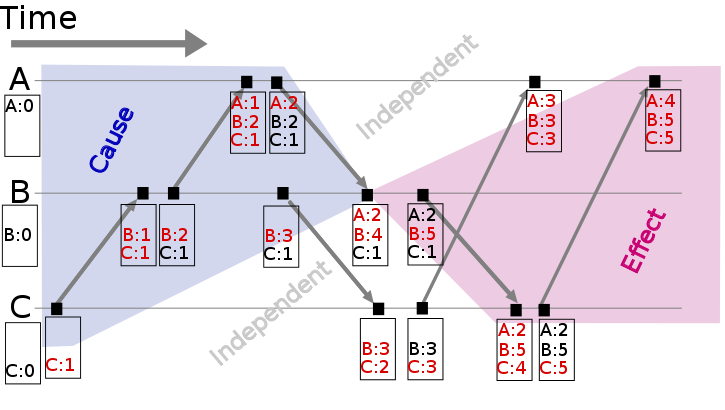
3.5 Failure detector
在分布式系统中,一个节点需要“知道”另一个节点是出故障了还是仅仅因为网络延迟。理论上来说,我们可以通过合理的延迟时间来判断,但是,什么是合理的延迟时间呢?这个很难确定。
这个时候,我们就用到Failure detector了。简单来说,failure detector用 “heartbeat messages” 和 “timers” 来实现。即不断发送“心跳信息”之后计算时间。而衡量Failure detector,有两个重要特性: completeness 和 accuracy.
Strong completeness: Every crashed process is eventually suspected byevery correct process
Weak completeness: Every crashed process is eventually suspected bysome correct process.
Strong accuracy: No correct process is suspected ever.
Weak accuracy: Some correct process is never suspected.
通过不断的给一个分布式系统加限制,我们可以得到下面这个图,它解释了我们解决某个某个问题所需要的条件。
Reliable broadcast:
Consensus (Atomic broadcast)
Termination Reliable Broadcast (Non-blocking atomic commit)
Clock synchronization.
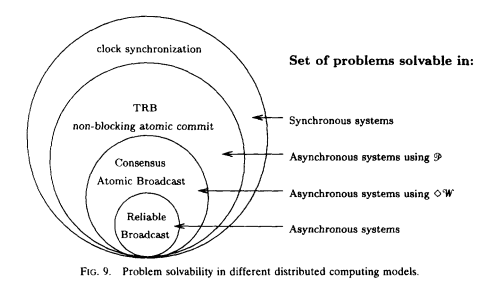
上图表示在不同的系统中,我们可以解决的问题。值得注意的是,在一个异步系统中,如果我们加了 evetually weak failure detector(eventually weak accuracy + weak completeness),我们便可以解决consensus问题了。这是一个很有用的推论。FLP告诉我们即使在一个收窄的异步系统中,也不能解决consensus,但一旦加上了<>W ,就可以解决了。
3.6 总结
讨论Time + Order + Synchronous要具体情况具体分析,并不是每个分布式系统都要强制这些特性,在很多情况下,通过放松对某个方面的限制,我们可以得到更加好的成果。
4. Replication: preventing divergence
分布式系统中经常会出现Replication. 这个章节在于介绍“preventing divergence”的Replication 策略,目的是保证不出现“不同”。
4.1 两个基本的replication模型
Synchronous replication 和 Asynchronous replication是两个最基础的模型,后续讲解的算法都是这两个模型的具体实现。
Synchronous replication

在这种情况下,一次写要接受所有其他节点的回复。也就是,系统的性能依赖于最差的服务器。
Asynchronous replication:
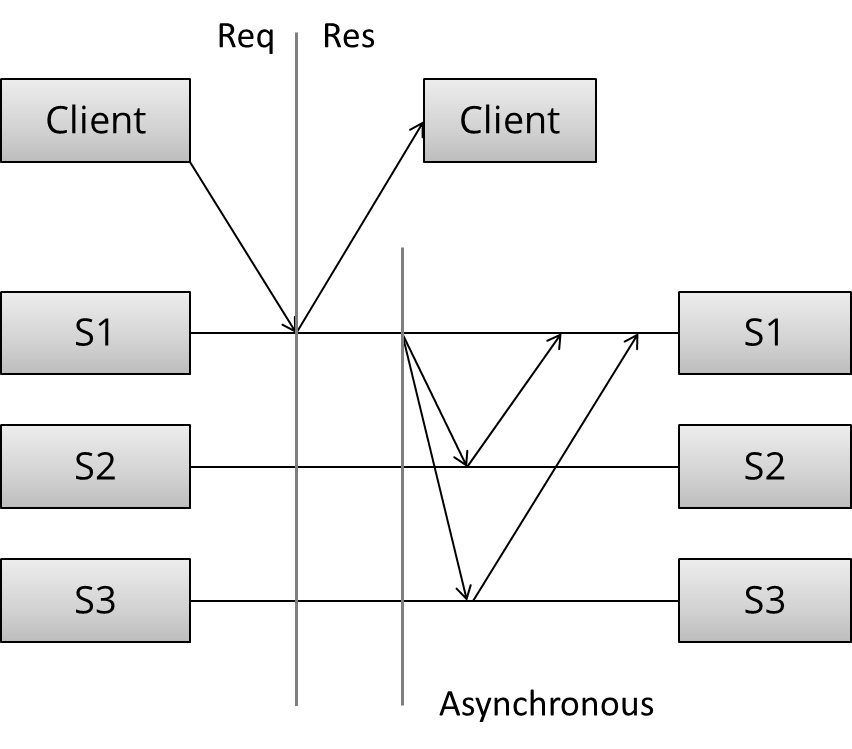
4.2 两种处理Replication的策略
有两种处理Replication的策略:第一种是保证不出现“不同”,第二种是要处理“不同”
Replication methods that prevent divergence (single copy systems)
Replication methods that risk divergence (multi-master systems)
Single copy system让整个系统“表现的像是一个节点”。每当部分节点宕机,系统可以保证只有一个active的值,还有,可以保证这个值被大家接受(其实就是consensus问题)
另外,consensus的解决也之间作用于mutual exclusion, leader election, multicast, atomic broadcast.
4.3 Single copy consistency 的算法
用来维护single-copy consistency的算法有:
1n messages (asynchronous primary/backup)
2n messages (synchronous primary/backup)
4n messages (2-phase commit, multi-Paxos)
6n messages (3-phase commit, Paxos with repeated leader election)
需要区分的是,上述算法都是为了保证single-copy,但是他们的容错能力是不同的。注意区分算法和容错能力。比如前两种算法设计理想状态都能保证一致性。但一旦出错,出现不一致,这是它容错性的问题。
4.4 Primary/backup
一个节点作为主机,所有的update都作用在主机上,之后把log传递到其余的副本。对于synchrounous来说(“update”+”acknowledge recipet”). 而对于asynchronous来说 (“update”.
例子:MySQL就是采用的异步P/B来进行数据备份。
缺陷: 就在于容错的缺陷(比如主机挂掉),就会产生很多问题(副本写入未写入?)。
4.5 Two phase commit (2PC)
1. Voting: coordinator 给所有的participants发提议,participants同意之后把数据存到缓冲区,并回ACK
2. Decision: 拿到所有肯定的ACK后,coordinator发送commit请求
这个在synchronous P/B 的基础上,增加了一次回复,相当于允许系统回滚。比方说主机在等待ACK的时候挂了,那么缓冲区的数据将被丢弃。
缺点: 只能保证CA, 不能保证P

4.6 Single copy中可以保证P的consensus算法
当我们看上述几种算法的时候,我们发现他们并没有保证P这个性质,下面,我们来讨论可以保证P的算法
Single-copy中保证P的consensus算法:
Paxos:
Raft
ZAB:Zookeeper atomic broadcast.
4.7 总结
Primary/Backup
Single, static master
Replicated log, slaves are not involved in executing operations
No bounds on replication delay
Not partition tolerant
Manual/ad-hoc failover, not fault tolerant, "hot backup"
2PC
Unanimous vote: commit or abort
Static master
2PC cannot survive simultaneous failure of the coordinator and a node during a commit
Not partition tolerant, tail latency sensitive
Paxos
Majority vote
Dynamic master
Robust to n/2-1 simultaneous failures as part of protocol
Less sensitive to tail latency
5. Replication: weak consistency model protocols
第四章中提到的各个算法都是为了保证single-copy,也就是强一致性。在这一章节里,我们关注第二种策略:处理“不同”。即我们允许出现不同(而且不同是正常的),我们要做的就是如何处理这些不同然后得出正确的结果。
而允许不同处理不同的过程就违反了strong consistency,而转向了eventual consistency:这些节点可以有不一样的状态,但是我保证到最后他们会趋于一致。
值得注意的是Dynamo, Cassandra等分布式数据库为了提供A都部分舍弃了C, 毫无例外的提供了eventual consistency。而自上而下,我们总结一下Dynamo的设计思路是:
consistent hashing to determine key placement
partial quorums for reading and writing
conflict detection and read repair via vector clocks and
gossip for replica synchronization:当新加入节点或者节点恢复的时候,需要节点之间进行同步,Dynamo用的是gossip协议(基于分布式failure detector 和 membership的)
通过consistent hashing来确定数据存放位置,利用Partial quorums来读写(W,R ,N),通过vector clocks来探测处理冲突, 利用Gossip协议来维持failure detector 和 membership.
6. 我的问题
在这个教程里,并没有特别详尽得阐述一些问题,下面,我把我觉得重要或者自己不清楚的点列出来,以后有机会了再深入的学习:
CAP的理解。不同算法对应的是哪两个特性?为什么Paxos对应CP,二段提交对应AP? 这个我存在疑问。
不同级别的consistency model。有很多不同的分类,需要确定一下。
Consensus算法和atomic broadcast等问题的等价性。
Dynamo 详细研究
Gossip 的用法? 依照论文来说,Gossip是为了同步节点,它的具体过程是什么?如何运作的?
update算法
Paxos 和 Raft 的对比。
Zookeeper的使用
分布式事务的判断
- 总结:Distributed systems for fun and profit
- Distributed system for fun and profit笔记1
- Smashing The Stack For Fun And Profit
- Smashing The Stack For Fun And Profit
- Method Replacement for Fun and Profit
- poj 2522 Partitioning for fun and profit
- Git Hooks for Fun and Profit
- Using Uninitialized Memory for Fun and Profit
- UVA 10581 Partitioning for fun and profit
- [转载]Smashing The Stack For Fun And Profit
- [译文]Smashing The Stack For Fun And Profit
- 堆栈溢出:Smashing The Stack For Fun And Profit
- 堆栈溢出:smashing the stack for fun and profit[译文]
- Abuse of the Linux Kernel for Fun and Profit
- Smashing the Stack for Fun and Profit by Aleph One
- Faking Touch Events on iOS for Fun and Profit
- Reverse engineering NAND Flash for fun and profit
- UVA 10581 - Partitioning for fun and profit(数论递推)
- 排序算法三归并排序
- Educational Codeforces Round 26总结
- 蓝桥杯练习题 BEGIN-2 序列求和
- (三)Angular4 英雄征途HeroConquest-初始化组件文件介绍
- 网络协议的综合思考 及 网络体系: OSI vs TCP/IP
- 总结:Distributed systems for fun and profit
- SSH面密码登陆设置失败一直需要输入密码可能原因分析
- Android 网络连接基本方式
- 基础排序(四)
- QTableView 数据操作
- TCP三次握手、四次握手过程,以及原因分析
- Angular2学习 Http通信
- keil中的头文件是放在哪个文件夹里的
- [PAT乙级]1019. 数字黑洞 (20)


