DL超级大火锅
来源:互联网 发布:第一财经知乎 编辑:程序博客网 时间:2024/04/27 13:22
0x00 文章来由
DL问题不断整理
0x01 卷积层学习卷积核?
该问题来自于知乎: https://www.zhihu.com/question/39022858,里面说到

0x02 loss很低,但是accuracy一直在50%左右一般是什么原因,1500张图片做train
最可能 overfitting,数据集不够?参数设置不对?
问实验室一圈无果
base_lr降低一点,step num降低到5000,对于1500张图片训练集的效果可以提高到66.7%
0x03 YOLO的原理是什么
YOLO用于检测能达到实时级别
官网:https://pjreddie.com/darknet/yolo/
知乎专栏解释原理:
https://zhuanlan.zhihu.com/p/24916786?refer=xiaoleimlnote
https://zhuanlan.zhihu.com/p/25236464
0x04 fine tune是什么意思,如何做
http://blog.csdn.net/dcxhun3/article/details/51852616
所谓fine tune就是用别人训练好的模型,加上我们自己的数据,来训练新的模型。fine tune相当于使用别人的模型的前几层,来提取浅层特征,然后在最后再落入我们自己的分类中。
fine tune的好处在于不用完全重新训练模型,从而提高效率,因为一般新训练模型准确率都会从很低的值开始慢慢上升,但是fine tune能够让我们在比较少的迭代次数之后得到一个比较好的效果。在数据量不是很大的情况下,fine tune会是一个比较好的选择。但是如果你希望定义自己的网络结构的话,就需要从头开始了。
http://www.cnblogs.com/alexcai/p/5469478.html
0x05 relu层如果失活如何看,或者说任意层的blob有没有好的方式输出
0x06 sshd命令与watch命令
0x07 如果一个国家,生到男孩就停止,生到女孩就继续,那最后的男女比例是多少
最后结果是1:1
举个直观点的例子。一开始有2000个家庭,第一次生育生了1000男,1000女。生了1000个女的家庭继续生,那么第二次生育结果为500男,500女。生了500个女的家庭继续生,那么第二次生育结果为250男,250女。以此类推,那么结果就是一比一了。推广到一开始有个家庭,生男概率为,剩女概率为的情况。那么每一次生育的家庭,都是上一次生出了女性的家庭。记每一次生育的家庭数量为,那么在第次生育的家庭的数量第次生育的结果为:男 ,女那么无论和为多大,男女比例总是.这类题目总是有直觉上的解法,而不是上来就推公式。面试中这类题目最重要的就是最快找到解,然后才是理论推导。祝好运。
作者:Steve Chow
链接:https://www.zhihu.com/question/19821790/answer/138734433
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
0x08 如何提高FoodAI的accuracy
上resnet,或者finetune,但是finetune用imagenet感觉效果不会有太好
0x09 co-train
两个网络互喂,前一个网络需要有很高confidence
0x0A CNN特征图是什么
一本字典里有N多个字,一本词典里有N多个词,一本句典里……有句典吗……在字那一层,它就是一遍一遍地看,有这个字吗有那个字吗,在哪个位置。再上一层就再一遍一遍地看,有这个词吗有那个词吗,在哪里。换成图像,字典有如边缘特征等等底层特征,在底层很难表达,直接用上面的比较概念的的层看吧:轮子特征去卷一遍,出来的图就是有轮子的地方会被激活(显示出来就是灰度高些咯),车牌特征、车窗特征等等亦如此。
作者:Stark Einstein
链接:https://www.zhihu.com/question/31318081/answer/51784721
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
feature map 由卷积核(Fliter) 和输入做卷积运算得到一个 Fliter 对应卷积后得到一个 feature map不同的Filter (不同的 weight, bias) ,卷积以后得到不同的 feature map,提取不同的特征(得到对应 specialized neuro)举例:同一层: Fliter1 的w1,b1 运算后提取的是 形状边缘的特征: feature map1 Fliter2 的w2,b2 运算后提取的是 颜色深浅的特征: feature map2下一层: Fliter3 的w3,b3 运算后提取的是 直线形状的特征: feature map3 Fliter4 的w4,b4 运算后提取的是 弧线形状的特征: feature map4 Fliter5 的w5,b5 运算后提取的是 红色深浅的特征: feature map5 Fliter6 的w6,b6 运算后提取的是 绿色深浅的特征: feature map6
作者:花花儿
链接:https://www.zhihu.com/question/31318081/answer/182488143
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
再放上一张一看就懂的图

0x0B CNN的conv层学习到的是什么
应该是学习到的是kernel和其组合

conv layer有参数

斯坦福手写数字可以看出,对于conv层的weight就是kernel
来自:caffe in a day
0x0C L1距离和L2距离分别指的什么
L1距离指的曼哈顿距离,2个点在标准坐标系上的绝对轴距总和
x| = √( x[1]2 + x[2]2 + … + x[n]2 )

详见 曼哈顿距离 百度百科
L2距离指的是欧式距离,即2个点的空间真实距离
|x| = √( x[1]2 + x[2]2 + … + x[n]2 )
详见 欧式距离 百度百科
0x0D 交叉验证
在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预报了一次而且仅被预报一次。把每个样本的预报误差平方加和,称为PRESS(predicted Error Sum of Squares)。
留一法交叉验证:假设有N个样本,将每一个样本作为测试样本,其它N-1个样本作为训练样本。这样得到N个分类器,N个测试结果。用这N个结果的平均值来衡量模型的性能。普通交叉验证:我理解的是K倍交叉验证(k-fold cross validation):将所有样本分成K份,一般每份样本的数量相等或相差不多。取一份作为测试样本,剩余K-1份作为训练样本。这个过程重复K次,最后的平均测试结果可以衡量模型的性能。另外:建议题主善用搜索,google搜索“留一法交叉验证”,第一个结果就有非常详细的介绍。附链接:交叉验证(Cross-validation) –zz_ousman_新浪博客
作者:Jason Gu
链接:https://www.zhihu.com/question/23561944/answer/24952652
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
0x0E 双线性插值
图像处理概念
双线性插值,顾名思义就是两个方向的线性插值加起来(这解释过于简单粗暴,哈哈)。所以只要了解什么是线性插值,分别在x轴和y轴都做一遍,就是双线性插值了。
线性插值的概念也非常简单粗暴,就是两个点A,B,要在AB中间插入一个点C(点C坐标在AB连线上),就直接让C的值落在AB的值的连线上就可以了。
如A点坐标(0,0),值为3,B点坐标(0,2),值为5,那要对坐标为(0,1)的点C进行插值,就让C落在AB线上,值为4就可以了。
但是如果C不在AB的线上肿么办捏,所以就有了双线性插值。如图,已知Q12,Q22,Q11,Q21,但是要插值的点为P点,这就要用双线性插值了,首先在x轴方向上,对R1和R2两个点进行插值,这个很简单,然后根据R1和R2对P点进行插值,这就是所谓的双线性插值。

详见:http://www.cnblogs.com/linkr/p/3630902.html
0x0F opencv SVM
opencv SVM 简单例子
opencv SVM+HOG
0x10 梯度弥散
梯度下降法(以及相关的L-BFGS算法等)在使用随机初始化权重的深度网络上效果不好的技术原因是:梯度会变得非常小。具体而言,当使用反向传播方法计算导数的时候,随着网络的深度的增加,反向传播的梯度(从输出层到网络的最初几层)的幅度值会急剧地减小。结果就造成了整体的损失函数相对于最初几层的权重的导数非常小。这样,当使用梯度下降法的时候,最初几层的权重变化非常缓慢,以至于它们不能够从样本中进行有效的学习。这种问题通常被称为“梯度的弥散”.
详见:http://blog.csdn.net/losteng/article/details/51020552
0x11 梯度下降vs随机梯度下降
梯度下降类似于在山的某一点环顾四周,计算出下降最快的方向(多维),然后踏出一步,这属于一次迭代,更新一次\theta 值;
随机梯度下降不会计算斜率最大的方向,而是每次只选择一个或某一批样本踏出一步,更新\theta 值,再选择下一个样本更新。
https://www.zhihu.com/question/40892922
0x12 协方差矩阵
http://www.cnblogs.com/chaosimple/p/3182157.html
从物理意义上说,就是计算各维度之间的相关性(前提是已经经过白化)。
由于样本特征均值白化后为0,各特征方差一样,计算得到的协方差矩阵,其中元素的值越大,则说明对应下标的特征之间相关性越高。
PCA就是基于这种性质。
https://www.zhihu.com/question/24283387
0x13 caffe test.txt里面需要打标签吗
你如果要算准确率肯定要有label,格式和train的一样就行
具体如何你直接看对应数据读取的cpp,如果是txt里读取,对应的应该是个叫data layer的cpp
有时候数据读取也自己写的,数据比较复杂的情况,比如做检测的时候,并不是一个图片一个label,而是有很多矩形框,会自己写相应的cpp
0x14 fc看作conv层

0x15 CNN learning from Scratch
就是从头开始学
https://www.quora.com/What-does-learning-from-scratch-mean
0x16 Transfer Learning
Transfer learning 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练数据集。就跟其他知友回答的那样,考虑到大部分数据或任务是存在相关性的,所以通过transfer learning我们可以将已经学到的parameter 分享给新模型从而加快并优化模型的学习不用像之前那样learn from zero.
作者:刘诗昆
链接:https://www.zhihu.com/question/41979241/answer/123545914
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
0x17 learning算法总览

0x18 CNN顶端是一个线性分类器吗
softmax或者svm分类器,详见斯坦福手写数字
softmax通常作为输出层,关于softmax详见
http://blog.csdn.net/han_xiaoyang/article/details/49999583
0x19 SGD



0x1A BP

0x1B fine-tune

对于小dataset,只train分类器;对于大dataset,只train后几层




Fine-tune技巧

详见教程:http://nbviewer.jupyter.org/github/BVLC/caffe/blob/tutorial/examples/completed/03-fine-tuning.ipynb
0x1C caffe文件夹

0x1D data augmentation

http://blog.csdn.net/xg123321123/article/details/52885061
0x1E Debug 技巧






0x1F caffe solver参数意义

首先说明一个概念:在caffe中的一次迭代iterration指的是一个batch,而不是一张图片。下面就主要说下2个概念
test_iter: 在测试的时候,需要迭代的次数,即test_iter* batchsize(测试集的)=测试集的大小,测试集batchsize可以在prototx文件里设置
test_interval:interval是区间的意思,所有该参数表示:训练的时候,每迭代500次就进行一次测试。
caffe在训练的过程是边训练边测试的。训练过程中每500次迭代(也就是32000个训练样本参与了计算,batchsize为64),计算一次测试误差。计算一次测试误差就需要包含所有的测试图片(这里为10000),这样可以认为在一个epoch里,训练集中的所有样本都遍历以一遍,但测试集的所有样本至少要遍历一次,至于具体要多少次,也许不是整数次,这就要看代码,大致了解下这个过程就可以了.
详见: http://blog.csdn.NET/iamzhangzhuping/article/details/49993899
http://www.cnblogs.com/denny402/p/5074049.html
http://blog.csdn.net/cyh_24/article/details/51537709
0x20 做fine tune的时候,使用的mean文件是imagenet的,还是现有图片的
关于这个问题,有很多说法:
https://groups.google.com/forum/#!topic/caffe-users/vLSHG1r1VUo
0x21 实验室server跑两个gpu,会报Multi-GPU execution not available
makefile config文件里的USE NCCL设置了吗
当电脑中有多个GPU时,默认使用GPU0。如果想使用其他的GPU,可以将该文件内容修改如下:
./build/tools/caffe train --solver=examples/testXXX/solver.prototxt --gpu 2注意,caffe中默认编号从0开始,因而–GPU 2的意思是使用第3个GPU。
如果要使用多个GPU,可以使用如下命令:
./build/tools/caffe train --solver=examples/testXXX/solver.prototxt --gpu 0,1,2,3则使用0,1,2,3这4个GPU。
如果要使用所有的GPU,可使用如下命令:
./build/tools/caffe train --solver=examples/testXXX/solver.prototxt --gpu all注意,使用的GPU越多,开始初始化时时间越久。当然,训练速度越快。
0x22 DGX nVidia的caffe镜像如何使用
从镜像拷贝,然后如果想用caffe,可以用which命令,或者全盘搜索
#全盘搜索find / -print|grep FILENAME0x23 DGX docker中如何不终止容器
直接关掉xshell即可,不要exit容器
但是如果重开一个端口连到同一个容器,所有的东西都同步
0x24 Tencent服务器用什么传文件
服务器装有rz上传和sz下载命令
http://blog.csdn.net/kobejayandy/article/details/13291655
0x25 Linux如何查找
which,比如which caffe
详见五种查找命令:http://www.kuqin.com/linux/20091009/70532.html
全盘搜索方法为 find / -print|grep FILENAME
0x26 root@localhost表示什么
linux中[root@localhost root]#第一、二个root分别表示什么意思啊?[root@localhost ~]# 表示什么意思?
答:
root@localhost root中第一个root表示当前登陆的为root账户
localhost是主机名称
第二个root表示当前的目录为root目录 #表示当前为root权限
[root@localhost ~]#中的~表示当前在登陆用户的家目录
root用户的家目录为/root,其他用户通常为/home/用户名,但可以改变
家目录主要保存每个用户的登陆信息,个人偏好及一些个人文件等
0x27 如何看有没有train对
看是否收敛—loss是不是降低,test accuracy是不是在增加
0x28 windows编写的脚本,xftp到Linux总报not found错
之前有说是文件尾问题,但是试过并没有用
在windows编写的service脚本(无sh为后缀的)在linux中使用,使用vim打开文件,使用:set ff=unix,就可以将文件转换为linux识别的格式。
详见:http://blog.csdn.net/faryang/article/details/52348029
0x29 Syntax error: redirection unexpected
执行这个脚本一直报错
##!/usr/bin/env sh#!/bin/bash#By Bill#GPU_ID=3NET=finetune_googlenet_food101SOLVER=finetune_googlenet_foodai101_solver.prototxtTOOLS=caffeWEIGHTS=./bvlc_googlenet.caffemodel#set -x#set -e#LOG=logs/${NET}.txt.`date +'%Y-%m-%d_%H-%M-%S'`LOG=logs/${NET}.logexec &> >(tee -a "$LOG")echo Logging output to "$LOG"#./build/tools/caffe train --solver=./examples/food_tst/${SOLVER} --weights=./examples/food_tst/bvlc_googlenet.caffemodel --gpu=5$TOOLS train \ --solver=${SOLVER} \ --gpu=4,5 #--snapshot=examples/food_tst/googlenet_food100_aug_iter_5000.solverstate --weights=$WEIGHTS \ #| tee $LOG
原因是这个应该用bash来跑,我用了sh
详见:https://stackoverflow.com/questions/2462317/bash-syntax-error-redirection-unexpected
0x2A 安装 python/pip/numpy/matplotlib
详细教程:http://blog.csdn.net/sinat_28224453/article/details/51462935
但是安装matplotlib的时候用的官网pip安装教程
http://matplotlib.org/users/installing.html
0x2B win10关闭自动更新
http://www.ghost580.com/win10/2016-10-21/17295.html
0x2C caffe如何直接test,比如直接测pre-trained model的accuracy

0x2D vim打开文档每行最后都有^M
在《Linux程序设计》指定的网站上下载了源码,使用的时候却一直出问题。提示:”bash: ./here1:/bin/sh^M:损坏的解释器: 没有该文件或目录“。之后用vi编辑器打开文件,发觉每一行的最后有浅蓝色的字符’^M’。才知道了问题所在
其实并没什么奇怪的,出现这种错误的原因是因为Linux和Windows文本文件的行结束标志不同。在Linux中,文本文件用\n表示回车换行,而Windows用\r\n表示回车换行。所以在Linux中使用Windows的文本文件常常会出现错误。为了避免这种错误,Linux提供了两种文本格式相互转化的命令:dos2unix和unix2dos,dos2unix把\r\n转化成\n,unixtodos把\n转化成\r\n。
命令dos2unix和unix2dos的使用非常简单,格式为:dos2unix filename
详见:https://zhidao.baidu.com/question/585300366.html
删除行尾的^M:
%s/\r//g0x2E 制作自己的镜像&导出镜像
制作镜像
参照:http://www.docker.org.cn/book/docker/docer-save-changes-10.html
- 首先使用docker ps 命令获得自己的容器的id
- 然后把这个镜像保存为huwang-ncaffe
- 执行完docker commit命令之后,会返回新版本镜像的id号
huwang@dgx-1:~$ docker commit dab8373a95ba huwang-ncaffesha256:985b0908c2f97ccd7980d34e232f395830712cce6cd619f6c2bb171dc348320b执行完之后,在docker images就可以看到自己的image了
导出镜像
参照:http://blog.csdn.net/pipisorry/article/details/51330126
命令:
huwang@dgx-1:~/huwang$ docker export dab8373a95ba > huwang-ncaffe.tar直接通过container id导出
0x2F caffe solver参数
test_iter和test_interval是最令人confuse的参数
caffe在训练的过程是边训练边测试的。训练过程中每500次迭代(也就是32000个训练样本参与了计算,batchsize为64),计算一次测试误差。计算一次测试误差就需要包含所有的测试图片(这里为10000),这样可以认为在一个epoch里,训练集中的所有样本都遍历以一遍,但测试集的所有样本至少要遍历一次,至于具体要多少次,也许不是整数次,这就要看代码,大致了解下这个过程就可以了
//test_iter* batchsize(测试集的)=测试集的大小//相当于train 500次迭代 test一次test_iter: 100test_interval: 5000x30 正则表达式,两个字符串之间的
比如要取出image与/之间的
image/(.*?)/
0x31 朴素贝叶斯
所有的feature都是独立的
0x32 cross entropy
代表两个distribution有多接近,如果一摸一样的算出来是0,我们在logistics回归就是要找一个分布与真实分布差别最小的分布
为什么要用cross entropy,因为square error的时候,距离目标很远loss也很缓慢

0x33 logistic回归 vs linear回归

logistics的值只能在0~1,linear的值可以任意
http://blog.csdn.net/songzitea/article/details/43352353
logistics回归是通过sigmoid函数,可以做分类问题(2分类)
linear回归是可以预测任意值
0x34 全连接层的作用是什么
作者:魏秀参
链接:https://www.zhihu.com/question/41037974/answer/150522307
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
全连接层(fully connected layers,FC)在整个卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。在实际使用中,全连接层可由卷积操作实现:对前层是全连接的全连接层可以转化为卷积核为1x1的卷积;而前层是卷积层的全连接层可以转化为卷积核为hxw的全局卷积,h和w分别为前层卷积结果的高和宽(注1)。目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling,GAP)取代FC来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代FC的网络通常有较好的预测性能。具体案例可参见我们在ECCV’16(视频)表象性格分析竞赛中获得冠军的做法:「冠军之道」Apparent Personality Analysis竞赛经验分享 - 知乎专栏 ,project:Deep Bimodal Regression for Apparent Personality Analysis在FC越来越不被看好的当下,我们近期的研究发现,FC可在模型表示能力迁移过程中充当“防火墙”的作用。具体来讲,假设在ImageNet上预训练得到的模型为 ,则ImageNet可视为源域(迁移学习中的source domain)。微调(fine tuning)是深度学习领域最常用的迁移学习技术。针对微调,若目标域(target domain)中的图像与源域中图像差异巨大(如相比ImageNet,目标域图像不是物体为中心的图像,而是风景照,见下图),不含FC的网络微调后的结果要差于含FC的网络。因此FC可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,FC可保持较大的模型capacity从而保证模型表示能力的迁移。(冗余的参数并不一无是处。) 注1: 有关卷积操作“实现”全连接层,有必要多啰嗦几句。以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:“filter size = 7, padding = 0, stride = 1, D_in = 512, D_out = 4096”经过此卷积操作后可得输出为1x1x4096。如需再次叠加一个2048的FC,则可设定参数为“filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。
注1: 有关卷积操作“实现”全连接层,有必要多啰嗦几句。以VGG-16为例,对224x224x3的输入,最后一层卷积可得输出为7x7x512,如后层是一层含4096个神经元的FC,则可用卷积核为7x7x512x4096的全局卷积来实现这一全连接运算过程,其中该卷积核参数如下:“filter size = 7, padding = 0, stride = 1, D_in = 512, D_out = 4096”经过此卷积操作后可得输出为1x1x4096。如需再次叠加一个2048的FC,则可设定参数为“filter size = 1, padding = 0, stride = 1, D_in = 4096, D_out = 2048”的卷积层操作。
0x35 git是保存文件的改变吗?
其实是快照,而不是差异
除了SVN和Git实际上的区别之外,其底层的实现也遵循完全不同的设计理念。不同于SVN跟踪文件的差异,Git版本控制模型是基于快照的。例如,一个SVN提交由和添加到仓库中原始文件进行比较组成。Git,另一方面,记录在每次提交中,每一个文件的全部内容。
svn
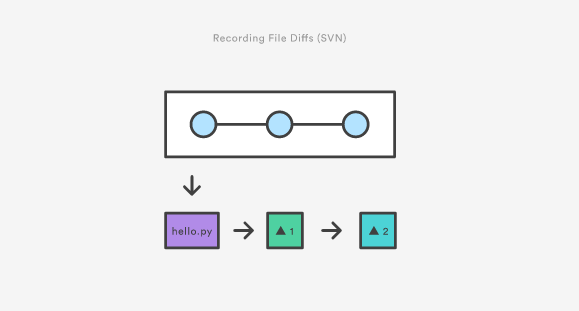
git
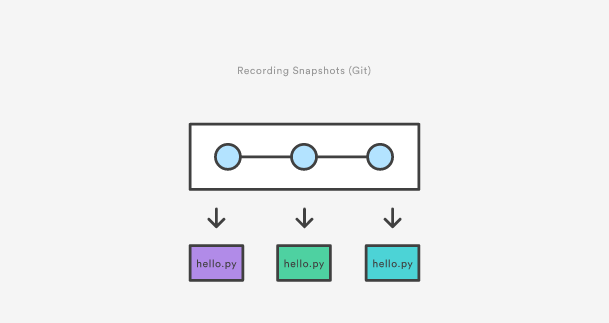
这使得Git的很多操作比SVN要快很多,因为文件的特定版本不需要从它的不同分支中进行“组装”——在Git的内部数据库中,每个文件的完整版本是立即有效的。
Git的快照模式对它的版本控制模型的每一个方面有着深远的影响的, 从它的分支和合并工具到它的协作工作流。
详见:http://angelzou.github.io/06-29-2015-git-saving-changes.html
0x36 cannot remove Device or resource busy
删不掉文件,被占用
用lsof +D /path找到那个进程占用,然后kill -9 pid
详见:https://unix.stackexchange.com/questions/11238/how-to-get-over-device-or-resource-busy
0x37 computational graph
(1)可以将计算图看作是一种用来描述function的语言,图中的节点node代表function的输入(可以是常数、向量、张量等),图中的边代表这个function操作。
(2)看到一个计算图的例子,我们就可以很容易地写出其对应的function。

详见:http://blog.csdn.net/u013527419/article/details/70184690
0x38 inception结构google进化史
Inception v1 - v4 papers 发展历程
先上Paper列表:
[v1] Going Deeper with Convolutions, 6.67% test error, http://arxiv.org/abs/1409.4842
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error, http://arxiv.org/abs/1502.03167
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error, http://arxiv.org/abs/1512.00567
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error, http://arxiv.org/abs/1602.07261
大体思路:
Inception v1的网络,将1x1,3x3,5x5的conv和3x3的pooling,stack在一起,一方面增加了网络的width,另一方面增加了网络对尺度的适应性;
v2的网络在v1的基础上,进行了改进,一方面了加入了BN层,减少了Internal Covariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,另外一方面学习VGG用2个3x3的conv替代inception模块中的5x5,既降低了参数数量,也加速计算;
v3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299,更加精细设计了35x35/17x17/8x8的模块;
v4研究了Inception模块结合Residual Connection能不能有改进?发现ResNet的结构可以极大地加速训练,同时性能也有提升,得到一个Inception-ResNet v2网络,同时还设计了一个更深更优化的Inception v4模型,能达到与Inception-ResNet v2相媲美的性能。
更多的细节可以参考论文中的描述。
详见:
http://www.jianshu.com/p/33197e469414
http://blog.csdn.net/u010025211/article/details/51206237
https://www.zhihu.com/question/50370954
http://blog.csdn.net/langb2014/article/details/52787095
http://www.cnblogs.com/Allen-rg/p/5833919.html
0x39 selective search
前期工作利用图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。
详见:http://blog.csdn.net/mao_kun/article/details/50576003
0x3A deep dream如何实现
详见:https://www.zhihu.com/question/31572348
0x3B caffemodel里面记录了什么
http://blog.csdn.net/jiongnima/article/details/72904526
0x3C jliang导师:v-loam
0x3D data augmentation
常用的方法:
Color Jittering:对颜色的数据增强:图像亮度、饱和度、对比度变化(此处对色彩抖动的理解不知是否得当);
PCA Jittering:首先按照RGB三个颜色通道计算均值和标准差,再在整个训练集上计算协方差矩阵,进行特征分解,得到特征向量和特征值,用来做PCA Jittering;
Random Scale:尺度变换;
Random Crop:采用随机图像差值方式,对图像进行裁剪、缩放;包括Scale Jittering方法(VGG及ResNet模型使用)或者尺度和长宽比增强变换;
Horizontal/Vertical Flip:水平/垂直翻转;
Shift:平移变换;
Rotation/Reflection:旋转/仿射变换;
Noise:高斯噪声、模糊处理;
Label shuffle:类别不平衡数据的增广,参见海康威视ILSVRC2016的report;另外,文中提出了一种Supervised Data Augmentation方法,有兴趣的朋友的可以动手实验下。
http://blog.csdn.net/u010555688/article/details/60757932
0x3E 深度学习tips总结
1、shuffle:在框架允许的前提下,每个epoch要shuffle一次;2、扩展数据集:小数据集容易使得模型过拟合,但过分扩展会使得大都相同的数据,需采取一定的方法,避免出现相同的样本(尝试中);3、在非常小的子数据集上训练进行过拟合,再在整个数据集上训练:以确定网络可以收敛;4、始终是用dropout将过拟合的几率最小化:当神经元节点超过256时,就要使用dropout,Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning [Gal Yarin & Zoubin Ghahramani,2015].;5、MAX pooling会更快,避免使用LRN pooling;6、避免使用sigmoid/tanh:代价昂贵,容易饱和,网络越深,越容易停止反向传播;而更简单有效的ReLU和PreLU能够促进稀疏性,其反向传播也更加鲁棒,Deep Sparse Rectifier Neural Networks;7、在max pooling之前不要使用ReLU和PreLU,在保持计算之后再使用;8、不要使用ReLU:虽然它们是很好的非线性函数,但是在微调模型时会阻碍反向传播,在初始化阶段被卡住,无法得到任何微调效果;可以使用PreLU以及一个很小的乘数(通常是0.1),收敛更快;9、经常使用批标准化(Batch Normalization):可以允许更快的收敛以及更小的数据集,节省时间以及资源,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift [Sergey Ioffe & Christian Szegedy,2015]。;10、相对于减去平均值,更倾向于将数据压缩到[-1, +1]:针对训练和部署的技巧,而非提升性能;11、小型化模型,并尝试 ensemble:以方便用户及服务,并提升准确度;12、尽可能使用 xavier 初始化:可在较大的全连接层上使用,避免在CNN层使用,An Explanation of Xavier Initialization(by Andy Jones);13、如果输入数据有空间参数,可以尝试端到端CNN:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size [Forrest N. Iandola et. al. 2016];14、修改模型,只要可能就使用 1x1 的 CNN 层,它的位置对提高性能很有帮助。15、假如你要利用模型或你自己的层来制作模板,记得把所有东西参数化,否则你得重建所有二进制文件。16、了解正在着手的任务及使用的结构,莫要盲目地复制模型;http://blog.csdn.net/u010555688/article/details/60753098
0x3F 绘制caffe accuracy与loss曲线
http://blog.csdn.net/u010555688/article/details/60873102
https://www.zhihu.com/question/36652304
0x40 Focal loss
https://www.zhihu.com/question/63581984
http://www.win7999.com/news/142051630.html
http://blog.csdn.net/u014380165/article/details/77019084
0x41 caffe中DATA层crop_size
利用crop_size这种方式可以剪裁中心关注点和边角特征,mirror可以产生镜像,弥补小数据集的不足
在caffe中,如果定义了crop_size,那么在train时会对大于crop_size的图片进行随机裁剪,而在test时只是截取中间部分(详见/caffe/src/caffe/data_transformer.cpp):
//We only do random crop when we do training. if (phase_ == TRAIN) { h_off = Rand(datum_height - crop_size + 1); w_off = Rand(datum_width - crop_size + 1); } else { h_off = (datum_height - crop_size) / 2; w_off = (datum_width - crop_size) / 2; } }从上述的代码可以看出,如果我们输入的图片尺寸大于crop_size,那么图片会被裁剪。当 phase 模式为 TRAIN 时,裁剪是随机进行裁剪,而当为TEST 模式时,其裁剪方式则只是裁剪图像的中间区域。
http://blog.csdn.net/u010417185/article/details/52651761
0x42 python图像操作
注意,不是import Image,而是from PIL import Image
详见:http://blog.csdn.net/chenriwei2/article/details/42071517
数组操作
图像用Image.open的形式加载进来后是一个PIL的图像对象,为了方便用Numpy进一步操作,需要用array()转化为数组。
# !/usr/bin/python# -*- coding:utf-8 -*-from PIL import Imagefrom numpy import *# 加载图像(路径必须双\\)pil_img = Image.open('D:\\1.tif')# 转化为数组img = array(pil_img)# 获取图像参数height,width = img.shape[0:2]# 访问像素value = img[i,j,k] #[行,列,channel]采用数组处理完以后再变回图像:
pil_im2 = Image.fromarray(uint8(img))详见:http://blog.csdn.net/jenny1000000/article/details/62897710
0x43 pip批量update过期库
查看系统里过期的python库,可以用pip命令
pip list #列出所有安装的库pip list --outdated #列出所有过期的库对于列出的过期库,pip也提供了更新的命令
pip install --upgrade 库名但此命令不支持全局全部库升级。
在stackoverflow上有人提供了批量更新的办法,一个循环就搞定(注意–upgrade后面的空格)
import pipfrom subprocess import callfor dist in pip.get_installed_distributions(): call("pip install --upgrade " + dist.project_name, shell=True)另外的也有人提到用 pip-review ,不想安装就没用
pip install pip-reviewpip-review --local --interactive详见:http://www.cnblogs.com/luckjun/p/4958338.html
0x44 dl tips
http://blog.csdn.net/dongapple/article/details/75499390
论文笔记(Fine-grained classification)
https://hsh.blog.ustc.edu.cn/2015/12/09/555/
0x45 linux 看一个文件夹多少文件
ls | wc -w是查看有多少个文件及文件夹
ls | wc -c这个查看目录下多少个文件.
0x46 python3 中numpy与scipy问题
报错
Failed cleaning build dir for scipy
试了几种都无效,直到找到 https://stackoverflow.com/questions/26575587/cant-install-scipy-through-pip 的下面一段话,在win10中
In windows 10, most options will not work. Follow these steps:In Windows 10 with CMD, you cannot download scipy directly using most of the well known commands like wget, cloning scipy github, pip install scipy, etcTo install, go to pythonlibs .whl files , and if you are using python 2.7 32 bit then download numpy-1.11.2rc1+mkl-cp27-cp27m-win32.whl and scipy-0.18.1-cp27-cp27m-win32.whl or if python 2.7 62 bit then download numpy-1.11.2rc1+mkl-cp27-cp27m-win_amd64.whl and scipy-0.18.1-cp27-cp27m-win_amd64.whlAfter downloading,save the files under your python directory , in my case it was c:\>python27Then run:pip install C:\Python27\numpy-1.11.2rc1+mkl-cp27-cp27m-win32.whl pip install C:\Python27\scipy-0.18.1-cp27-cp27m-win32.whlNote:scipy needs numpy as dependency, so that's why we are downloading numpy before scipy.cp27 in .whl files means that these files are meant for python 2.7 and cp33 stands for python 3.x speciafically >=3.3另外,这个非官方网站要记住:http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
0x47 定下来prototxt batch_size=64,一张卡和4张卡跑出来一样吗
每个都是64,然后真实的batch_size为64*4,因为每个GPU都会单独使用prototxt文件
gpu的作用不只是加速,核数会对结果有影响,不改prototxt,用不同核数,结果可能不同

0x48 全连接层
全连接层实际上也是一种卷积层,只是它的卷积核大小和原数据大小一致。因此它的参数基本和卷积层的参数一样。
详见:http://www.cnblogs.com/denny402/p/5072746.html
0x49 Linux远程拷贝
使用scp命令
scp -r huwang@10.0.109.58:/mnt/StorageArray2_DGX1/huwang/dataset/newFood724_aug_11_7/newFood724_train_lmdb newFood724_aug_11_7/newFood724_train_lmdb命令使用详见:http://www.cnblogs.com/autumnvivi/articles/3447964.html
且chmod 777 要用 -R 大写
0x4A vs2013 密钥
Visual Studio Ultimate 2013:BWG7X-J98B3-W34RT-33B3R-JVYW9Visual Studio Premium 2013:FBJVC-3CMTX-D8DVP-RTQCT-92494Visual Studio Professional 2013:XDM3T-W3T3V-MGJWK-8BFVD-GVPKYTeam Foundation Server 2013 KEY:MHG9J-HHHX9-WWPQP-D8T7H-7KCQG0x4B batchsize 应该怎么设置
设置一个中间值,需要自己测试
详见:https://www.zhihu.com/question/32673260
wxw分享的一篇文章
0x4C PS+pid
打印命令
0x4D caffe new layer
http://blog.csdn.net/shuzfan/article/details/51322976
0x4E Hard negative mining
一般来说训练一个SVM分类器,需要正负两个样本,比如,对于person detection,训练集图片中一幅图片中作为正样本的人物样本很少,但是随机产生用于训练的负样本(非人物样本)可能远远大于正样本,这样训练出来的SVM效果并不好,所以利用Hard negative mining方法,从负样本中选取出一些有代表性的负样本,使得分类器的训练结果更好。这是我的理解,最近在看ML方面的东西,有说的不对的还望指出。附带一篇博文给你参考:http://blog.csdn.net/u011534057/article/details/51222112
作者:张喵喵
链接:https://www.zhihu.com/question/46292829/answer/102747087
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
0x4F git版本回退
命令git reflog用来记录你的每一次命令:
$ git reflogea34578 HEAD@{0}: reset: moving to HEAD^3628164 HEAD@{1}: commit: append GPLea34578 HEAD@{2}: commit: add distributedcb926e7 HEAD@{3}: commit (initial): wrote a readme fileGit必须知道当前版本是哪个版本,在Git中,用HEAD表示当前版本,也就是最新的提交3628164…882e1e0(注意我的提交ID和你的肯定不一样),上一个版本就是HEAD^,上上一个版本就是HEAD^^,当然往上100个版本写100个^比较容易数不过来,所以写成HEAD~100。
回退命令:
$ git reset --hard 3628164HEAD is now at 3628164 append GPL详见:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000/0013744142037508cf42e51debf49668810645e02887691000
0x50 use_global_stats
I actually made a mistake in my previous reply. You should set use_global_stats = False in training, and use_global_stats = True in testing (deploy.txt).
When use_global_stats is set to False, the batch normalization layer is tracking the stats (mean/var) of its inputs. This is the desired behavior during training. When use_global_stats is set to True, the layer will use pre-computed stats (learned in training) to normalize the inputs.
see: https://github.com/BVLC/caffe/issues/3347
0x51 Hard example
难例(或叫做难样本,Hard Example,Hard Negative,Hard Instance)是指利用第一次训练的分类器在负样本原图(肯定没有人体)上进行行人检测时所有检测到的矩形框,这些矩形框区域很明显都是误报,把这些误报的矩形框保存为图片,加入到初始的负样本集合中,重新进行SVM的训练,可显著减少误报。
0x52 caffe从快照中恢复
${caffe}/build/tools/caffe train \ -gpu 1,2 \ -solver solver.prototxt \ -snapshot *.solverstate0x53 bias and variance
详见:http://blog.csdn.net/huruzun/article/details/41457433
0x54 逻辑回归 vs SVM
详见:https://www.zhihu.com/question/24904422/answer/92164679
0x55 Loss 为什么用 cross entropy
详见:https://zhuanlan.zhihu.com/p/26268559
0x56 Bagging VS Boosting
详见:http://blog.csdn.net/scythe666/article/details/78408365
0x57 CNN中的神经元怎么定义
详见:https://zhuanlan.zhihu.com/p/22038289?refer=intelligentunit
神经元应该是多个输入,一个输出,也就是说对应每个conv层,输出是多大比例,就应该说多少个神经元
0x58 watch命令
不断刷新一个命令
0x59 全连接层
假设你是一只小蚂蚁,你的任务是找小面包。你的视野还比较窄,只能看到很小一片区域。当你找到一片小面包之后,你不知道你找到的是不是全部的小面包,所以你们全部的蚂蚁开了个会,把所有的小面包都拿出来分享了。全连接层就是这个蚂蚁大会~如果提前告诉你全世界就只有一块小面包,你找到之后也就掌握了全部的信息,这种情况下也就没必要引入fc层了
作者:田star
链接:https://www.zhihu.com/question/41037974/answer/150552142
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
0x5A 先验概率 后验概率 极大似然估计
https://zhuanlan.zhihu.com/p/24423230
以下是原答案:
一句话概括,
先验概率:执因求果。
后验概率:知果求因。
极大似然概率:知果求最可能的原因。
例子: 已知车祸有一定概率会导致堵车,此处车祸是因,堵车是果。
P(堵车) 是先验概率。
P(车祸|堵车)是后验概率。
我们有以下三个随机事件
A 警察查酒驾
B 下班高峰
C 车祸
三个事件都会导致堵车,在已知堵车的情况下,哪个事件最可能发生,即是极大似然估计,即求 argmax(P(A|堵车),P(B|堵车),P(C|堵车))。argmax返回A,B,C三者中使得概率最大的事件。
手机码字 暂时写那么多。
有人看再更。
本人新手,欢迎指正错误。
0x5B 核函数
作者:王赟 Maigo
链接:https://www.zhihu.com/question/24627666/answer/28440943
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我来举一个核函数把低维空间映射到高维空间的例子。下面这张图位于第一、二象限内。我们关注红色的门,以及“北京四合院”这几个字下面的紫色的字母。我们把红色的门上的点看成是“+”数据,紫色字母上的点看成是“-”数据,它们的横、纵坐标是两个特征。显然,在这个二维空间内,“+”“-”两类数据不是线性可分的。 我们现在考虑核函数,即“内积平方”。这里面是二维空间中的两个点。这个核函数对应着一个二维空间到三维空间的映射,它的表达式是:可以验证,在P这个映射下,原来二维空间中的图在三维空间中的像是这个样子:
我们现在考虑核函数,即“内积平方”。这里面是二维空间中的两个点。这个核函数对应着一个二维空间到三维空间的映射,它的表达式是:可以验证,在P这个映射下,原来二维空间中的图在三维空间中的像是这个样子: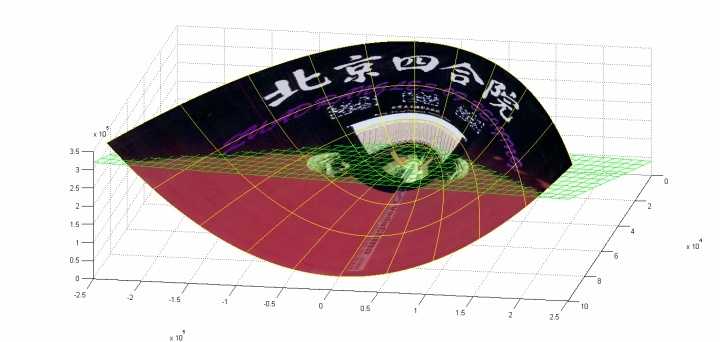 (前后轴为x轴,左右轴为y轴,上下轴为z轴)注意到绿色的平面可以完美地分割红色和紫色,也就是说,两类数据在三维空间中变成线性可分的了。而三维中的这个判决边界,再映射回二维空间中是这样的:
(前后轴为x轴,左右轴为y轴,上下轴为z轴)注意到绿色的平面可以完美地分割红色和紫色,也就是说,两类数据在三维空间中变成线性可分的了。而三维中的这个判决边界,再映射回二维空间中是这样的: 这是一条双曲线,它不是线性的。================================================如上面的例子所说,核函数的作用就是隐含着一个从低维空间到高维空间的映射,而这个映射可以把低维空间中线性不可分的两类点变成线性可分的。当然,我举的这个具体例子强烈地依赖于数据在原始空间中的位置。事实中使用的核函数往往比这个例子复杂得多。它们对应的映射并不一定能够显式地表达出来;它们映射到的高维空间的维数也比我举的例子(三维)高得多,甚至是无穷维的。这样,就可以期待原来并不线性可分的两类点变成线性可分的了。================================================在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:1) 线性:2) 多项式:3) Radial basis function:4) Sigmoid:我举的例子是多项式核函数中的情况。在实用中,很多使用者都是盲目地试验各种核函数,并扫描其中的参数,选择效果最好的。至于什么样的核函数适用于什么样的问题,大多数人都不懂。很不幸,我也属于这大多数人,所以如果有人对这个问题有理论性的理解,还请指教。================================================核函数要满足的条件称为Mercer’s condition。由于我以应用SVM为主,对它的理论并不很了解,就不阐述什么了。使用SVM的很多人甚至都不知道这个条件,也不关心它;有些不满足该条件的函数也被拿来当核函数用。
这是一条双曲线,它不是线性的。================================================如上面的例子所说,核函数的作用就是隐含着一个从低维空间到高维空间的映射,而这个映射可以把低维空间中线性不可分的两类点变成线性可分的。当然,我举的这个具体例子强烈地依赖于数据在原始空间中的位置。事实中使用的核函数往往比这个例子复杂得多。它们对应的映射并不一定能够显式地表达出来;它们映射到的高维空间的维数也比我举的例子(三维)高得多,甚至是无穷维的。这样,就可以期待原来并不线性可分的两类点变成线性可分的了。================================================在机器学习中常用的核函数,一般有这么几类,也就是LibSVM中自带的这几类:1) 线性:2) 多项式:3) Radial basis function:4) Sigmoid:我举的例子是多项式核函数中的情况。在实用中,很多使用者都是盲目地试验各种核函数,并扫描其中的参数,选择效果最好的。至于什么样的核函数适用于什么样的问题,大多数人都不懂。很不幸,我也属于这大多数人,所以如果有人对这个问题有理论性的理解,还请指教。================================================核函数要满足的条件称为Mercer’s condition。由于我以应用SVM为主,对它的理论并不很了解,就不阐述什么了。使用SVM的很多人甚至都不知道这个条件,也不关心它;有些不满足该条件的函数也被拿来当核函数用。
0x5C recall 与 precision
精确率(Precision)为TP/(TP+FP),即为在预测为1的sample中,预测正确(实际为1)的占比
召回率(Recall)为TP/(TP+FN),即为在实际为1的sample中,预测正确(预测为1)的占比

0x5D ROC曲线 VS AUC
ROC曲线(Receiver operating characteristic curve)曲线其实是多个混淆矩阵的结果组合,如果在上述模型中我们没有定好阈值,而是将模型预测结果从高到低排序,将每个概率值依次作为阈值,那么就有多个混淆矩阵。
对于每个混淆矩阵,我们计算两个指标TPR(True positive rate)和FPR(False positive rate)。
TPR=TP/(TP+FN)=Recall,TPR 就是召回率,即为在实际为1的sample中,预测正确(预测为1)的占比
FPR=FP/(FP+TN),FPR是:实际为 0 的sample中,预测为 1 的占比
我们以FPR为x轴,TPR为y轴画图,就得到了ROC曲线。

在画ROC曲线的过程中,若有一个阈值,高于此阈值的均为1,低于此阈值的均为0,则认为此模型已完美的区分开好坏用户。此时1的预测准确率(TPR)为1,同时0的预测错误率(FPR)为0,ROC曲线经过(0,1)点。
AUC(Area Under Curve)的值为ROC曲线下面的面积,若如上所述模型十分准确,则AUC为1。
但现实生活中尤其是工业界不会有如此完美的模型,一般AUC均在0.5到1之间,AUC越高,模型的区分能力越好,上图AUC为0.81。若AUC=0.5,即与上图中红线重合,表示模型的区分能力与随机猜测没有差别。若AUC真的小于0.5,请检查一下是不是0,1标签标反了,或者是模型真的很差。。。
作者:京东白条
链接:https://www.zhihu.com/question/30643044/answer/222274170
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ROC 曲线 & AUC 另一说
ROC曲线
对于0,1两类分类问题,一些分类器得到的结果往往不是0,1这样的标签,如神经网络,得到诸如0.5,0,8这样的分类结果。这时,我们人为取一个阈值,取不同的阈值,得到的最后的分类情况也就不同。
如下面这幅图:

蓝色表示原始为负类分类得到的统计图,红色为正类得到的统计图。那么我们取一条直线,直线左边分为负类,右边分为正,这条直线也就是我们所取的阈值。
ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。这两个值由上面四个值计算得到,公式如下:
TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。
TPR=TP/(TP+FN)FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。
FPR=FP/(FP+TN)
放在具体领域来理解上述两个指标,如在医学诊断中,判断有病的样本。那么尽量把有病的揪出来是主要任务,也就是第一个指标TPR,要越高越好。
而把没病的样本误诊为有病的,也就是第二个指标FPR,要越低越好。

我们可以看出,左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对。
点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR<FPR),这个医生说你有病,那么你很可能没有病,医生C的话我们要反着听,为真庸医。
还是一开始的那幅图,假设如下就是某个医生的诊断统计图,直线代表阈值。我们遍历所有的阈值,能够在ROC平面上得到如下的ROC曲线。

AUC
AUC值为ROC曲线所覆盖的区域面积,显然,AUC越大,分类器分类效果越好。
作者:小爷Souljoy
链接:http://www.jianshu.com/p/a3060acbd086
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
0x5E one-hot vector
考虑多类情况。非onehot,标签是类似0 1 2 3…n这样。而onehot标签则是顾名思义,一个长度为n的数组,只有一个元素是1.0,其他元素是0.0。例如在n为4的情况下,标签2对应的onehot标签就是 0.0 0.0 1.0 0.0使用onehot的直接原因是现在多分类cnn网络的输出通常是softmax层,而它的输出是一个概率分布,从而要求输入的标签也以概率分布的形式出现,进而算交叉熵之类。
作者:郑文勋
链接:https://www.zhihu.com/question/53021606/answer/133150781
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- DL超级大火锅
- Java超级大火锅
- C/C++超级大火锅
- [置顶] C/C++超级大火锅
- python 语法大火锅
- 火锅
- 火锅
- 火锅
- 台大DL-week2笔记
- 超级ASP大分页
- 超级大逃亡
- 超级大 正整数 乘法
- 超级大整数相乘
- 的撒个共和国火锅火锅火锅火锅火锅火锅火锅
- 台大DL—week1 笔记
- dl
- DL
- DL
- Go channel 使用示例代码
- POJ3276 -- Face The Right Way 反转问题
- 《战狼2》,我可以说点什么
- Thinkphp 配置参考资料
- 因地制宜:为企业数据中心添加自动化
- DL超级大火锅
- POJ 2342 Anniversary party 树形DP
- daytime
- 分析并比较Java几种集合遍历的方式
- linux下的软硬链接及其inode
- 26函数
- 数据中心模块化:兼顾安全与节能
- 度度熊与邪恶大魔王
- HDU 1170


