kafka简介
来源:互联网 发布:8个数据库设计典型实例 编辑:程序博客网 时间:2024/04/26 15:33
分布式流平台
Apache Kafka™是一个分布式流平台,我们认为流式平台(a streaming platform)有以下三个关键的能力:
1.它允许你发布和订阅流记录(streams of records)。从这个角度上说,它接近于一个消息队列或者企业消息系统。
2.它允许你以容错的方式存储流记录。
3.它允许你即时处理消息流。
Kafka的优势体现在两大类应用上:
1.构建实时流数据管道,在应用系统间可靠稳定地获取数据。
2.构建实时流应用,它可以转换或者回应数据流(react to the streams of data)。
为了理解Kafka如何实现以上特性,让我们自底向上地探索一番。首先是一些概念:
1.Kafka以集群的方式运行在一台或多台服务器上。
2.Kafka存储流记录是以topic进行分类的
3.每条记录包含一个key、一个value和一个timestamp
Kafka有四个核心的API: 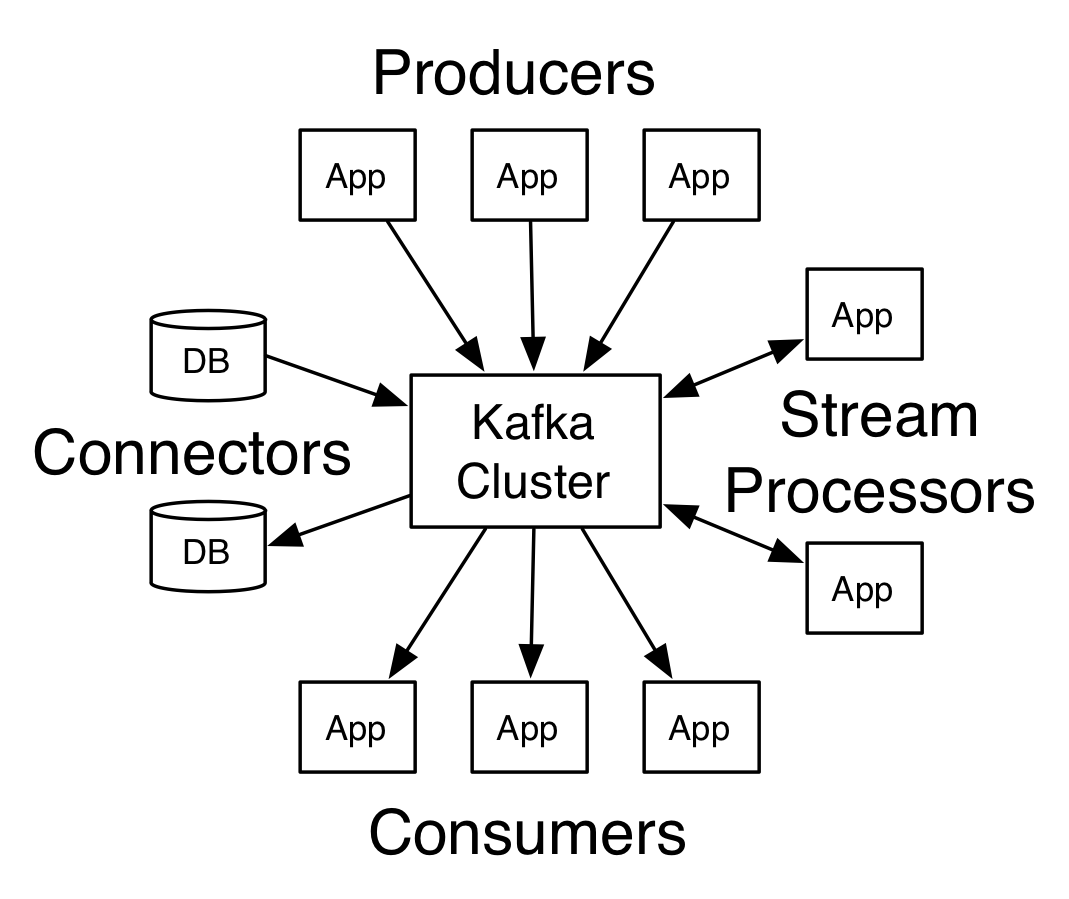
- 生产者API允许一个应用发布流记录到一个或多个Kafka topic上。
- 消费者API运行一个应用订阅一个或多个topics并处理流记录。
- 流API(Streams API)允许一个应用作为一个流处理器,消费一个或多个topics来的输入流、再生产出输入流到一个或多个topics,这样高效地把输入流转换为输出流。
- 连接器API允许构建和运行可重用的生产者或消费者去连接topics到应用系统或数据系统上。例如,一个连在关系型数据库的连接器能够捕获每张表的变化。
Kafka集群通信由一个简单、高性能、语言无关性的TCP协议完成。这个协议向后兼容旧版本。我们提供了一个面向Kafka的Java客户端,但客户端支持很多语言。
Topics and Logs
我们首先看一下流记录的核心抽象Kafka规约–topic。
topic是被发布记录的分类名。Topics在Kafka中通常是有多个订阅者的,一个topic可能有0个、1个或者多个订阅的消费者。对于每个topic,Kafka集群维持着下图这样的分区日志: 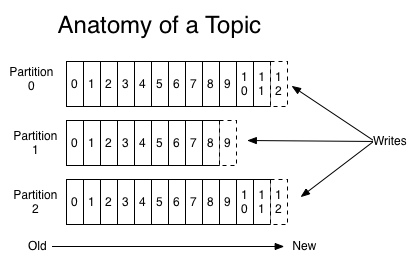
每个分区是一个有序、不可变的记录序列,该序列被持续地追加新记录–一个结构化的提交日志。分区里的记录都被分配了一个顺序採番id,我们称之为”offset”,它唯一确定了分区里的每条记录。
Kafka集群保存了所有发布的记录,无论记录是否被消费过。保存时间是可配置的。例如,如果保存策略被设置为2天,一条记录被发布后的2天内是可以被随时消费的,过了2天后该条记录就会被抛弃以释放存储空间。谈到数据大小,Kafka的性能是高效稳定的,因此存储很长时间也不是一个问题(Kafka’s performance is effectively constant with respect to data size so storing data for a long time is not a problem.)。
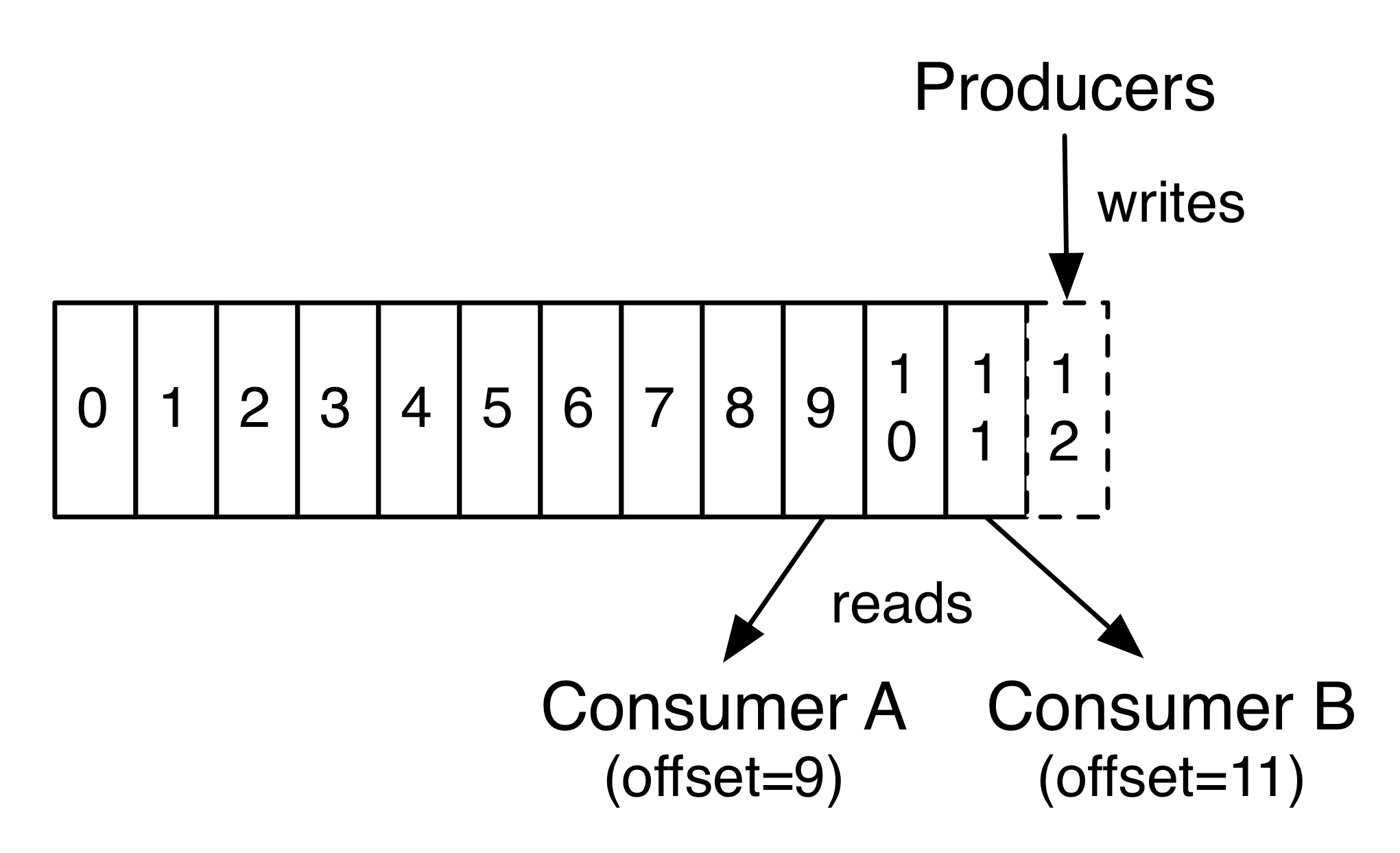
事实上,以每一个消费者为基准保存的唯一元数据是偏移量(offset),或者说该消费者在日志中的位置。偏移量由消费者控制,通常消费者在读取记录时会线性推进其偏移量,实际上当消费者能够控制偏移量后它能以任何想要的方式去消费数据。例如,消费者能够重置为一个更旧的偏移量去重复处理数据或者跳到最新的数据开始消费。
这种组合特征意味着Kafka消费者非常廉价,它们在日志里游走(they can come and go)对集群或者其它消费者没有什么影响。例如,你可以用命令行工具”tail”出任何一个topic的内容,而不影响一个已经存在的消费者对该topic的消费。
日志里的分区满足了多种目的。首先,它允许日志拓展存储到超过单个节点服务器大小的其他节点上。每个分区都要适配对应主机的服务器,但是一个topic可以有多个分区,因此可以解决单个服务器无法处理大量数据的情况。其次,分区充当并行度的单元–稍后会详细讨论这一点。
Distribution
日志分区分布在Kafka集群上的各台机器上,每台机器都可以处理数据和请求一个共享分区。每个分区按照配置数字进行复制,以达到容错目的。
每个分区有一台server充当”leader”,同时有多台或0台服务器充当”followers”。leader处理所有的读写请求,同时followers被动复制备份leader。如果leader挂掉,其中一台followers将自动成为新的leader。每一个服务器充当起一些分区的leader,并且又是其它分区的follower,这样集群能够较好地负载均衡。
Producers
生产者将数据发布到它们选择的topic上。生产者负责选择将哪一条记录分配到topic中的哪个分区上。它会以轮询的方式完成负载或者它会根据一些语义分区函数来完成。更多分区的使用是在下面的消费者里。
Consumers
消费者以分组名字给自己定义标签,每一个发布到topic的记录将被传递到每一个订阅消费组中的一个消费者实例上,消费者实例可能是分散的进程或者分散在不同的机器上。
如果所有的消费者有着相同的消费者组,那么记录将会被高效地负载到每一个消费者实例上。
如果所有的消费者有着不同的消费者组,那么每条记录将被通知到所有消费者进程上。
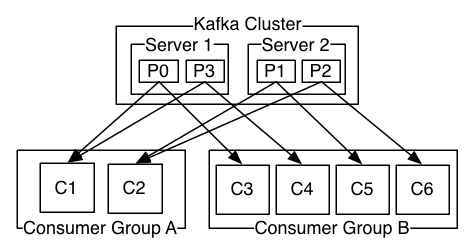
如上图所示,一个由2台服务器组成的Kafka集群有着4个分区(P0-P3),被2个消费者组订阅。消费者组A有2个消费者实例,消费者组B有4个消费者实例。
通常,topics有少量的消费者组,每一个组是一个”逻辑订阅者”。每一个组由多个消费者实例所组成,为的是可伸缩性和容错性。这就是”发布-订阅”语义,订阅者是一个消费者集群而不是单单一个进程(This is nothing more than publish-subscribe semantics where the subscriber is a cluster of consumers instead of a single process.)。
Kafka实现消费的方式是将日志中的分区拆分给消费者实例,以保证一个实例在任何一个点能及时”公平独占”该分区。维持组内消费者关系的过程由Kafka协议动态处理。如果一个新的实例加入消费者组,它将从该组其他消费者那儿接管一些分区。如果一个实例销毁了,它的分区将分配给其它存活的实例上。
Kafka只保证一个分区内的整体消费顺序,不保证不同分区间的消费顺序。分区排序连同按key分区数据排序的能力对于大多数系统来说都是足够的(Per-partition ordering combined with the ability to partition data by key is sufficient for most applications.)。如果你确实需要保证topic全局有序的话,那只能让一个消费者组里只有一个消费者实例。
Guarantees
Kafka提供如下保证:
- 生产者往一个特定topic分区里发送的消息会按照发送的顺序追加进去。这意味着,如果一个生产者前后发送了记录M1和M2,那么M1在日志里会比M2有着更低的偏移量。
- 消费者实例寻找记录的顺序是它们存储在日志中的顺序。
- 如果一个topic的副本数是N,我们将会容忍N-1个服务器宕机,并保证不会丢失数据。
原文来自Kafka官网:http://kafka.apache.org/intro
- Kafka-Kafka简介
- Kafka 简介
- kafka--简介
- kafka 简介
- Kafka 简介
- kafka简介
- Kafka 简介
- Kafka简介
- kafka简介
- Kafka简介
- kafka简介
- kafka简介
- kafka简介
- Kafka 简介
- kafka简介
- Kafka简介
- Kafka简介
- Kafka简介
- hdu
- 笨办法学 Python · 续 练习 2:创造力
- c++-模板不支持分离编译错误分析
- Spring的IOC
- 在activity中回传数据
- kafka简介
- maven pom.xml配置文件
- 自己遇到的一些问题的总结
- java 编写多线程应用程序,模拟多个人通过独木桥的模拟。 线程问题
- Quartz快速入门
- Shiro的注解(@RequiresRoles,@RequiresPermissions)授权不起作用
- 选择排序算法
- Struts2的自定义拦截器
- spfa的SLF 和 LLL优化算法


