【IO/NIO】Java NIO浅析
来源:互联网 发布:淘宝虚拟专营入口 编辑:程序博客网 时间:2024/06/05 15:17
NIO(Non-blocking I/O,在Java领域,也称为New I/O),是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式。
那么NIO的本质是什么样的呢?它是怎样与事件模型结合来解放线程、提高系统吞吐的呢?
本文会从传统的阻塞I/O和线程池模型面临的问题讲起,然后对比几种常见I/O模型,一步步分析NIO怎么利用事件模型处理I/O,解决线程池瓶颈处理海量连接,包括利用面向事件的方式编写服务端/客户端程序。最后延展到一些高级主题,如Reactor与Proactor模型的对比、Selector的唤醒、Buffer的选择等。
一、传统BIO模型分析
让我们先回忆一下传统的服务器端同步阻塞I/O处理(也就是BIO,Blocking I/O)的经典编程模型:
{ ExecutorService executor = Excutors.newFixedThreadPollExecutor(100);//线程池 ServerSocket serverSocket = new ServerSocket(); serverSocket.bind(8088); while(!Thread.currentThread.isInturrupted()){//主线程死循环等待新连接到来 Socket socket = serverSocket.accept(); executor.submit(new ConnectIOnHandler(socket));//为新的连接创建新的线程}class ConnectIOnHandler extends Thread{ private Socket socket; public ConnectIOnHandler(Socket socket){ this.socket = socket; } public void run(){ while(!Thread.currentThread.isInturrupted()&&!socket.isClosed()){死循环处理读写事件 String someThing = socket.read()....//读取数据 if(someThing!=null){ ......//处理数据 socket.write()....//写数据 } } }}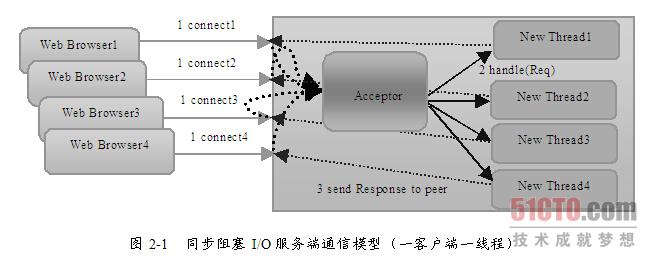
这是一个经典的每连接每线程的模型,之所以使用多线程,主要原因在于socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里;但CPU是被释放出来的,开启多线程,就可以让CPU去处理更多的事情。其实这也是所有使用多线程的本质:
- 利用多核。
- 当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
现在的多线程一般都使用线程池,可以让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很”贵”的资源,主要表现在:
- 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPU sy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
二、NIO是怎么工作的
很多刚接触NIO的人,第一眼看到的就是Java相对晦涩的API,比如:Channel,Selector,Socket什么的;然后就是一坨上百行的代码来演示NIO的服务端Demo……瞬间头大有没有?
我们不管这些,抛开现象看本质,先分析下NIO是怎么工作的。
所有的系统I/O都分为两个阶段:等待就绪和操作。举例来说,读函数,分为等待系统可读和真正的读;同理,写函数分为等待网卡可以写和真正的写。
需要说明的是等待就绪的阻塞是不使用CPU的,是在“空等”;而真正的读写操作的阻塞是使用CPU的,真正在”干活”,而且这个过程非常快,属于memory copy,带宽通常在1GB/s级别以上,可以理解为基本不耗时。
以socket.read()为例子:
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,函数会一直阻塞,直到收到数据,返回读到的数据。
对于NIO,如果TCP RecvBuffer有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。
最新的AIO(Async I/O)里面会更进一步:不但等待就绪是非阻塞的,就连数据从网卡到内存的过程也是异步的。
换句话说,BIO里用户最关心“我要读”,NIO里用户最关心”我可以读了”,在AIO模型里用户更需要关注的是“读完了”。
NIO一个重要的特点是:socket主要的读、写、注册和接收函数,在等待就绪阶段都是非阻塞的,真正的I/O操作是同步阻塞的(消耗CPU但性能非常高)。
三、如何结合事件模型使用NIO同步非阻塞特性
回忆BIO模型,之所以需要多线程,是因为在进行I/O操作的时候,一是没有办法知道到底能不能写、能不能读,只能”傻等”,即使通过各种估算,算出来操作系统没有能力进行读写,也没法在socket.read()和socket.write()函数中返回,这两个函数无法进行有效的中断。所以除了多开线程另起炉灶,没有好的办法利用CPU。
NIO的读写函数可以立刻返回,这就给了我们不开线程利用CPU的最好机会:如果一个连接不能读写(socket.read()返回0或者socket.write()返回0),我们可以把这件事记下来,记录的方式通常是在Selector上注册标记位,然后切换到其它就绪的连接(channel)继续进行读写。
下面具体看下如何利用事件模型单线程处理所有I/O请求:
NIO的主要事件有几个:读就绪、写就绪、有新连接到来。
我们首先需要注册当这几个事件到来的时候所对应的处理器。然后在合适的时机告诉事件选择器:我对这个事件感兴趣。对于写操作,就是写不出去的时候对写事件感兴趣;对于读操作,就是完成连接和系统没有办法承载新读入的数据的时;对于accept,一般是服务器刚启动的时候;而对于connect,一般是connect失败需要重连或者直接异步调用connect的时候。
其次,用一个死循环选择就绪的事件,会执行系统调用(Linux 2.6之前是select、poll,2.6之后是epoll,Windows是IOCP),还会阻塞的等待新事件的到来。新事件到来的时候,会在selector上注册标记位,标示可读、可写或者有连接到来。
注意,select是阻塞的,无论是通过操作系统的通知(epoll)还是不停的轮询(select,poll),这个函数是阻塞的。所以你可以放心大胆地在一个while(true)里面调用这个函数而不用担心CPU空转。
所以我们的程序大概的模样是:
interface ChannelHandler{ void channelReadable(Channel channel); void channelWritable(Channel channel); } class Channel{ Socket socket; Event event;//读,写或者连接 } //IO线程主循环: class IoThread extends Thread{ public void run(){ Channel channel; while(channel=Selector.select()){//选择就绪的事件和对应的连接 if(channel.event==accept){ registerNewChannelHandler(channel);//如果是新连接,则注册一个新的读写处理器 } if(channel.event==write){ getChannelHandler(channel).channelWritable(channel);//如果可以写,则执行写事件 } if(channel.event==read){ getChannelHandler(channel).channelReadable(channel);//如果可以读,则执行读事件 } } } Map<Channel,ChannelHandler> handlerMap;//所有channel的对应事件处理器 }四、优化线程模型
由上面的示例我们大概可以总结出NIO是怎么解决掉线程的瓶颈并处理海量连接的:
NIO由原来的阻塞读写(占用线程)变成了单线程轮询事件,找到可以进行读写的网络描述符进行读写。除了事件的轮询是阻塞的(没有可干的事情必须要阻塞),剩余的I/O操作都是纯CPU操作,没有必要开启多线程。
并且由于线程的节约,连接数大的时候因为线程切换带来的问题也随之解决,进而为处理海量连接提供了可能。
单线程处理I/O的效率确实非常高,没有线程切换,只是拼命的读、写、选择事件。但现在的服务器,一般都是多核处理器,如果能够利用多核心进行I/O,无疑对效率会有更大的提高。
仔细分析一下我们需要的线程,其实主要包括以下几种:
- 事件分发器,单线程选择就绪的事件。
- I/O处理器,包括connect、read、write等,这种纯CPU操作,一般开启CPU核心个线程就可以。
- 业务线程,在处理完I/O后,业务一般还会有自己的业务逻辑,有的还会有其他的阻塞I/O,如DB操作等。只要有阻塞,就需要单独的线程。
Java的Selector对于Linux系统来说,有一个致命限制:同一个channel的select不能被并发的调用。因此,如果有多个I/O线程,必须保证:一个socket只能属于一个IoThread,而一个IoThread可以管理多个socket。
另外连接的处理和读写的处理通常可以选择分开,这样对于海量连接的注册和读写就可以分发。虽然read()和write()是比较高效无阻塞的函数,但毕竟会占用CPU,如果面对更高的并发则无能为力。

五、一个简单故事讲NIO
假设某银行只有10个职员。该银行的业务流程分为以下4个步骤:
- 顾客填申请表(5分钟);
- 职员审核(1分钟);
- 职员叫保安去金库取钱(3分钟);
- 职员打印票据,并将钱和票据返回给顾客(1分钟)。
我们看看银行不同的工作方式对其工作效率到底有何影响。
(1) BIO方式
每来一个顾客,马上由一位职员来接待处理,并且这个职员需要负责以上4个完整流程。当超过10个顾客时,剩余的顾客需要排队等候。
我们算算这个银行一个小时到底能处理多少顾客?一个职员处理一个顾客需要10分钟(5+1+3+1)时间,一个小时(60分钟)能处理6个顾客,一共10个职员,那就是只能处理60个顾客。
可以看到银行职员的工作状态并不饱和,比如在第1步,其实是处于等待中。
这种工作其实就是BIO,每次来一个请求(顾客),就分配到线程池中由一个线程(职员)处理,如果超出了线程池的最大上限(10个),就扔到队列等待 。
(2) NIO方式
如何提高银行的吞吐量呢?
思路:分而治之,将任务拆分开来,由专门的人负责专门的任务。
具体来讲,银行专门指派一名职员A,A的工作就是每当有顾客到银行,他就递上表格让顾客填写,每当有顾客填好表后,A就将其随机指派给剩余的9名职员完成后续步骤。
我们计算下这种工作方式下银行一个小时到底能处理多少顾客?
假设顾客非常多,职员A的工作处于饱和中,他不断的将填好表的顾客带到柜台处理,柜台一个职员5分钟能处理完一个顾客,一个小时9名职员能处理:9*(60/5)=108。
可见工作方式的转变能带来效率的极大提升。
这种工作方式其实就NIO的思路。下图是非常经典的NIO说明图,mainReactor线程负责监听server socket,accept新连接,并将建立的socket分派给subReactor;subReactor可以是一个线程,也可以是线程池(一般可以设置为CPU核数),负责多路分离已连接的socket,读写网络数据,这里的读写网络数据可类比顾客填表这一耗时动作,对具体的业务处理功能,其扔给worker线程池完成。
可以看到典型NIO有三类线程,分别是mainReactor线程、subReactor线程、work线程。不同的线程干专业的事情,最终每个线程都没空着,系统的吞吐量自然就上去了。
(3) 异步方式
第二种工作方式有没有什么可以提高的地方呢?
仔细查看可发现第3步骤这3分钟柜台职员是在等待中度过的,那怎么能让柜台职员保持满负荷呢?
还是分而治之的思路,指派1个职员B来专门负责第3步骤。每当柜台员工完成第2步时,就通知职员B来负责与保安沟通取钱。这时候柜台员工可以继续处理下一个顾客。当职员B拿到钱之后,他会怎么办呢?他会通知顾客钱已经到柜台了,让顾客重新排队处理,当柜台职员再次服务该顾客时,发现该顾客前3步已经完成,直接执行第4步即可。
我们可以算算通过这种方法,银行的吞吐量能提高到多少。
假设职员B的工作非常饱和,柜台一个职员现在2分钟能处理完一个顾客,一个小时8名职员能处理:8*(60/2)=240。
在当今web服务中,经常需要通过RPC或者Http等方式调用第三方服务,这里对应的就是第3步,如果这步耗时较长,通过异步方式将能极大降低资源使用率。
jetty Continuations 就实现了上述异步方式,有兴趣的同学可以去尝试下(http://wiki.eclipse.org/Jetty/Feature/Continuations)。
NIO+异步的方式能让少量的线程(资源)做大量的事情,这适用于很多应用场景,比如代理服务、api服务、长连接服务等等,这些应用如果用同步方式将耗费大量机器资源。尽管NIO+异步能提高系统吞吐量,但其并不能让一个请求的等待时间下降,相反可能会增加等待时间。
更多互联网与金融技术精华:http://www.moxianbin.com/
- 【IO/NIO】Java NIO浅析
- 【IO/NIO】Java IO/NIO
- JAVA IO与NIO优劣浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- 【总结】Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- Java NIO浅析
- java IO & NIO
- Java NIO vs. IO
- POJ 2456 Aggressive cows——二分查找(最大化最小值)
- java实现翻转链表
- TCP连接的11种状态变迁
- 每日一题(24)—— const
- Java对GIF的简单删帧操作
- 【IO/NIO】Java NIO浅析
- Caffe基础系列【一】MNIST数据集的测试
- hadoop系列之一集群规划篇
- 函数模板不会进行自动的参数转换
- java面试题,各大企业常见的java笔试题之五
- 泛型简介,自定义泛型的应用及泛型在Dao层的应用
- linux常用工具命令
- 1+2+3+...+n,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)
- Webstorm打开失败,提示jdk版本太低


