Lucene的使用与重构
来源:互联网 发布:数据库系统基础知识 编辑:程序博客网 时间:2024/06/15 18:03
忽然一想好久不写博客了,工作原因个人原因,这些天一直希望一天假如36个小时该多好,但是,假如不可能。
由于近期在项目中接触了lucene,这个已经没有人维护的全文搜索框架,确实踩了不少坑,为什么用lucene呢?其实我也不知道
关于lucene原理和全文搜索引擎的一些介绍,园子里有这几篇写的还是很好的
http://www.cnblogs.com/skybreak/archive/2013/05/06/3063520.html
http://kb.cnblogs.com/page/52642/
由于完全没有接触过lucene,一开始当然是从X度,bing上搜索关于lucene.net的教程,发现找不到好用的,lucene已经好久没有维护了,如果细心阅读源码会发现许多匪夷所思的设计。对于lucene可以理解为一个数据库,lucene提供了添加数据(创建索引),以及快速全文检索的api。
通过学习,我们发现,lucene.net给我们很多对象
Lucene.Net.Store.Directory:lucene文档的存放目录,我这里把它理解为一张表,实际上这一张表的字段可以不一样
Lucene.Net.Documents.Documents:lucene文档,相当于一条数据
Lucene.Net.Index.IndexWriter:用于向Lucene.Net.Store.Directory中添加Lucene.Net.Documents.Documents
Lucene.Net.Analysis.Standard.StandardAnalyzer:词法分析器
当然,还有一系列查询的类,这里就不列举了,说了这么多,我这篇随笔主要介绍什么呢?
既然把lucene理解为一个数据库了,从框架使用者的角度看,不需要拘泥于lucene究竟是如何存储和检索数据的,当然,第一次使用时还是要学习的,但是写完了就会发现代码写的好繁琐啊,每次都要创建Directory,Analyzer写查询语句创建对象,比如项目一开始对站内所有信息进行检索,一次加入所有数据,搜索所有数据,没有问题,后来需要对另一个模块的信息进行单表检索,会发现代码逐渐开始乱了,但是由于时间问题和开发经验一开始很难想到好的设计。刚开始时,项目经理指导将每个需要全文搜索的对象先独立出来,实现一个接口,程序运行时反射实现该接口的类(暂且成他为LuceneModel),即可实现搜索,但是后来需求要实现两种语言的搜索,根据当前前端提供的cookie来查询指定语言的数据,于是我就又给每一个LuceneModel添加一个Language字段,并且Language字段的搜索是一个且的关系(在满足搜索关键字后并且该条数据的语言必须 为从cookie中读取的)。
显然,需要对搜索这个模块进行单独的维护了,这样修改方便,并且也可以供其他项目使用,也是软件设计原则吧!
IndexerAttribute
[AttributeUsage(AttributeTargets.Property, Inherited = false, AllowMultiple = false)] public class IndexerAttribute : Attribute { public bool Index; public bool Store; /// <summary> /// /// </summary> /// <param name="index">是否为其创建索引</param> /// <param name="store">是否存储原始数据</param> public IndexerAttribute(bool index,bool store) { Index = index; Store = store; } }
表示对模型具体字段的索引方式
LuceneDB
public abstract class LuceneDB:IDisposable { private ILunceneDBPathProvider_dbPathProvider = LunceneDBPathProviders.Current; private string _dbPath; protected System.IO.DirectoryInfo _sysDirectory; protected Lucene.Net.Store.Directory _luDirectory; protected Lucene.Net.Analysis.Standard.StandardAnalyzer _analyzer; protected Lucene.Net.Index.IndexWriter _indexWriter; protected bool _isOpen = false; public LuceneDB(string path) { _dbPath = path; } public LuceneDB() { } public void SetDBPath(Type type) { if (null == _dbPath) { _dbPath = _dbPathProvider.Get(type); } } public string DBPath { get { return _dbPath; } } protected abstract void Open(); public virtual void Dispose() { _analyzer.Close(); _analyzer.Dispose(); } }
首先LuceneDB,表示一个连接对象,有子类LuceneDBIndexer和LuceneDBSearcher,两者用到的资源不一样,所以提供了一个需要实现的Open方法。通常情况下一个Lucene文件夹下有多个索引文件夹,每个索引文件夹有着相似的数据结构(同一个数据类型),为了使这一个模块能够让别的项目使用,第一个要解决的问题就是Lucene文件夹位置的问题了,对于web项目,可以存在APPData也可以存在bin目录下,这里也照顾了下对于Console应用。
ILunceneDBPathProvider
public interface ILunceneDBPathProvider { string Get(Type type); }
默认的是一个AppDataLunceneDBPathProvider
public class AppDataLunceneDBPathProvider : ILunceneDBPathProvider { private string _prePath = AppDomain.CurrentDomain.BaseDirectory; public string Get(Type type) { return _prePath + @"\App_Data\Index\" + type.Name; } }
这样如果有需要检索的User类,他的lucene文件夹就为App_Data\Index\User
LuceneDBIndexer
public class LuceneDBIndexer: LuceneDB { private Dictionary<Type,IEnumerable<PropertyInfo>> _tempProps; public LuceneDBIndexer(string path) : base(path) { } public LuceneDBIndexer() { } protected override void Open() { if (_isOpen) { Dispose(); } if (!System.IO.Directory.Exists(DBPath)) { System.IO.Directory.CreateDirectory(DBPath); } _analyzer = new Lucene.Net.Analysis.Standard.StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30); _luDirectory = Lucene.Net.Store.FSDirectory.Open(new System.IO.DirectoryInfo(DBPath)); _indexWriter = new Lucene.Net.Index.IndexWriter(_luDirectory, _analyzer, true, Lucene.Net.Index.IndexWriter.MaxFieldLength.LIMITED); _isOpen = true; } public IEnumerable<PropertyInfo> GetProps(Type type) { if(null == _tempProps) { _tempProps = new Dictionary<Type, IEnumerable<PropertyInfo>>(); } if (!_tempProps.ContainsKey(type)) { _tempProps.Add(type, type.GetProperties().Where(prop => null != prop.GetCustomAttribute(typeof(IndexerAttribute), true))); } return _tempProps[type]; } public void Add<T>(T obj) { SetDBPath(typeof(T)); Open(); Document document = new Document(); foreach (var prop in GetProps(typeof(T))) { var value = prop.GetValue(obj)?.ToString(); if(null != value) { var attr = prop.GetCustomAttribute(typeof(IndexerAttribute), true) as IndexerAttribute; var store = attr.Store ? Field.Store.YES : Field.Store.NO; var index = attr.Index ? Field.Index.ANALYZED : Field.Index.NOT_ANALYZED; document.Add(new Field(prop.Name, value, store, index)); } } _indexWriter.AddDocument(document); } public void AddRange<T>(IEnumerable<T> objs) { SetDBPath(typeof(T)); Open(); foreach (var obj in objs) { Document document = new Document(); foreach (var prop in GetProps(typeof(T))) { var value = prop.GetValue(obj)?.ToString(); if (null != value) { var attr = prop.GetCustomAttribute<IndexerAttribute>(); var store = attr.Store ? Field.Store.YES : Field.Store.NO; var index = attr.Index ? Field.Index.ANALYZED : Field.Index.NOT_ANALYZED; document.Add(new Field(prop.Name, value, store, index)); } } _indexWriter.AddDocument(document); } } public override void Dispose() { _indexWriter.Optimize(); _indexWriter.Dispose(); base.Dispose(); } }
这个类用于创建索引,会读取用在对象上的Indexer标签
LuceneDBSearcher
public class LuceneDBSearcher: LuceneDB { private Type _searchType; public LuceneDBSearcher(string path) : base(path) { } public LuceneDBSearcher(Type type) { SetDBPath(type); } public LuceneDBSearcher() { } public Type SearchType { set { //判断该类型是否实现 某 约定 _searchType = value; } get { return _searchType; } } public IEnumerable<T> Search<T>(string searchText, IEnumerable<string> fields, int page, int pageSize, Dictionary<string,string> condition= null) where T : new() { return GetModels<T>(SearchText(searchText, fields, page, pageSize, condition)); } private IEnumerable<Document> SearchText(string searchText,IEnumerable<string> fields,int page,int pageSize, Dictionary<string,string> condition) { StringBuilder conditionWhere = new StringBuilder(); foreach (var item in condition) { conditionWhere.Append(" +" + item.Key + ":" + item.Value); } Open(); var parser = new Lucene.Net.QueryParsers.MultiFieldQueryParser(Lucene.Net.Util.Version.LUCENE_30, fields.ToArray(), _analyzer); var search = new Lucene.Net.Search.IndexSearcher(_luDirectory, true); var query = parser.Parse("+" + searchText + conditionWhere.ToString()); var searchDocs = search.Search(query, 100).ScoreDocs; return searchDocs.Select(t => search.Doc(t.Doc)); } protected override void Open() { _luDirectory = Lucene.Net.Store.FSDirectory.Open(new System.IO.DirectoryInfo(DBPath)); if (Lucene.Net.Index.IndexWriter.IsLocked(_luDirectory)) { Lucene.Net.Index.IndexWriter.Unlock(_luDirectory); } var lockFilePath = System.IO.Path.Combine(DBPath, "write.lock"); if (System.IO.File.Exists(lockFilePath)) { System.IO.File.Delete(lockFilePath); } _analyzer = new Lucene.Net.Analysis.Standard.StandardAnalyzer(Lucene.Net.Util.Version.LUCENE_30); } private IEnumerable<T> GetModels<T>(IEnumerable<Document> documents) where T:new() { var type = typeof(T); var props = type.GetProperties().Where(prop => null != prop.GetCustomAttribute(typeof(IndexerAttribute), true)); var objs = new List<T>(); foreach (var document in documents) { var obj = new T(); foreach (var prop in props) { var attr = prop.GetCustomAttribute<IndexerAttribute>(); if (null != attr && attr.Store) { object v = Convert.ChangeType(document.Get(prop.Name), prop.PropertyType); prop.SetValue(obj, v); } } objs.Add(obj); } return objs; } private T GetModel<T>(Document document) where T : new() { var type = typeof(T); var props = type.GetProperties().Where(prop => null != prop.GetCustomAttribute(typeof(IndexerAttribute), true)); var obj = new T(); foreach (var prop in props) { var attr = prop.GetCustomAttribute<IndexerAttribute>(); if (null != attr && attr.Store) { object v = Convert.ChangeType(document.Get(prop.Name), prop.PropertyType); prop.SetValue(obj, v); } } return obj; } public override void Dispose() { _analyzer.Dispose(); base.Dispose(); } }
用于检索Lucene文件夹并将数据转为对象
LuceneEntityBase
public abstract class LuceneEntityBase:ILuceneStored { #region private private Dictionary<string, PropertyInfo> _propertiesCache; #endregion #region IndexerFields #region ILuceneStored [Indexer(false, true)] public string ID { get; set; } [Indexer(true, false)] public string _Customer { get; set; } [Indexer(true, false)] public string _Category { get; set; } #endregion /// <summary> /// 图片 /// </summary> [Indexer(false, true)] public string Picture { get; set; } /// <summary> /// 标题 /// </summary> [Indexer(true, true)] public string Title { get; set; } /// <summary> /// 简介 /// </summary> [Indexer(true, true)] public string Synopsis { get; set; } /// <summary> /// 链接 /// </summary> [Indexer(false, true)] public string Url { get; set; } #endregion public LuceneEntityBase() { } protected IEnumerable<T> Search<T>(string searchText, int page, int pageSize, object condition = null) where T:new () { var ConditionDictionary = null != condition ? InitConditionSearchFields(condition) : new Dictionary<string, string>(); var fullTextSearchFields = from propName in PropertiesCache.Select(t => t.Key) where !ConditionDictionary.ContainsKey(propName) select propName; using (var luceneDB = new LuceneDBSearcher(GetType())) { return luceneDB.Search<T>(searchText, fullTextSearchFields, page, pageSize, ConditionDictionary); } } /// <summary> /// 属性缓存 /// </summary> protected Dictionary<string, PropertyInfo> PropertiesCache { get { if(null == _propertiesCache) { _propertiesCache = new Dictionary<string, PropertyInfo>(); foreach (var prop in GetType().GetProperties()) { var attr = prop.GetCustomAttribute<IndexerAttribute>(true); if (null != attr && attr.Index) { _propertiesCache.Add(prop.Name, prop); } } } return _propertiesCache; } } /// <summary> /// 初始化 且 条件 /// </summary> protected virtual Dictionary<string, string> InitConditionSearchFields(object andCondition) { var _conditionDictionary = new Dictionary<string, string>(); var type = GetType(); var andConditionType = andCondition.GetType(); var conditions = type.GetInterfaces().Where(t => typeof(ICondition).IsAssignableFrom(t) && t!= typeof(ICondition)) .SelectMany(t => t.GetProperties() /*t.GetInterfaceMap(t).InterfaceMethods*/) .Select(t => t.Name); foreach (var condition in conditions) { if (!_conditionDictionary.ContainsKey(condition)) { _conditionDictionary.Add(condition, andConditionType.GetProperty(condition).GetValue(andCondition)?.ToString() ?? string.Empty); } } return _conditionDictionary; } }
需要索引的抽象基类
一般而言搜索结果有一个标题,介绍,图片等等,介绍和标题是数据库(这里是db)中实际存储的,然而对于搜索的关键字确实没有的,比如(在博客园中)有一个博客表,表里面存博客标题,博客主要内容,还有一个问道表,用户提的问题,介绍,等等,此时如果用户来到博客园中,键入博客(可能已进入首页都是博客,但是用户还是键入了博客),然而db中却不知道那个是博客??仔细想是不是这样子的,这里_Customer就是设定这些数据的,当然也可以是_Category。
结下来介绍一个比较重要的接口。
ICondition
public interface ICondition { }
作为一个空接口,如果不能找到一个它不应该存在的理由,那它就真的不应该存在了。在上面说的LuceneEntityBase中,所有的字段都是全文搜索的,即任何一个字段数据匹配用户键入的值都可能称谓匹配的文档,这是假如需要匹配另一个条件该如何?写代码之初只考虑到一个语言条件,再添加一个参数,具体改一下搜索的方法就可以了,这样一样知识需要改三处,搜索入口(控制器),给该模型添加一个语言字段,具体的搜索方法也要改一下,甚至写索引的方法也都要改。然而有了这个接口,我们只需要实现一个ILanguage继承该接口,然后事具体的模型也继承ILanguage就行。
public interface ILanguage: ICondition { string Language { get; set; } }
在看一下上面LuceneEntityBase中创建且条件的方法,会解析出ICondition中的属性并设置为必须条件
var _conditionDictionary = new Dictionary<string, string>(); var type = GetType(); var andConditionType = andCondition.GetType(); var conditions = type.GetInterfaces().Where(t => typeof(ICondition).IsAssignableFrom(t) && t!= typeof(ICondition)) .SelectMany(t => t.GetProperties() /*t.GetInterfaceMap(t).InterfaceMethods*/) .Select(t => t.Name); foreach (var condition in conditions) { if (!_conditionDictionary.ContainsKey(condition)) { _conditionDictionary.Add(condition, andConditionType.GetProperty(condition).GetValue(andCondition)?.ToString() ?? string.Empty); } }
实例之三国人物
用上面封装后的类建立了一个简易的搜索示例
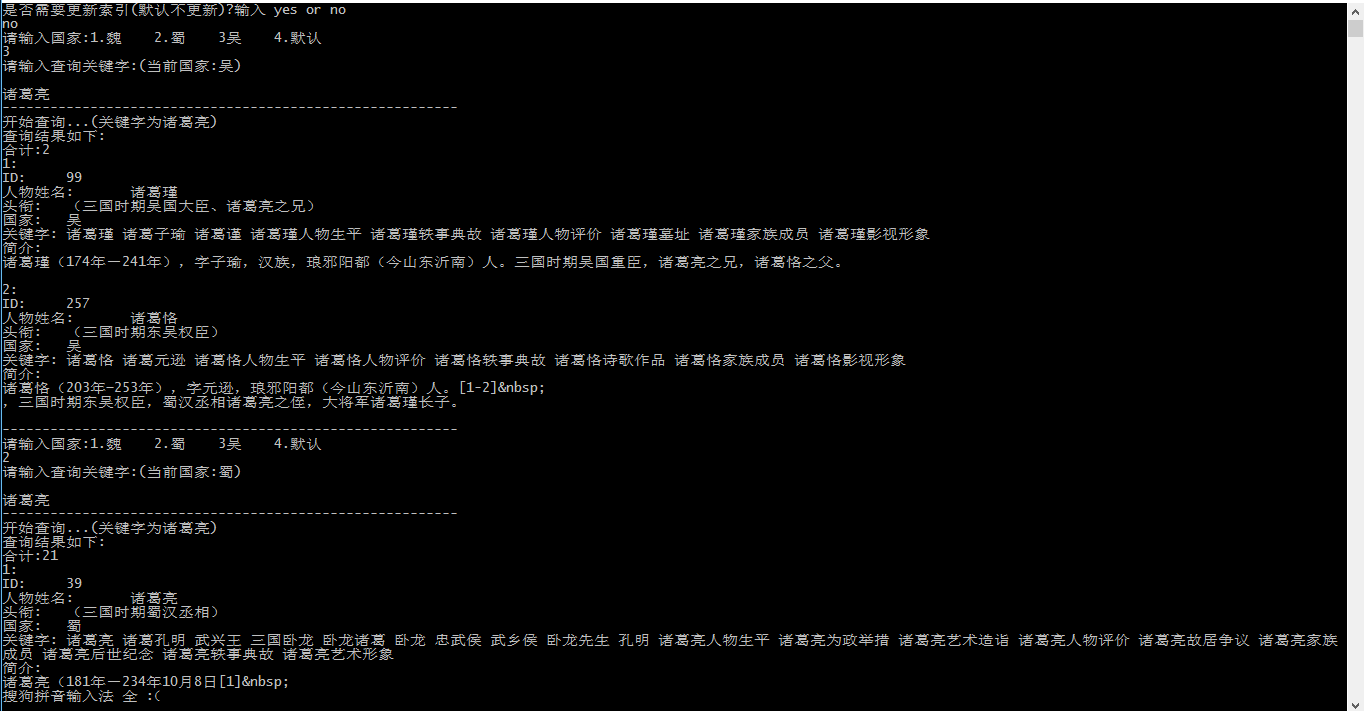
核心代码只有以下三部分,数据的话都爬虫字自百度百科
public class Figure : Lyrewing.Search.LuceneEntityBase, ICountry { [Indexer(true,true)] public string Country { get; set; } [Indexer(true,true)] public string FigureName { get; set; } /// <summary> /// 称谓 /// </summary> [Indexer(true,true)] public string Appellation { get; set; } /// <summary> /// 关键字 /// </summary> [Indexer(true,true)] public string KeyWords { get; set; } public IEnumerable<Figure> Search(string searchText, int page, int pageSize, object condition = null) { return Search<Figure>(searchText, page, pageSize, condition); } } public interface ICountry : ICondition { string Country { get; set; } }
using (var luceneDB = new LuceneDBIndexer()) { luceneDB.AddRange(Figures); }
var seacher = new Figure(); var result = seacher.Search(key, 1, 100, country != Country.默认 ? new { Country = country.ToString() } : null);
小结:
通过这次从lucene的踩坑,到lucene的重构,以及代码的一些思考,发现过程是艰辛的,代码现在也不是完美的,lucene的一些其他复杂的查询也没有加进去,但是从这个过程来说对自己来说是值得的,依稀记得实习的时候以为老师讲过的一句话,貌似高三语文老师也讲过哈,信达雅,但是这个过程是不易的,还需要更多的学习和挑战!
- Lucene的使用与重构
- Lucene的使用与重构
- Lucene的使用与优化
- Lucene的配置与使用
- Eclipse 重构功能的使用与重构快捷键
- Lucene的使用与优化1
- 全文检索技术与Lucene的使用
- lucene入门与使用
- Lucene入门与使用
- Lucene入门与使用
- lucene使用与优化
- lucene使用与优化
- Lucene入门与使用
- lucene使用与优化
- lucene使用与优化
- Lucene使用与优化
- lucene使用与优化
- Lucene入门与使用
- Excel在统计分析中的应用—第五章—统计指数-Part7-平均指数(算术平均指数)
- loadrunner 11 的下载和安装
- 导致JS内存泄漏的几种情况
- linux时间总是跳变
- Java基础知识精华部分.
- Lucene的使用与重构
- Hadoop安装教程
- JVM Knowleadge-垃圾回收GC Roots Tracing
- git使用
- 字符串----句子中单词的翻转
- FTPrep, 27 Remove Element
- 推荐:Java集合详细介绍
- Android光线传感器
- 使用css样式 解决input 设置disabled="true"属性后变为灰色问题


