大数据概述
来源:互联网 发布:监控录像分析软件 编辑:程序博客网 时间:2024/06/06 22:27
大数据概述
一、大数据的概念
大数据指的是传统数据处理应用软件不足以处理他们的大或复杂的数据集的术语。
二、大数据的特点(4v)
- Volume:数据量巨大
- Variety:数据种类多
- Velocity:数据速度快
- Value:价值密度低
三、大数据的数据类型
- 结构化数据
- 非结构化数据
相对于结构化数据(即行数据,存储在数据库里,可以用二维表结构来表达实现的数据)而言,不方便用数据库二位逻辑来表现的数据称为非结构化的数据,包括所有格式的办公文档、文本、图片、XML、HTML、各类报表、图像和音频、视频信息等
五、大数据的常用数据单位转换
1GB = 1024KB ,读作“吉字节”
1TB = 1024GB ,读作“太字节”
1PB = 1024TB ,读作“拍字节”
1EB = 1024PB , 读作“艾字节”
1ZB = 1024EB , 读作“Z字节”
1YB = 1024ZB , 读作“Y字节”
六、大数据技术的流程和关机系统介绍
技术流程

(1) 数据收集及准备:搞大数据,首先要具备足够的数据量,典型的数据源有服务器的日志数据,用户访问Web站点的浏览行为数据,各大银行中用户的消费数据等。
(2)数据的存储:数据收集到之后我们要想办法把它存储下来以供接下来的处理和分析。
(3)资源的管理:在大数据处理系统中,传统的单机已经不能满足要求,需要分布式集群来协同工作,多台机器在一起工作需要有一个资源管理系统对集群资源进行调度。
(4)计算框架:海量数据存储在集群中,数据存储在那里不深入挖掘是没有经济价值的,我们需要一些计算框架对存储的数据做基本的预处理,典型的计算框架有批处理的计算框架,交互式分析的计算框架,流式处理的计算框架等
(5)数据分析:在前面的基础上,我们可以开展一些深层次的分析,挖掘海量数据中存在的经济价值,比如分析服务器日志数据可以帮助我们制定更加科学的负载均衡策略,分析用户Web站点的浏览行为做一些推荐营销等。数据分析系统常见的有OLAP(联机分析处理),OLTP(联机事务处理)等。
(6)数据的展示:在数据处理和分析后,我们需要将结果以直观的方式展现出来,比如生成报表等。
大数据的关键系统介绍

(1)数据收集及准备:在收据收集中,典型的收集系统有Flume(用于收集日志数据),Sqoop(将关系型数据库中的数据迁移到数据存储系统中)等。
(2)数据的存储:在大数据存储中最经典的就是HDFS(分布式文件系统),基于Google的GFS。
(3)资源管理:YARN主要负责资源管理和调度,它是Hadoop2.0中新增的系统。Zookeeper主要解决分布式环境下数据管理问题,用于主备自动切换。
(4)计算框架:常见的计算框架有Mapreduce(适用于离线处理),Hive也是用于离线处理,它定义了一种类似SQL查询语言,可以将SQL翻译Mapreudce执行,省去了编写大量程序;交互式的查询引擎Presto,它是基于内存的、支持任意数据源、与Hive兼容;流式处理计算框架Storm,Spark Streaming。
(5)数据分析:在前面的基础上有一些数据分析的机器学习类库,如Mahout,Spark的MLlib等。
(6)数据的展示:目前流行的可视化工具有D3.js、Echart,Tabluea等。
作者:中野浩一
链接:http://www.jianshu.com/p/1df340db1f98
七、大数据的计算模式和系统
所谓大数据计算模式,是指根据大数据的不同数据特征和计算特征,从多样性的大数据问题和需求中提炼并建立的各种高层抽象和模型。传统的并行计算方法主要从体系结构和编程语言的层面定义了一些较为底层的抽象和模型,但由于大数据处理问题具有很多高层的数据特征和计算特征,因此大数据处理需要结合其数据特征和计算特性考虑更为高层的计算模式
1. 查询分析计算模式与典型系统
由于行业数据规模的增长已大大超过了传统的关系数据库的承载和处理能力,因此,目前需要尽快研究并提供面向大数据存储管理和查询分析的新的技术方法和系统,尤其要解决在数据体量极大时如何能够提供实时或准实时的数据查询分析能力,满足企业日常的管理需求。然而,大数据的查询分析处理具有很大的技术挑战,在数量规模较大时,即使采用分布式数据存储管理和并行化计算方法,仍然难以达到关系数据库处理中小规模数据时那样的秒级响应性能。
大数据查询分析计算的典型系统包括Hadoop 下的HBase 和Hive、Facebook 公司开发的Cassandra、Google 公司的Dremel、Cloudera 公司的实时查询引擎Impala ;此外为了实现更高性能的数据查询分析,还出现了不少基于内存的分布式数据存储管理和查询系统,如Apache Spark 下的数据仓库Shark、SAP 公司的Hana、开源的Redis 等。
2. 批处理计算模式与典型系统
最适合于完成大数据批处理的计算模式是MapReduce,这是MapReduce 设计之初的主要任务和目标。MapReduce 是一个单输入、两阶段(Map 和Reduce)的数据处理过程。首先,MapReduce 对具有简单数据关系、易于划分的大规模数据采用“分而治之”的并行处理思想;然后将大量重复的数据记录处理过程总结成Map 和Reduce 两个抽象的操作;最后MapReduce 提供了一个统一的并行计算框架,把并行计算所涉及到的诸多系统层细节都交给计算框架去完成,以此大大简化了程序员进行并行化程序设计的负担。
MapReduce 的简单易用性使其成为目前大数据处理最成功的主流并行计算模式。在开源社区的努力下,开源的Hadoop 系统目前已成为较为成熟的大数据处理平台,并已发展成一个包括众多数据处理工具和环境的完整的生态系统。目前几乎国内外的各个著名IT 企业都在使用Hadoop 平台进行企业内大数据的计算处理。此外,Spark 系统也具备批处理计算的能力。
3. 流式计算模式与典型系统
流式计算是一种高实时性的计算模式,需要对一定时间窗口内应用系统产生的新数据完成实时的计算处理,避免造成数据堆积和丢失。很多行业的大数据应用,如电信、电力、道路监控等行业应用以及互联网行业的访问日志处理,都同时具有高流量的流式数据和大量积累的历史数据,因而在提供批处理计算模式的同时,系统还需要能具备高实时性的流式计算能力。流式计算的一个特点是数据运动、运算不动,不同的运算节点常常绑定在不同的服务器上。
Facebook 的Scribe 和Apache 的Flume 都提供了一定的机制来构建日志数据处理流图。而更为通用的流式计算系统是Twitter 公司的Storm、Yahoo 公司的S4 以及Apache SparkSteaming。
4. 迭代计算模式与典型系统
为了克服Hadoop MapReduce 难以支持迭代计算的缺陷,工业界和学术界对HadoopMapReduce 进行了不少改进研究。HaLoop 把迭代控制放到MapReduce 作业执行的框架内部,并通过循环敏感的调度器保证前次迭代的Reduce 输出和本次迭代的Map 输入数据在同一台物理机上,以减少迭代间的数据传输开销;iMapReduce 在这个基础上保持Map 和Reduce任务的持久性,规避启动和调度开销;而Twister 在前两者的基础上进一步引入了可缓存的Map 和Reduce 对象,利用内存计算和pub/sub 网络进行跨节点数据传输。
目前,一个具有快速和灵活的迭代计算能力的典型系统是Spark,其采用了基于内存的RDD 数据集模型实现快速的迭代计算。
5. 图计算模式与典型系统
社交网络、Web 链接关系图等都包含大量具有复杂关系的图数据,这些图数据规模很大,常常达到数十亿的顶点和上万亿的边数。这样大的数据规模和非常复杂的数据关系,给图数据的存储管理和计算分析带来了很大的技术难题。用MapReduce 计算模式处理这种具有复杂数据关系的图数据通常不能适应,为此,需要引入图计算模式。
大规模图数据处理首先要解决数据的存储管理问题,通常大规模图数据也需要使用分布式存储方式。但是,由于图数据具有很强的数据关系,分布式存储就带来了一个重要的图划分问题(Graph Partitioning)。根据图数据问题本身的特点,图划分可以使用“边切分”和“顶点切分”两种方式。在有效的图划分策略下,大规模图数据得以分布存储在不同节点上,并在每个节点上对本地子图进行并行化处理。与任务并行和数据并行的概念类似,由于图数据并行处理的特殊性,人们提出了一个新的“图并行”(Graph Parallel)的概念。事实上,图并行是数据并行的一个特殊形式,需要针对图数据处理的特征考虑一些特殊的数据组织模型和计算方法。
目前已经出现了很多分布式图计算系统,其中较为典型的系统包括Google 公司的Pregel、Facebook 对Pregel 的开源实现Giraph、微软公司的Trinity、Spark 下的GraphX,以及CMU的GraphLab 以及由其衍生出来的目前性能最快的图数据处理系统PowerGraph。
6. 内存计算模式与典型系统
Hadoop MapReduce 为大数据处理提供了一个很好的平台。然而,由于MapReduce 设计之初是为大数据线下批处理而设计的,随着数据规模的不断扩大,对于很多需要高响应性能的大数据查询分析计算问题,现有的以Hadoop 为代表的大数据处理平台在计算性能上往往难以满足要求。随着内存价格的不断下降以及服务器可配置的内存容量的不断提高,用内存计算完成高速的大数据处理已经成为大数据计算的一个重要发展趋势。例如,Hana 系统设计者总结了很多实际的商业应用后发现,一个提供50TB 总内存容量的计算集群将能够满足绝大多数现有的商业系统对大数据的查询分析处理要求,如果一个服务器节点可配置1TB ~ 2TB 的内存,则需要25 ~ 50 个服务器节点。目前Intel Xeon E-7 系列处理器最大可支持高达1.5TB 的内存,因此,配置一个上述大小规模的内存计算集群是可以做到的。
八、分布式系统的CAP理论
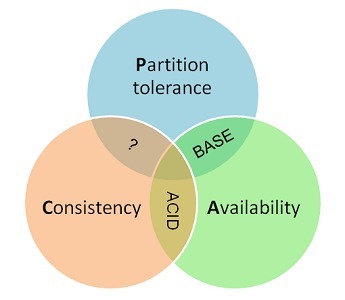
CAP概述:
一个分布式系统最多只能同时满足一致性、可用性和分区容错性这三项中的两项
一致性即更新操作成功并返回客户端完成后,所有节点在同一之间的数据完全一致
CAP定义:
Consistency 一致性
一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。分布式的一致性
对于一致性,可以分为从客户端和服务端两个不同的视角。从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。
从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。如果能容忍后续的部分或者全部访问不到,则是弱一致性。如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。
Availability 可用性
可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。
对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。也就是,该系统使用的任何算法必须最终终止。当同时要求分区容忍性时,这是一个很强的定义:即使是严重的网络错误,每个请求必须终止。
好的可用性主要是指系统能够很好的为用户服务,不出现用户操作失败或者访问超时等用户体验不好的情况。可用性通常情况下可用性和分布式数据冗余,负载均衡等有着很大的关联。
Partition Tolerance分区容错性
分区容错性指“the system continues to operate despite arbitrary message loss or failure of part of the system”,即分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
分区容错性和扩展性紧密相关。在分布式应用中,可能因为一些分布式的原因导致系统无法正常运转。好的分区容错性要求能够使应用虽然是一个分布式系统,而看上去却好像是在一个可以运转正常的整体。比如现在的分布式系统中有某一个或者几个机器宕掉了,其他剩下的机器还能够正常运转满足系统需求,或者是机器之间有网络异常,将分布式系统分隔未独立的几个部分,各个部分还能维持分布式系统的运作,这样就具有好的分区容错性。
九、分布式系统
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统
简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
十、Hadoop技术栈
- 大数据算法概述
- 大数据概述
- 大数据算法概述
- 大数据概述1
- 大数据概述
- 大数据概述
- 大数据概述
- 大数据概述1
- 大数据概述
- 大数据-spark概述
- 大数据的概述
- hadoop大数据概述
- 大数据概述
- Hadoop大数据系列---概述
- 大数据_各章概述
- 大数据相关组件概述
- Oracle大数据概述:大数据技术精选
- 大数据算法—大数据算法概述
- 盒子模型
- 居中
- Linux--系统网络测试和测试工具
- 【普及模拟】城市连接
- 多核初始化过程
- 大数据概述
- 单词查找树
- 【普及模拟】生产武器
- 【NLP】play with stanford nlp
- Phone List
- 【NOIP2009PJ】道路游戏
- [Usaco2017 Open]Bovine Genomics //Trie
- 选举
- 异或之


