图的储存结构
来源:互联网 发布:美国宝宝的好处知乎 编辑:程序博客网 时间:2024/05/17 23:48
要将图的信息存到计算机中,需要使用专门设计的数据结构,比较常见的是邻接矩阵,向前星,邻接表,链式向前星这四种方式。另外还有十字链表的方式,由于其建立比较复杂,故在ACM/ICPC竞赛中很少用到,这里不再赘述。下文只需要考虑输入的信息为有向边的信息,如果输入为无向边请读者自行拆成两条有向边处理
一 邻接矩阵
逻辑结构分为两部分:V和E集合。因此,用一个一维数组存放图中所有顶点数据;用一个二维数组存放顶点间关系(边或弧)的数据,这个二维数组
称为邻接矩阵。邻接矩阵又分为有向图邻接矩阵和无向图邻接矩阵。(下面三张图片转自点击打开链接)
1.无向图。

2.有向图

3.有向网图

优点:实现简单直观。
可以直接查询点Vi与Vj间是否有边,如果有,边的权值是多少。
缺点:遍历效率低,并且不能储存重边。
大图的空间开销大,特别当n比较大的时候,建一个n*n的数组是不现实的。
对于稀疏图邻接矩阵的空间利用效率也不高
二 向前星
向前星是一种通过储存边信息的方式储存图的数据结构。它的构造方式非常简单,读入每条边的信息,将边存放在数组中,把数组中的边按照起点顺序排序,向前星就构造完了,为了查询方便,经常会有一个数组储存七点为Vi的第一条边的位置。
数据结构如下
int head[maxsize]; //储存起点为Vi的第一条边的位置struct node{ int from; //起点 int to; //终点 int w; //权值}edge[maxsize];比较函数
bool cmp(node x,node y){ if(x.from!=y.from) return x.from<y.from; if(x.to!=y.to) return x.to<y.to; return x.w<y.w;}读入数据
cin>>n>>m for(int i=1;i<=m;i++) cin>>edge[i].from>>edge[i].to>>edge[i].w; sort(edge+1,edge+1+m,cmp); //排序 memset(head,-1,sizeof(head)); head[edge[0].from]=0; for(int i=2;i<=m;i++) { if(edge[i].from!=edge[i-1].from) head[edge[i].from]=i; //确实起点为Vi的第一条边的位置 }遍历代码
for(int i=1;i<=n;i++) { for(int j=head[i];edge[j].from==i&&j<=m;j++) { cout<<edge[j].from<<" "<<edge[j].to<<" "<<edge[j].w<<endl; } }完整代码
#include<iostream>#include<algorithm>#include<string.h>const int maxsize=1000;using namespace std;int n,m;int head[maxsize];struct node{ int from; int to; int w;}edge[maxsize];bool cmp(node x,node y){ if(x.from!=y.from) return x.from<y.from; if(x.to!=y.to) return x.to<y.to; return x.w<y.w;}int main(){ while(cin>>n>>m) { for(int i=1;i<=m;i++) cin>>edge[i].from>>edge[i].to>>edge[i].w; sort(edge+1,edge+1+m,cmp); memset(head,-1,sizeof(head)); head[edge[1].from]=1; for(int i=2;i<=m;i++) { if(edge[i].from!=edge[i-1].from) head[edge[i].from]=i; } for(int i=1;i<=n;i++) { for(int j=head[i];edge[j].from==i&&j<=m;j++) { cout<<edge[j].from<<" "<<edge[j].to<<" "<<edge[j].w<<endl; } } } return 0;}测试数据8 121 2 48 7 71 6 96 1 123 1 224 3 175 8 296 5 97 4 256 7 48 3 113 2 19输出1 2 41 6 93 1 223 2 194 3 175 8 296 1 126 5 96 7 47 4 258 3 118 7 7head数组的值1 -1 3 5 6 7 10 11
优点:可以对应点非常多的情况,可以储存重边。
缺点 :但是不能直接判断任意两个顶点之间是否具有边,而且排序需要浪费一些时间
三 邻接表
邻接表的是图的一种链式储存结构。对于图G中每个顶点Vi,把所有邻接于Vi的顶点Vj链成一个单链表,这个单链表称为顶点Vi的邻接表。
邻接表有三种实现方法,分别为动态建表实现,使用STL中的vector模拟链表实现和静态建表实现。
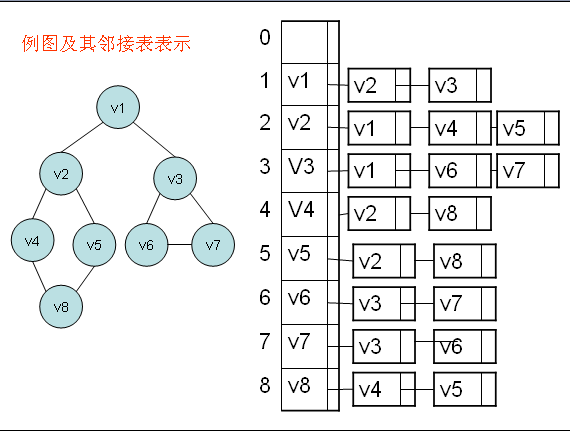
1动态建表
动态建表的数据结构:
struct EdgeNode //邻接表节点{ int to; //终点 int w; //权值 EdgeNode *next; //指向下一条边的指针};struct VNode //起点表节点{ int from; //起点 EdgeNode *first; //邻接表头指针}; VNode Adjlist[maxsize]; //整个图的邻接表信息储存的主要代码
cin>>i>>j>>w;EdgeNode *p=new EdgeNode();p->to=j;p->w=w;p->next=Adjlist[i].first;Adjlist[i].first=p;//将新节点指向起点表节点,并且将起点表节点更新为该新节点
遍历代码
’
for(int i=1;i<=n;i++){ for(EdgeNode *k=Adjlist[i].first;k!=NULL;k=k->next) { cout<<i<<" "<<k->to>>" "<<k->w<<endl; }}2 STL 中的vector模拟链表实现
所需的数据结构
struct node //表边节点的类型{ int to; //节点序号 int w; //权值};vector<node> map[maxsize]; 信息储存的主要代码
node e;cin>>i>>j>>w;e.to=j;e.w=w;map[i].push_back(e);
遍历代码
for(int i=1;i<=n;i++){ for(vector<node>::iterator k=map[i].begin();k!=map[i].end();k++) { node t=*p; cout<<i<<" "<<t.to<<" "<<t.w<<endl; /*或者写成 cout<<i<<" "<<k->to<<" "<<k->w<<endl;*/ }}3静态建表
静态建表也就是采用数组模拟链表的方式实现邻接表的功能。
我以前的博客有将过,附上链接点击打开链接,在此不再赘述。
优点:效率高,所在空间小
缺点 : 不能迅速找到任意两点的关系
- 图的储存结构
- 图的储存结构之邻接矩阵
- 图的储存结构之邻接表
- 图的几种储存结构
- 图及其储存结构
- 月球美容计划之图的储存结构汇总
- 图的储存结构(*链式前向星)
- 关于顺序储存结构的构思内容
- 数据结构 线性表的顺序储存结构
- 结构体变量的储存原理
- 堆分配储存结构的串
- 堆栈的两种储存结构
- 图的储存
- 图的储存 模板
- 图的储存方式
- 图的储存
- 图论专项菜鸡入门(一):图的储存结构
- 栈--顺序储存结构
- 设置Tablayout的tab宽度
- Hadoop的坑——无法启动namenode
- wchar_t*转LPCTSTR的方法
- 进程间通信-Windows
- @hexo-next 搭建个人博客系列教程
- 图的储存结构
- 文章标题
- PHP 字符串函数
- Android开发 手机测试运行报错2
- org.hibernate.PropertyAccessException: Null value was assigned to a property of primitive type sette
- linux中,shell脚本更改当前路径
- Android Studio 使用时你应该知道的一切配置
- linux的一个错误 FAT: utf8 is not a recommended IO AND kernel panic
- supergeek的技术博客大纲


