决策树原理
来源:互联网 发布:2013nba东部决赛数据 编辑:程序博客网 时间:2024/06/05 22:54
转载自:http://www.cnblogs.com/bourneli/archive/2013/03/15/2961568.html
算法原理
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析;2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
如何预测
先看看下面的数据表格:
ID
拥有房产(是/否)
婚姻情况(单身,已婚,离婚)
年收入(单位:千元)
无法偿还债务(是/否)
1
是
单身
125
否
2
否
已婚
100
否
3
否
单身
70
否
4
是
已婚
120
否
5
否
离婚
95
是
6
否
已婚
60
否
7
是
离婚
220
否
8
否
单身
85
是
9
否
已婚
75
否
10
否
单身
90
是
上表根据历史数据,记录已有的用户是否可以偿还债务,以及相关的信息。通过该数据,构建的决策树如下:

比如新来一个用户:无房产,单身,年收入55K,那么根据上面的决策树,可以预测他无法偿还债务(蓝色虚线路径)。从上面的决策树,还可以知道是否拥有房产可以很大的决定用户是否可以偿还债务,对借贷业务具有指导意义。
基本步骤
决策树构建的基本步骤如下:
1. 开始,所有记录看作一个节点
2. 遍历每个变量的每一种分割方式,找到最好的分割点
3. 分割成两个节点N1和N2
4. 对N1和N2分别继续执行2-3步,直到每个节点足够“纯”为止
决策树的变量可以有两种:
1) 数字型(Numeric):变量类型是整数或浮点数,如前面例子中的“年收入”。用“>=”,“>”,“<”或“<=”作为分割条件(排序后,利用已有的分割情况,可以优化分割算法的时间复杂度)。
2) 名称型(Nominal):类似编程语言中的枚举类型,变量只能重有限的选项中选取,比如前面例子中的“婚姻情况”,只能是“单身”,“已婚”或“离婚”。使用“=”来分割。
如何评估分割点的好坏?如果一个分割点可以将当前的所有节点分为两类,使得每一类都很“纯”,也就是同一类的记录较多,那么就是一个好分割点。比如上面的例子,“拥有房产”,可以将记录分成了两类,“是”的节点全部都可以偿还债务,非常“纯”;“否”的节点,可以偿还贷款和无法偿还贷款的人都有,不是很“纯”,但是两个节点加起来的纯度之和与原始节点的纯度之差最大,所以按照这种方法分割。构建决策树采用贪心算法,只考虑当前纯度差最大的情况作为分割点。
量化纯度
前面讲到,决策树是根据“纯度”来构建的,如何量化纯度呢?这里介绍三种纯度计算方法。如果记录被分为n类,每一类的比例P(i)=第i类的数目/总数目。还是拿上面的例子,10个数据中可以偿还债务的记录比例为P(1) = 7/10 = 0.7,无法偿还的为P(2) = 3/10 = 0.3,N = 2。
Gini不纯度

熵(Entropy)
![]()
错误率
![]()
上面的三个公式均是值越大,表示越 “不纯”,越小表示越“纯”。三种公式只需要取一种即可,实践证明三种公司的选择对最终分类准确率的影响并不大,一般使用熵公式。
纯度差,也称为信息增益(Information Gain),公式如下:

其中,I代表不纯度(也就是上面三个公式的任意一种),K代表分割的节点数,一般K = 2。vj表示子节点中的记录数目。上面公式实际上就是当前节点的不纯度减去子节点不纯度的加权平均数,权重由子节点记录数与当前节点记录数的比例决定。
停止条件
决策树的构建过程是一个递归的过程,所以需要确定停止条件,否则过程将不会结束。一种最直观的方式是当每个子节点只有一种类型的记录时停止,但是这样往往会使得树的节点过多,导致过拟合问题(Overfitting)。另一种可行的方法是当前节点中的记录数低于一个最小的阀值,那么就停止分割,将max(P(i))对应的分类作为当前叶节点的分类。
过渡拟合
采用上面算法生成的决策树在事件中往往会导致过滤拟合。也就是该决策树对训练数据可以得到很低的错误率,但是运用到测试数据上却得到非常高的错误率。过渡拟合的原因有以下几点:
- 噪音数据:训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
- 缺少代表性数据:训练数据没有包含所有具有代表性的数据,导致某一类数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出。
- 多重比较(Mulitple Comparition):举个列子,股票分析师预测股票涨或跌。假设分析师都是靠随机猜测,也就是他们正确的概率是0.5。每一个人预测10次,那么预测正确的次数在8次或8次以上的概率为
 ,只有5%左右,比较低。但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为
,只有5%左右,比较低。但是如果50个分析师,每个人预测10次,选择至少一个人得到8次或以上的人作为代表,那么概率为  ,概率十分大,随着分析师人数的增加,概率无限接近1。但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
,概率十分大,随着分析师人数的增加,概率无限接近1。但是,选出来的分析师其实是打酱油的,他对未来的预测不能做任何保证。上面这个例子就是多重比较。这一情况和决策树选取分割点类似,需要在每个变量的每一个值中选取一个作为分割的代表,所以选出一个噪音分割标准的概率是很大的。
优化方案1:修剪枝叶
决策树过渡拟合往往是因为太过“茂盛”,也就是节点过多,所以需要裁剪(Prune Tree)枝叶。裁剪枝叶的策略对决策树正确率的影响很大。主要有两种裁剪策略。
前置裁剪 在构建决策树的过程时,提前停止。那么,会将切分节点的条件设置的很苛刻,导致决策树很短小。结果就是决策树无法达到最优。实践证明这中策略无法得到较好的结果。
后置裁剪 决策树构建好后,然后才开始裁剪。采用两种方法:1)用单一叶节点代替整个子树,叶节点的分类采用子树中最主要的分类;2)将一个字数完全替代另外一颗子树。后置裁剪有个问题就是计算效率,有些节点计算后就被裁剪了,导致有点浪费。
优化方案2:K-Fold Cross Validation
首先计算出整体的决策树T,叶节点个数记作N,设i属于[1,N]。对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率。这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
优化方案3:Random Forest
Random Forest是用训练数据随机的计算出许多决策树,形成了一个森林。然后用这个森林对未知数据进行预测,选取投票最多的分类。实践证明,此算法的错误率得到了经一步的降低。这种方法背后的原理可以用“三个臭皮匠定一个诸葛亮”这句谚语来概括。一颗树预测正确的概率可能不高,但是集体预测正确的概率却很高。
准确率估计
决策树T构建好后,需要估计预测准确率。直观说明,比如N条测试数据,X预测正确的记录数,那么可以估计acc = X/N为T的准确率。但是,这样不是很科学。因为我们是通过样本估计的准确率,很有可能存在偏差。所以,比较科学的方法是估计一个准确率的区间,这里就要用到统计学中的置信区间(Confidence Interval)。
设T的准确率p是一个客观存在的值,X的概率分布为X ~ B(N,p),即X遵循概率为p,次数为N的二项分布(Binomial Distribution),期望E(X) = N*p,方差Var(X) = N*p*(1-p)。由于当N很大时,二项分布可以近似有正太分布(Normal Distribution)计算,一般N会很大,所以X ~ N(np,n*p*(1-p))。可以算出,acc = X/N的期望E(acc) = E(X/N) = E(X)/N = p,方差Var(acc) = Var(X/N) = Var(X) / N2 = p*(1-p) / N,所以acc ~ N(p,p*(1-p)/N)。这样,就可以通过正太分布的置信区间的计算方式计算执行区间了。
正太分布的置信区间求解如下:
1) 将acc标准化,即![]()
2) 选择置信水平α= 95%,或其他值,这取决于你需要对这个区间有多自信。一般来说,α越大,区间越大。
3) 求出 α/2和1-α/2对应的标准正太分布的统计量 ![]() 和
和![]() (均为常量)。然后解下面关于p的不等式。acc可以有样本估计得出。即可以得到关于p的执行区间
(均为常量)。然后解下面关于p的不等式。acc可以有样本估计得出。即可以得到关于p的执行区间

3.3.1、ID3算法
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。下面先定义几个要用到的概念。
设D为用类别对训练元组进行的划分,则D的熵(entropy)表示为:
其中pi表示第i个类别在整个训练元组中出现的概率,可以用属于此类别元素的数量除以训练元组元素总数量作为估计。熵的实际意义表示是D中元组的类标号所需要的平均信息量。
现在我们假设将训练元组D按属性A进行划分,则A对D划分的期望信息为:
而信息增益即为两者的差值:
ID3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。下面我们继续用SNS社区中不真实账号检测的例子说明如何使用ID3算法构造决策树。为了简单起见,我们假设训练集合包含10个元素:
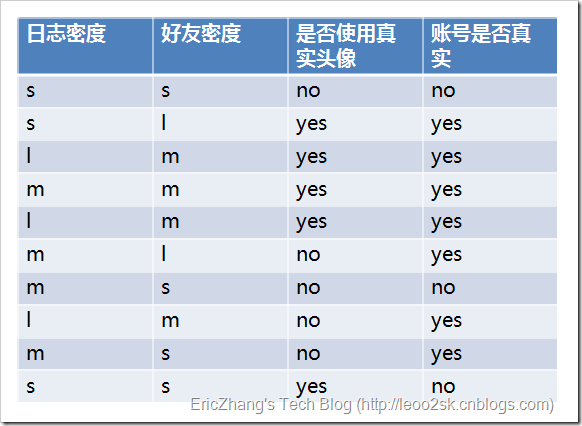
其中s、m和l分别表示小、中和大。
设L、F、H和R表示日志密度、好友密度、是否使用真实头像和账号是否真实,下面计算各属性的信息增益。
因此日志密度的信息增益是0.276。
用同样方法得到H和F的信息增益分别为0.033和0.553。
因为F具有最大的信息增益,所以第一次分裂选择F为分裂属性,分裂后的结果如下图表示:
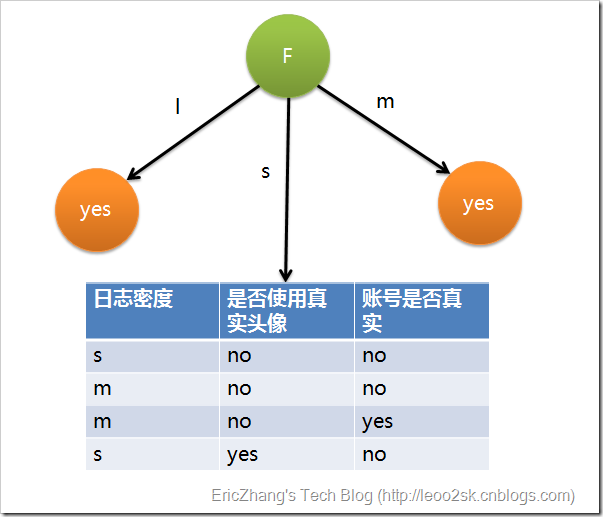
在上图的基础上,再递归使用这个方法计算子节点的分裂属性,最终就可以得到整个决策树。
上面为了简便,将特征属性离散化了,其实日志密度和好友密度都是连续的属性。对于特征属性为连续值,可以如此使用ID3算法:
先将D中元素按照特征属性排序,则每两个相邻元素的中间点可以看做潜在分裂点,从第一个潜在分裂点开始,分裂D并计算两个集合的期望信息,具有最小期望信息的点称为这个属性的最佳分裂点,其信息期望作为此属性的信息期望。
3.3.2、C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,例如,如果存在唯一标识属性ID,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。ID3的后继算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。
C4.5算法首先定义了“分裂信息”,其定义可以表示成:
其中各符号意义与ID3算法相同,然后,增益率被定义为:
C4.5选择具有最大增益率的属性作为分裂属性,其具体应用与ID3类似,不再赘述。
决策树的过拟合问题
决策树是一种分类器,通过ID3,C4.5和CART等算法可以通过训练数据构建一个决策树。但是,算法生成的决策树非常详细并且庞大,每个属性都被详细地加以考虑,决策树的树叶节点所覆盖的训练样本都是“纯”的。因此用这个决策树来对训练样本进行分类的话,你会发现对于训练样本而言,这个树表现完好,误差率极低且能够正确得对训练样本集中的样本进行分类。训练样本中的错误数据也会被决策树学习,成为决策树的部分,但是对于测试数据的表现就没有想象的那么好,或者极差,这就是所谓的过拟合(Overfitting)问题。
决策树的剪枝
决策树的剪枝有两种思路:预剪枝(Pre-Pruning)和后剪枝(Post-Pruning)
预剪枝(Pre-Pruning)
在构造决策树的同时进行剪枝。所有决策树的构建方法,都是在无法进一步降低熵的情况下才会停止创建分支的过程,为了避免过拟合,可以设定一个阈值,熵减小的数量小于这个阈值,即使还可以继续降低熵,也停止继续创建分支。但是这种方法实际中的效果并不好。
后剪枝(Post-Pruning)
决策树构造完成后进行剪枝。剪枝的过程是对拥有同样父节点的一组节点进行检查,判断如果将其合并,熵的增加量是否小于某一阈值。如果确实小,则这一组节点可以合并一个节点,其中包含了所有可能的结果。后剪枝是目前最普遍的做法。
后剪枝的剪枝过程是删除一些子树,然后用其叶子节点代替,这个叶子节点所标识的类别通过大多数原则(majority class criterion)确定。所谓大多数原则,是指剪枝过程中, 将一些子树删除而用叶节点代替,这个叶节点所标识的类别用这棵子树中大多数训练样本所属的类别来标识,所标识的类 称为majority class ,(majority class 在很多英文文献中也多次出现)。
后剪枝算法
后剪枝算法有很多种,这里简要总结如下:
Reduced-Error Pruning (REP,错误率降低剪枝)
这个思路很直接,完全的决策树不是过度拟合么,我再搞一个测试数据集来纠正它。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,那么该子树就可以替换成叶子节点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
Pessimistic Error Pruning (PEP,悲观剪枝)
PEP剪枝算法是在C4.5决策树算法中提出的, 把一颗子树(具有多个叶子节点)用一个叶子节点来替代(我研究了很多文章貌似就是用子树的根来代替)的话,比起REP剪枝法,它不需要一个单独的测试数据集。
PEP算法首先确定这个叶子的经验错误率(empirical)为(E+0.5)/N,0.5为一个调整系数。对于一颗拥有L个叶子的子树,则子树的错误数和实例数都是就应该是叶子的错误数和实例数求和的结果,则子树的错误率为e,这个e后面会用到

然后用一个叶子节点替代子树,该新叶子节点的类别为原来子树节点的最优叶子节点所决定(这句话是从一片论文看到的,但是论文没有讲什么是最优,通过参考其他文章,貌似都是把子树的根节点作为叶子,也很形象,就是剪掉所有根以下的部分),J为这个替代的叶子节点的错判个数,但是也要加上0.5,即KJ+0.5。最终是否应该替换的标准为:

出现标准差,是因为我们的子树的错误个数是一个随机变量,经过验证可以近似看成是二项分布,就可以根据二项分布的标准差公式算出标准差,就可以确定是否应该剪掉这个树枝了。子树中有N的实例,就是进行N次试验,每次实验的错误的概率为e,符合B(N,e)的二项分布,根据公式,均值为Ne,方差为Ne(1-e),标准差为方差开平方。
(二项分布的知识在文章最后)
网上找到这个案例,来自西北工业大学的一份PPT,我个人觉得PPT最后的结论有误

这个案例目的是看看T4为根的整个这颗子树是不是可以被剪掉。
树中每个节点有两个数字,左边的代表正确,右边代表错误。比如T4这个节点,说明覆盖了训练集的16条数据,其中9条分类正确,7条分类错误。
我们先来计算替换标准不等式中,关于子树的部分:
子树有3个叶子节点,分别为T7、T8、T9,因此L=3
子树中一共有16条数据(根据刚才算法说明把三个叶子相加),所以N=16
子树一共有7条错误判断,所以E=7
那么根据e的公式e=(7+0.5×3)/ 16 = 8.5 /16 = 0.53
根据二项分布的标准差公式,标准差为(16×0.53×(1-0.53))^0.5 = 2.00
子树的错误数为“所有叶子实际错误数+0.5调整值” = 7 + 0.5×3 = 8.5
把子树剪枝后,只剩下T4,T4的错误数为7+0.5=7.5
这样, 8.5-2 < 7.5, 因此不满足剪枝标准,不能用T4替换整个子树。
Cost-Complexity Pruning(CCP,代价复杂度剪枝)
CART决策树算法中用的就是CCP剪枝方法。
Minimum Error Pruning(MEP)
Critical Value Pruning(CVP)
Optimal Pruning(OPP)
Cost-Sensitive Decision Tree Pruning(CSDTP)
。
附录
二项分布 Binomial Distribution
考察由n次随机试验组成的随机现象,它满足以下条件:
- 重复进行n次随机试验;
- n次试验相互独立;
- 每次试验仅有两个可能结果;
- 每次试验成功的概率为p,失败的概率为1-p。
在上述四个条件下,设X表示n次独立重复试验中成功出现的次数,显然X是可以取0,1,…,n等n+1个值的离散随机变量,且它的概率函数为:

这个分布称为二项分布,记为b(n,p)。
- 二项分布的均值:E(X)=np
- 二项分布的方差:Var(X)=np(1-p)。
- 标准差就是方差开平方
举个例子比较好理解。扔好多次硬币就是一个典型的二项分布,符合四项条件:
- 扔硬币看正反面是随机的,我们重复进行好多次,比如扔5次
- 每次扔的结果没有前后关联,相互独立
- 每次扔要么正面,要么反面
- 每次正面(看作成功)概率1/2, 反面(看作失败)概率1-1/2 = 1/2 ,即这里p=0.5
于是这个实验就符合B(5,0.5)的二项分布。那么计算扔5次硬币,出现2次正面的概率,就可以带入公式来求:
P(X=2)= C(5,2)×(0.5)^2×(0.5)^3 = 31.25%
这个实验的的期望(均值)为np=5×0.5=2.5,意思是:每扔5次,都记录正面次数,然后扔了好多好多的“5次”,这样平均的正面次数为2.5次
这个实验的方差为np(1-p)=5×0.5×0.5=1.25,表示与均值的误差平方和,表示波动情况。
多说一句,二项分布在n很大时,趋近于正态分布
作者:程sir
链接:http://www.jianshu.com/p/794d08199e5e
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
- 决策树原理
- 决策树原理
- 决策树原理
- 决策树的原理
- 决策树的数学原理
- 决策树原理-python实现
- 决策树原理图表详解
- 决策树算法原理(上)
- 决策树剪枝算法原理
- 决策树算法原理
- 决策树ID3算法原理
- 决策树01——决策树的原理
- 决策树--从原理到实现
- 决策树--从原理到实现
- 决策树--从原理到实现
- 决策树--从原理到实现
- 决策树--从原理到实现
- 决策树--从原理到实现
- 9的余数
- poj 2559 Largest Rectangle in a Histogram
- 多线程(3)—同步代码块
- 一、软考前期问题汇集
- Text使用富文本
- 决策树原理
- [HDU
- 关于struts2或webwork form表单无法提交到后台控制层方法的问题分析
- 转的一杂谈
- 神经网络中的sigmoid函数
- 安卓- apk安装出现闪退java.lang.RuntimeException: Unable to instantiate application
- Unity 5.x UGUI 控件使用
- HyperLedger/fabric1.0.0正式版安装部署
- ActionContext.getContext()的基本用法


