推荐
来源:互联网 发布:股票技术分析 软件 编辑:程序博客网 时间:2024/04/27 22:24
[协同过滤] : 交替最小二乘法
1. 基础回顾
矩阵的奇异值分解 SVD
(特别详细的总结,参考 http://blog.csdn.net/wangzhiqing3/article/details/7446444)
- 矩阵与向量相乘的结果与特征值,特征向量有关。
- 数值小的特征值对矩阵-向量相乘的结果贡献小
1)低秩近似
2)特征降维
相似度和距离度量
(参考 http://blog.sina.com.cn/s/blog_62b83291010127bf.html)
2. ALS 交替最小二乘(alternating least squares)
在机器学习中,ALS 指使用交替最小二乘求解的一个协同推荐算法。
- 它通过观察到的所有用户给商品的打分,来推断每个用户的喜好并向用户推荐适合的商品。
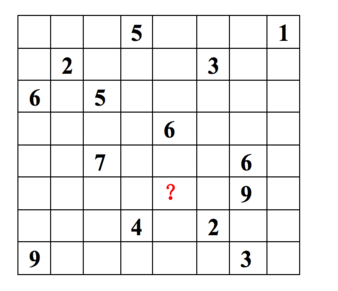
每一行代表一个用户(u1,u2,…,u8), 每一列代表一个商品(v1,v2,…,v8),用户的打分为1-9分。
这个矩阵只显示了观察到的打分,我们需要推测没有观察到的打分。
ALS的核心就是这样一个假设:打分矩阵是近似低秩的。
换句话说,就是一个m*n的打分矩阵可以由分解的两个小矩阵U(m*k)和V(k*n)的乘积来近似,即 A=UVT,k<=m,n 。这就是ALS的矩阵分解方法。
这样我们把系统的自由度从O(mn)降到了O((m+n)k)。
低维空间的选取。
这个低维空间要能够很好的区分事物,那么就需要一个明确的可量化目标,这就是重构误差。
在ALS中我们使用 F范数 来量化重构误差,就是每个元素重构误差的平方和。这里存在一个问题,我们只观察到部分打分,A中的大量未知元是我们想推断的,所以这个重构误差是包含未知数的。
解决方案很简单:只计算已知打分的重构误差。
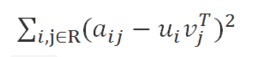
3. 协同过滤
协同过滤分析用户以及用户相关的产品的相关性,用以识别新的用户-产品相关性。
协同过滤系统需要的唯一信息是用户过去的行为信息,比如对产品的评价信息。
- 推荐系统依赖不同类型的输入数据,最方便的是高质量的显式反馈数据,它们包含用户对感兴趣商品明确的评价。例如,
Netflix收集的用户对电影评价的星星等级数据。 - 但是显式反馈数据不一定总是找得到,因此推荐系统可以从更丰富的隐式反馈信息中推测用户的偏好。 隐式反馈类型包括购买历史、浏览历史、搜索模式甚至鼠标动作。
4. 显示反馈模型
通过内积 rij = uiT vj 来预测,另外加入正则化参数 lamda 来预防 过拟合。
最小化重构误差:
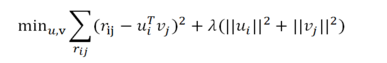
5. 隐式反馈模型
偏好:二元变量 ,它表示用户 u 对商品 v的偏好
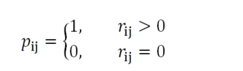
信任度:变量 ,它衡量了我们观察到的信任度
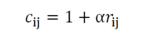
最小化损失函数:

6. 求解:最优化
1)显示和隐式的异同:
- 显示模型只基于观察到的值;隐式需要考虑不同的信任度,最优化时需要考虑所有可能的
u,v对
2) 交替最小二乘求解:
即固定 ui 求 vi+1 再固定 vi+1 求 ui+1
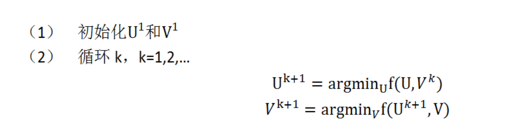
7. 例子
import org.apache.spark.mllib.recommendation._<br>//处理训练数据val data = sc.textFile("data/mllib/als/test.data")val ratings = data.map(_.split(',') match { case Array(user, item, rate) => Rating(user.toInt, item.toInt, rate.toDouble)})// 使用ALS训练推荐模型val rank = 10val numIterations = 10val model = ALS.train(ratings, rank, numIterations, 0.01)ALS算法实现于org.apache.spark.ml.recommendation.ALS.scala文件中- Rating也在recommendation里面
- 推荐
- 推荐
- 推荐~
- 推荐
- 推荐
- 推荐
- 推荐
- 推荐
- 推荐!!!
- 推荐
- 推荐
- 推荐
- 推荐
- 推荐
- 推荐
- 推荐
- 推荐
- 推荐
- 对于系统API,只知其一造成重复写入
- python问卷
- UVA-129 Krypton Factor 困难的串
- IOS基础-retain, copy, assign区别
- Android 常见分辨率(mdpi、hdpi 、xhdpi、xxhdpi )及屏幕适配注意事项
- 推荐
- DoublingStackOfStrings(1308 P102)
- Python之倒序访问list
- ansible之inventory文件
- coreseek及sphinx的.conf典型简单配置
- http://www.unity.5helpyou.com/3193.html
- POJ-3628--Bookshelf 2--01背包
- Eclipse打包成jar文件的两种方法
- EasyUI-datagrid列显示图片


