深度优先搜索
来源:互联网 发布:如何做数据分析研究 编辑:程序博客网 时间:2024/06/14 20:34
深搜
(一):解释与理解
深度优先搜索是一种在开发爬虫早期使用较多的方法。它的目的是要达到被搜索结构的叶结点(即那些不包含任何超链的HTML文件) 。在一个HTML文件中,当一个超链被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超链结果之前必须先完整地搜索单独的一条链。深度优先搜索沿着HTML文件上的超链走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超链。当不再有其他超链可选择时,说明搜索已经结束。
事实上,深度优先搜索属于图算法的一种,英文缩写为DFS即Depth First Search.其过程简要来说是对每一个可能
的分支路径深入到不能再深入为止,而且每个节点只能访问一次。深度优先搜索的缺点也出来了:难以寻找最优解,
仅仅只能寻找有解。其优点就是内存消耗小。

举例说明之:上图是一个无向图,如果我们从A点发起深度优先搜索(以下的访问次序并不是唯一的,第二个点既
可以是B也可以是C,D),则我们可能得到如下的一个访问过程:A->B->E(没有路了!回溯到A)->C->F->H->G->D
(没有路,最终回溯到A,A也没有未访问的相邻节点,本次搜索结束)简要说明深度优先搜索的特点:每次深度优先
搜索的结果必然是图的一个连通分量.深度优先搜索可以从多点发起.如果将每个节点在深度优先搜索过程中的"结束时
间"排序(具体做法是创建一个list,然后在每个节点的相邻节点都已被访问的情况下,将该节点加入list结尾,然后逆转
整个链表),则我们可以得到所谓的"拓扑排序",即topological sort.
(二):基本思路
①:无向图的深度优先搜索
下面以"无向图"为例,来对深度优先搜索进行演示。
对上面的图G1进行深度优先遍历,从顶点A开始。
第1步:访问A。
第2步:访问(A的邻接点)C。
在第1步访问A之后,接下来应该访问的是A的邻接点,即"C,D,F"中的一个。但在本文的实现中,顶点ABCDEFG
是按照顺序存储,C在"D和F"的前面,因此,先访问C。
第3步:访问(C的邻接点)B。
在第2步访问C之后,接下来应该访问C的邻接点,即"B和D"中一个(A已经被访问过,就不算在内)。而由于B在D
之前,先访问B。
第4步:访问(C的邻接点)D。
在第3步访问了C的邻接点B之后,B没有未被访问的邻接点;因此,返回到访问C的另一个邻接点D。
第5步:访问(A的邻接点)F。
前面已经访问了A,并且访问完了"A的邻接点B的所有邻接点(包括递归的邻接点在内)";因此,此时返回到访问
A的另一个邻接点F。
第6步:访问(F的邻接点)G。
第7步:访问(G的邻接点)E。
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
②:有向图的深度优先搜索
下面以"有向图"为例,来对深度优先搜索进行演示。
对上面的图G2进行深度优先遍历,从顶点A开始。
第1步:访问A。
第2步:访问B。
在访问了A之后,接下来应该访问的是A的出边的另一个顶点,即顶点B。
第3步:访问C。
在访问了B之后,接下来应该访问的是B的出边的另一个顶点,即顶点C,E,F。在本文实现的图中,顶点ABCDEFG
按照顺序存储,因此先访问C。
第4步:访问E。
接下来访问C的出边的另一个顶点,即顶点E。
第5步:访问D。
接下来访问E的出边的另一个顶点,即顶点B,D。顶点B已经被访问过,因此访问顶点D。
第6步:访问F。
接下应该回溯"访问A的出边的另一个顶点F"。
第7步:访问G。
因此访问顺序是:A -> B -> C -> E -> D -> F -> G
DFS函数的调用堆栈

此后堆栈调用返回到V0那一层,因为V1那一层也找不到跟V1的相邻未访问节点

此后堆栈调用返回到V3那一层

此后堆栈调用返回到主函数调用DFS(V0,0)的地方,因为已经找到解,无需再从别的节点去搜别的路径了。
(四):例题代码理解
①:这第一个代码是从网上淘的;
HDU-1181
Sample Input
so
soon
river
goes
them
got
moon
begin
big
0
Sample Output
Yes.

1 //DFS模板题 HDU 1181 2 3 #include <iostream> 4 #include <string.h> 5 #include <queue> 6 #include <string> 7 using namespace std; 8 string str[300]; 9 int vis[300],i;//标记数组,在一条路径中,被查找过的节点不能被再次查找,不然就会使路径出现循环10 int flag = 0;//用于判定搜索是否查找到路径11 void dfs(string use)12 {13 char last = use[use.length() - 1];14 if (flag == 1)//如果已经找到了就直接结束,减少不必要的搜索过程15 return;16 for (int k = 0;k<i;k++)//如果视当前use字符串为当前节点,那么for循环就应该遍历下一层的所有可能节点17 {18 if (vis[k] == 0&& str[k][0] == last)//如果未被访问,且其首字符合本节点末字符匹配,就可以作为搜索树的分支节点19 {20 vis[k] = 1;//每确定路径中的一个节点,就标记起来21 if (str[k][str[k].length() - 1] == 'm')//满足搜索的结束条件就设置flag并退出22 {23 flag = 1;24 return;25 }26 else27 dfs(str[k]);//否则继续向下搜索28 //vis[k]=029 //大部分DFS在一条路径搜索失败后都需要回溯到上一状态30 //通常需要把从本节点后产生的标记都重置31 //实际上是否需要重置标记,应该看路径来源是否会对节点能否到达出口产生影响32 //在本题中。如果str[k]是到所求路径中的一个节点,不管从什么途径搜索到了str[k],都不影响他到达终点。33 }34 }35 }36 int main() {37 38 while (cin >> str[i])39 {40 if (str[i] == "0")41 {42 memset(vis, 0, sizeof(vis));43 flag = 0;44 for (int j = 0;j<i;j++)45 {46 if (str[j][0] == 'b')//如果满足起始条件就进入搜索过程47 {48 vis[j] = 1;49 dfs(str[j]);50 }51 }52 i = 0;//有多组测试样例,每完成一组,重置i53 if (flag == 1)54 cout << "Yes." << endl;55 else56 cout << "No." << endl;57 }58 else59 i++;60 }61 return 0;62 }
#include<cstdio>#include<cstring>#include<string>// string 是c++ 的字符串数据类型 *(s[v].end()-1) 这是字符串尾字母 *(s[j].begin() 这是字符串首字母#include<iostream>using namespace std;string str,s[1000],a[1000];int mark[1000],i,flag;char x,y;void dfs(int v){ if(*(s[v].end()-1)=='m')//当查到有可以连接且尾字母是 m 的标记 一下说明可以完成任务了 ,此处标记完就可以//结束了,就你没有必要再查了,因为你已经完成任务了 flag =1 后加一个 return ; 就结束了 flag=1; else { for(int j=1;j<=i;j++) { if(!mark[j]&&*(s[j].begin())==*(s[v].end()-1))// 如果单词没被查过且符合要求首尾可以相连的 { mark[j]=1; dfs(j); //mark[j]=0;// 此处就不用标记回溯了,因为当你查到某个单词结束时就说明这条线已经走不通了,//所以说这个单词就没必要再查了 } } }}int main(){ while(cin>>str) { i=2; if(str=="0") //如果是没有单词就是完成不了任务也需要输出 { printf("NO\n"); continue; } else s[1]=str; while(cin>>str,str!="0") { s[i++]=str; } flag=0; for(int j=1;j<=i;j++) { if(*(s[j].begin())=='b')//因为开始必须是b 所以直接找出b开头的位置节省时间 { memset(mark,0,sizeof(mark)); mark[j]=1;//找到后标记一下从此位置开始查 dfs(j); } } if(flag) printf("Yes.\n"); else printf("No.\n"); } return 0;}
②:下面是我自己根据啊哈!算法中的解救啊哈所写的代码:
问题介绍:迷宫由n行m列的单元格组成(n和m都小于等于50),每个单元格要么是空地,要么是障碍物。你的任务是帮助小哼找到一条从迷宫的起点通往小哈所在位置的最短路径。
分析:①:首先我们可以用一个二维数组来存储这个迷宫,刚开始的时候,小哼处于迷宫的入口处(1,1),小哈在(p,q)。我们只能一个一个地去尝试,我们可以让小哼往右边走,直到走不通的时候再回到这里,再去尝试另外一个方向。我们规定一个顺序,按照顺时针的方向来尝试(即按照右下左上的顺序去尝试)。
②:现在我们尝试用深度优先搜索来实现这个方法。先来看dfs()函数如何写。dfs()函数的功能是解决当前应该怎么办。小哼处在某个点的时候需要处理的是:先检查小哼是否已经到达小哈的位置,如果没有达到则找出下一步可以走的地方。为了解决这个问题,dfs()函数需要三个参数,分别是当前的这个点x,y,以及已经走的步数step;
③:判断是否已经到达小哈的位置这一点很好实现,只需判断当前的坐标和小哈的坐标是否相等就可以了,如果相等就可以了,表明已经到达小哈的位置,
④:如果没有到达则需找出下一步可以走的地方,因为有四个地方可以走,根据之前的约定(右下左上),需要我们定义一个nexts数组,通过这个数组使用循环就很容易获得下一步的坐标,下一步的横坐标tx,下一步的纵坐标ty;
for(int k=0;i<4;k++)
{
//计算的下一个点的坐标
tx=x+nexts[k][0];
ty=y+nexts[k][1];
}
⑤:接下来要对下一个点进行判断。包括是否越界,是否有障碍物,以及这个点已经在路径中(即避免重复访问一个点)。需要用book[tx][ty]来记录格子(tx,ty)是否已经在路径中。
如果这个点符合要求,就对这个点进行一步的扩展,即dfs(tx,ty,step+1),注意这里是step+1,因为一旦你从这个点开始继续往下尝试,就意味着你的步数已经增加了1。代码实现如下:
for(int k=0;k<=3;k++)
{
//计算的下一个点的坐标
...;
...;//同上
//判断是否越界
if(tx<1||tx>n||ty<1||ty>m)
continue;
//判断该点是否为障碍物或则已经在路径中
if(a[tx][ty]==0&&book[tx][ty]==0)
{
book[tx][ty]=1;//标记这个点已经走过了
dfs(tx,ty,step+1);//开始尝试下一个点
book[tx][ty]=0;//尝试结束,取消这个点的标记
}
}
好了,看一下完整的的代码吧!!
#include<stdio.h>
int n,m;
int p,q,min==9999999;
int a[51][51],book[51][51];
void dfs(int x,int y,int step)
{
int next[4][2]={{0,1}//向右走
{1,0}//向下走
{0,-1}//向左走
{-1,0}};//向上走
int tx,ty,k;
if(x==p&&y==q)
{
//更新最小值
if(step<min)
min=step;
return ;//这里的返回很重要
}
//枚举四种走法
for(k=0;k<4;k++)
{
//计算下一点的坐标
tx=x+next[k][0];
ty=y+next[k][1];
//判断是否越界
if(tx<1||tx>n||ty<1||ty>m)
continue;
//判断该点是否是障碍物或则已经在路径中
if(a[tx][ty]==0&&book[tx][ty]==0)
{
book[tx][ty]=1;
dfs(tx,ty,step+1);
book[tx][ty]=0;
}
}
return ;
}
int main()
{
int i,j,startx.starty;
//读入n行,m列;
scanf("%d %d",&n,&m);
//读入迷宫
for(i=1;i<=n,i++)
for(j=1;j<=m;j++)
scanf("%d",%a[i][j]);
//读入起点和终点
scanf("%d%d%d%d",&startx,&starty,&p,&q);
//从起点开始搜索
book[startx][starty]=1;//已经标记在路径中,防止后面重负走
//第一个参数是期待你的x坐标,第二个参数是起点的y坐标,第三个参数是初始步数0
dfs(startx,starty,0);
//输出最短的步数
printf("%d",min);
getchar();
return 0;
}
测试数据:
5 4
0 0 1 0
0 0 0 0
0 0 1 0
0 1 0 0
0 0 0 1
1 1 4 3
结果:
7
③:从网上又搜了一些:
1.题目描述
想必大家都玩过一个游戏,打牌游戏,叫做“24点”:给出4个整数(A(1),J(11),Q(12),K(13)),要求用加减乘除4个运算使其运算结果变成24,4个数字要不重复的用到计算中。
例如给出4个数:A(1)、2、3、4。我可以用以下运算得到结果24:
1*2*3*4 = 24;2*3*4/1 = 24;(1+2+3)*4=24;……
如上,是有很多种组合方式使得他们变成24的,当然也有无法得到结果的4个数,例如:1、1、1、1。
现在我给你这样4个数,你能告诉我它们能够通过一定的运算组合之后变成24吗?这里我给出约束:数字之间的除法中不得出现小数,例如原本我们可以1/4=0.25,但是这里的约束指定了这样操作是不合法的。
2.解法:搜索树
这里为了方便叙述,我假设现在只有3个数,只允许加法减法运算。我绘制了如图5-1的搜索树。
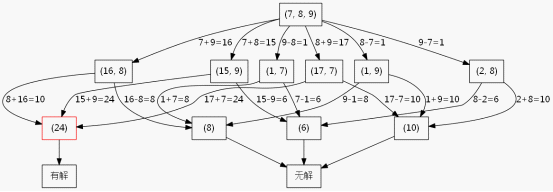
图5-1
此处只有3个数并且只有加减法,所以第二层的节点最多就6个,如果是给你4个数并且有加减乘除,那么第二层的节
点就会比较多了,当延伸到第三层的时候节点数就比较多了,使用BFS的缺点就暴露了,需要很大的空间去维护那个队列。而你看这个搜索树,其实第一层是3个数,到了第二层就变成2个数了,也就是递归深度其实不会超过3层,所以采用DFS来做会更合理,平均效率要比BFS快
- #include<stdio.h>
- #include<iostream>
- #include<algorithm>
- using namespace std;
- int flag;
- char a[4];
- int b[4];
- //搜索到第4层的时候 进行判断 如果没有到第4层的话 就加减乘除这一层的数
- void dfs(int cur,int zhi) {
- if(cur==4) {
- if(zhi==24)
- flag=1;
- else
- flag=0;
- return;
- }
- else {
- dfs(cur+1,zhi+b[cur+1]);
- if(flag)
- return;
- dfs(cur+1,zhi-b[cur+1]);
- if(flag)
- return;
- dfs(cur+1,zhi*b[cur+1]);
- if(flag)
- return;
- if(cur<=2 && zhi % b[cur+1] == 0) {
- dfs(cur+1,zhi/b[cur+1]);
- if(flag)
- return;
- }
- }
- }
- int main() {
- for(int i=0;i<4;i++) {
- cin>>a[i];
- if(a[i]=='A')
- b[i]=1;
- else if(a[i]=='J')
- b[i]=11;
- else if(a[i]=='Q')
- b[i]=12;
- else if(a[i]=='K')
- b[i]=13;
- else
- b[i]=a[i]-'0';
- }
- flag=0;
- //全排列 总共24中情况的话 每种都做下来 随后进行深搜 有一种情况遇到即可
- sort(b, b+4);
- do{
- dfs(0,b[0]);
- }while(next_permutation(b,b+4)&&!flag);
- if(flag)
- cout<<"Y"<<endl;
- else
- cout<<"N"<<endl;
- return 0;
测试数据:
讲一下这段代码中的next_permutation(b,b+4)这个是什么意思:
next_permutation()函数功能是输出所有比当前排列大的排列,顺序是从小到大。
而prev_permutation()函数功能是输出所有比当前排列小的排列,顺序是从大到小。
组合数学中经常用到排列,这里介绍一个计算序列全排列的函数:next_permutation(start,end),和prev_permutation(start,end)。这两个函数作用是一样的,区别就在于前者求的是当前排列的下一个排列,后一个求的是当前排列的上一个排列。至于这里的“前一个”和“后一个”,我们可以把它理解为序列的字典序的前后,严格来讲,就是对于当前序列pn,他的下一个序列pn+1满足:不存在另外的序列pm,使pn<pm<pn+1.
对于next_permutation函数,其函数原型为:
#include <algorithm>
bool next_permutation(iterator start,iterator end)
当当前序列不存在下一个排列时,函数返回false,否则返回true
我们来看下面这个例子:
若是while(next_permutation(num,num+3)){
count<<num[0]<<" "<<num[1]<<" "<<num[2]<<endl;
}
这样只执行了一次;即:如果你输入3,输出结果是 123;
输出结果为:

next_permutation(num,num+n)函数是对数组num中的前n个元素进行全排列,同时并改变num数组的值。
另外,需要强调的是,next_permutation()在使用前需要对欲排列数组按升序排序,否则只能找出该序列之后的全排列数。比如,如果数组num初始化为2,3,1,那么输出就变为了:

此外,next_permutation(node,node+n,cmp)可以对结构体num按照自定义的排序方式cmp进行排序。
- 深度优先搜索
- 深度优先搜索
- 深度优先搜索 DFS
- 深度优先搜索遍历
- 深度优先搜索 DFS
- 深度优先搜索
- 深度优先搜索
- 深度优先搜索算法
- hdoj1015Safecracker(深度优先搜索)
- [AI]深度优先搜索
- 深度优先搜索算法
- DFS 深度优先搜索
- 深度优先搜索
- 深度优先搜索算法
- 图解深度优先搜索
- 深度优先搜索
- 深度优先搜索
- 深度优先搜索算法
- linux环境变量设置错误后,如何恢复解决方案
- Hyperscan 介绍与安装
- Android蓝牙BLE之RSSI读写(2)
- <Android 基础(三十九)> SpannableString
- ios-GCD的队列介绍
- 深度优先搜索
- cmd命令行中执行Java文件中文字符乱码情况解决
- JavaScript_05
- Web系统大规模并发——电商秒杀与抢购
- c++---内存问题---delete p和delete[]p 区别
- ecshop jquery与transport.js冲突解决方案
- 线程调度算法分析
- n个数的排序--堆排序
- Livy:基于Apache Spark的REST服务


