深入浅出FEA-spk,有原理有案例接地气!
来源:互联网 发布:linux close 编辑:程序博客网 时间:2024/04/29 11:05
随着大数据和云计算时代的到来,数据规模越来越大,随之出现了很多大数据框架,比如Hadoop用来实现分布式文件存储的HDFS,MapReduce、Spark、Storm等计算框架,Hbase,Mongob等数据库,Hive数据仓库。
为了更好的处理海量数据,使得不懂Spark的数据分析人员可以很方便的使用Spark来进行数据分析和挖掘,FEA研发了FEA-spk技术。FEA-spk是以Spark为内核引擎,提供了交互式的分析,它的功能几乎覆盖了所有的spark操作,并且可以对结果数据进行可视化展示。它可以和众多的大数据计算框架结合,比如hive,hbase,mongodb,hdfs等。可以保存和读取各种文件格式,比如parquet,avro,orc,json,csv等文件格式,真正做到了和大数据进行融合!
我们今天,从架构、运行原理、任务的查看和监控、内存的分配与调优、DF表转化等方面,深入浅出认识一下FEA-spk。
1. FEA-spk的架构
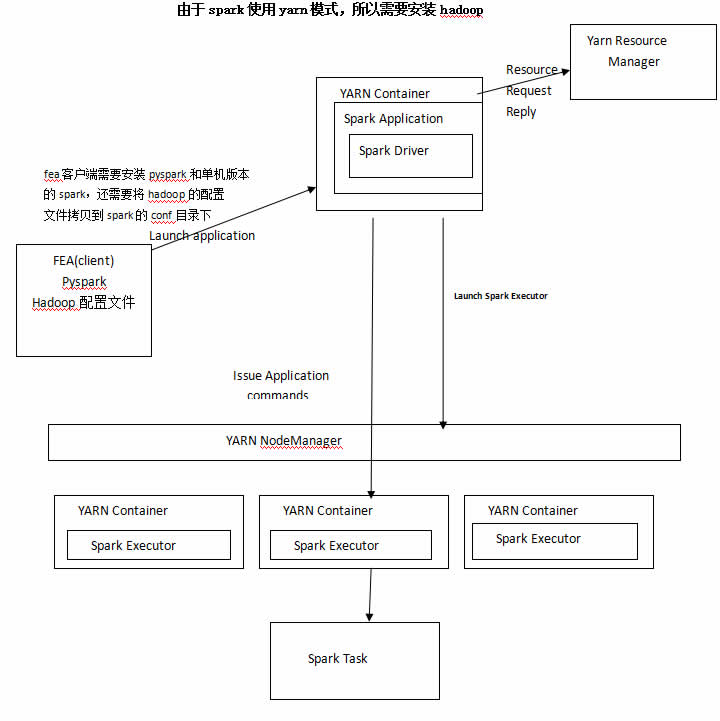
2. FEA-spk运行原理
FEA-spk采用yarn-client模式运行在hadoop的yarn上。在使用FEA-spk的时候,在客户端的FEA界面先要创建一个spk的连接,如下图所示:
![]()
这个时候就会在Hadoop yarn界面启动一个应用,如下图所示:
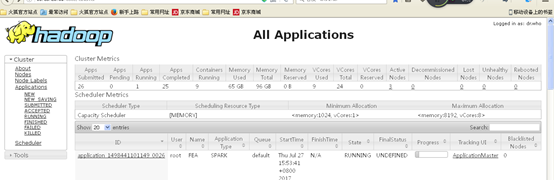
然后就可以加载数据,对数据进行分析了。
FEA-spk支持多种数据源,最常见的当然是HDFS了,它是分布式存储文件系统,当我们要处理的数据量很大,比如TB级的时候,就可以把数据放在HDFS上面,然后使用FEA-spk把HDFS数据加载到我们使用的Spark集群的内存里面,克服了单机内存不足的问题,使得分布式内存计算成为了可能。
下面我们来加载一个存放在hdfs目录的csv文件
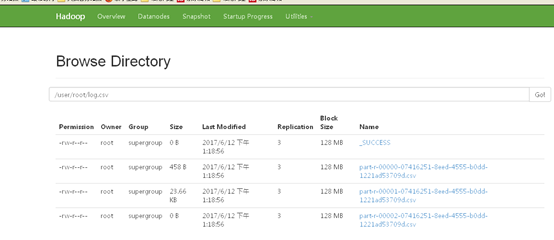

随后可以对DF表进行各种各样的操作,比如group,agg等,这里不再叙述了(在FEA官方网站有FEA-spk的操作手册,很详细的介绍了各种操作)。
最后,对计算后的结果进行保存,比如保存到hdfs,hive,mysql中等。
3. FEA-spk运行任务的查看和监控
我们在运行FEA-spk的时候,需要查看运行了多长时间,划分为几个stage,
每个stage的task数,运行了多长时间等,按照以下的步骤进行操作.
![]()
点击ApplicationMaster,进入下面的页面
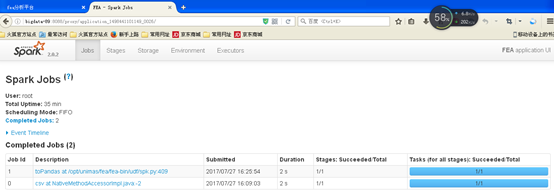
然后就可以查看各种指标了
4. FEA-spk内存的分配与调优
由于FEA-spk是基于内存进行计算的,所以对内存的分配就显得尤为重要。

一般要调节上图的几个参数。在FEA客户端的$SPARK_HOME/conf的
spark-defaults.conf目录
5. FEA-spk的DF表和FEA的DF表转化
如果我们需要对FEA-spk的DF表转化为FEA的DF表,只需要下面一条命令就可以了
df=@udf sdf by spk.to_DF
同理,如果要转化为FEA-spk的DF表,需要运行以下一条命令
sdf=@udf spk,df by spk.to_SDF
以上就是FEA-spk技术的完整介绍,希望大家多多支持哦。
- 深入浅出FEA-spk,有原理有案例接地气!
- 基于FEA spk的web日志分析
- 脚接地气
- 使用FEA Spk探索经典数据集MovieLens
- 好的产品经理6大要素:有案例有底气!
- cyress的68013有一个接地脚
- 农村电子商务须“接地气”
- 中国电视剧不接地气
- 让微博营销更接地气
- 最接地气的职业规划
- 活的接地气一点
- 那些接地气的基础
- 接地气的flex布局
- jQuery有过气之势?
- 腹有诗书气自华
- 腹有诗书气自华
- 腹有诗书气自华
- 有才而性缓,有智而气和
- HttpURLConnection用法详解
- echarts和highcharts区别
- Vuex 入门介绍
- 计算机编码方式总结
- wampserver2.5局域网IP访问配置
- 深入浅出FEA-spk,有原理有案例接地气!
- java-ExecutorService实现线程池
- 批量修改文件后缀名
- Kotlin学习资料
- 代码干货 | vue模板语法
- 微信小程序之数据缓存
- 闭包
- 分页函数分享
- SQL 统一更改转换所有表或指定表所有列或指定列的类型 名称 长度 精度


