万亿级数据洪峰下的分布式消息引擎
来源:互联网 发布:php教程视频 百度云 编辑:程序博客网 时间:2024/05/01 17:02
点击查看全文
前言
通过简单回顾阿里中间件(Aliware)消息引擎的发展史,本文开篇于双11消息引擎面临的低延迟挑战,通过经典的应用场景阐述可能会面临的问题 - 响应慢,雪崩,用户体验差,继而交易下跌。为了应对这些不可控的洪峰数据,中间件团队通过大量研究和实践,推出了低延迟高可用解决方案,在分布式存储领域具有一定的普适性。在此基础上,通过对现有有限资源的规划,又推出了分级的容量保障策略,通过限流、降级,甚至熔断技术,能够有效保障重点业务的高吞吐,成功的支撑集团包括海外业务平缓舒畅地度过双11高峰。与此同时,在一些对高可靠、高可用要求极为苛刻的场景下,中间件团队又重点推出了基于多副本机制的高可用解决方案,能够动态识别机器宕机、机房断网等灾难场景,自动实现主备切换。整个切换过程对用户透明,运维开发人员无需干预,极大地提升消息存储的可靠性以及整个集群的高可用性。
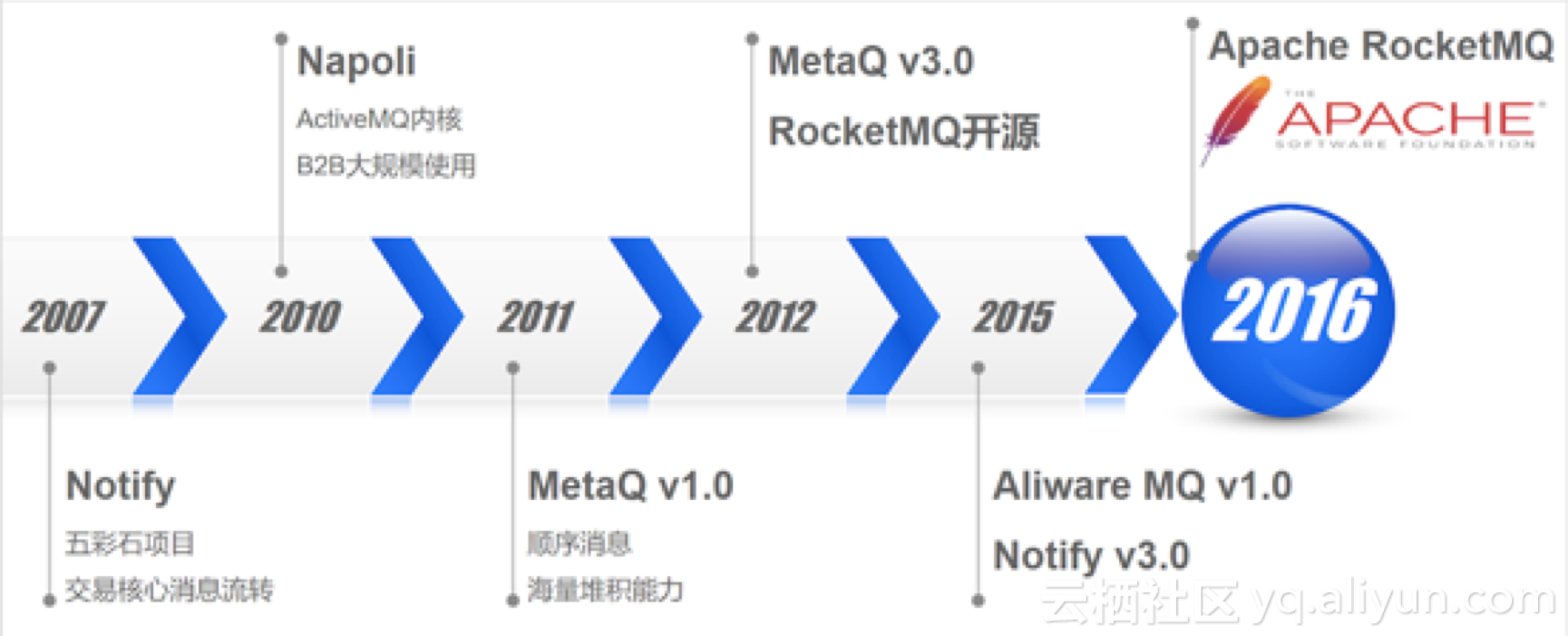
1. 消息引擎家族史
阿里中间件消息引擎发展到今日,前前后后经历了三代演进。第一代,推模式,数据存储采用关系型数据库。在这种模式下,消息具有很低的延迟特性,尤其在阿里淘宝这种高频交易场景中,具有非常广泛地应用。第二代,拉模式,自研的专有消息存储。能够媲美Kafka的吞吐性能,但考虑到淘宝的应用场景,尤其是其交易链路等高可靠场景,消息引擎并没有一位的追求吞吐,而是将稳定可靠放在首位。因为采用了长连接拉模式,在消息的实时方面丝毫不逊推模式。在前两代经历了数年线上堪比工况的洗礼后,中间件团队于2011年研发了以拉模式为主,兼有推模式的高性能、低延迟消息引擎RocketMQ。并在2012年进行了开源,经历了6年双11核心交易链路检验,愈久弥坚。目前已经捐赠给阿帕奇基金会(ASF),有望成为继ActiveMQ,Kafka之后,Apache社区第三个重量级分布式消息引擎。时至今日,RocketMQ很好的服务了阿里集团大大小小上千个应用,在双11当天,更有不可思议的万亿级消息流转,为集团大中台的稳定发挥了举足轻重的作用。
2. 低延迟可用性探索
疾风吹征帆,倏尔向空没。千里在俄顷,三江坐超忽。—孟浩然
2.1低延迟与可用性
随着Java语言生态的完善,JVM性能的提高,C和C++已经不再是低延迟场景唯一的选择。本章节重点介绍RocketMQ在低延迟可用性方面的一些探索。
应用程序的性能度量标准一般从吞吐量和延迟两方面考量。吞吐量是指程序在一段时间内能处理的请求数量。延迟是指端到端的响应时间。低延迟在不同的环境下有不同的定义,比如在聊天应用中低延迟可以定义为200ms内,在交易系统中定义为10ms内。相对于吞吐量,延迟会受到很多因素的影响,如CPU、网络、内存、操作系统等。
根据Little’s law,当延迟变高时,驻留在分布式系统中的请求会剧增,导致某些节点不可用,不可用的状态甚至会扩散至其它节点,造成整个系统的服务能力丧失,这种场景又俗称雪崩。所以打造低延迟的应用程序,对提升整个分布式系统可用性有很大的裨益。
2.2 低延迟探索之路
RocketMQ作为一款消息引擎,最大的作用是异步解耦和削峰填谷。一方面,分布式应用会利用RocketMQ来进行异步解耦,应用程序可以自如地扩容和缩容。另一方面,当洪峰数据来临时,大量的消息需要堆积到RocketMQ中,后端程序可以根据自己的消费速度来进行数据的读取。所以保证RocketMQ写消息链路的低延迟至关重要。
在今年双11期间,天猫发布了红包火山的新玩法。该游戏对延迟非常敏感,只能容忍50ms内的延迟,在压测初期RocketMQ写消息出现了大量50~500ms的延迟,导致了在红包喷发的高峰出现大量的失败,严重影响前端业务。下图为压测红包集群在压测时写消息延迟热力图统计。
点击查看全文

- 万亿级数据洪峰下的分布式消息引擎
- 万亿级数据洪峰下的分布式消息引擎
- 万亿级数据洪峰下的分布式消息引擎
- 万亿级数据洪峰下的分布式消息引擎
- 万亿级数据洪峰下的分布式消息引擎
- 万亿级数据洪峰下的分布式消息引擎
- 【双11技术揭秘】万亿级数据洪峰下的分布式消息引擎
- mongodb遍历万亿级数据,论索引的重要性
- 腾讯钟翔平:开放万亿级数据体系连接信息孤岛
- 洪峰的黑客道
- 百万级数据下的mysql深度解析
- 阿里万亿交易量级下的秒级监控
- [转] 洪峰的黑客道编程三字经
- 基于消息的分布式架构
- 基于消息的分布式架构
- 分布式的消息系统Kafka
- 基于消息的分布式架构
- 基于消息的分布式架构
- 中兴新支点国产操作系统勇于突破, 挑战龙芯无缝兼容QQ等传统应用
- [笔记分享] [Camera] 各种相机种类及区别
- mysql导入导出sql文件
- Spring中的AOP(五)——定义切入点和切入点指示符
- centOS-7静态ip配置
- 万亿级数据洪峰下的分布式消息引擎
- http协议以及面试中常出现的问题总结
- 信号(signals)和槽(slots)
- 微信浏览器关闭
- Spring 配置多环境
- tf.add()
- Unity开发中的各种职位
- Java中int与Integer的使用区别
- FragmentTabHost、TabHost外接刷卡器,键盘等设备输入内容时,与EditText争抢焦点导致输入异常


