kafka简要介绍
来源:互联网 发布:傲剑肉身升级数据大全 编辑:程序博客网 时间:2024/06/15 19:06
kafka官网的介绍,翻译一下,顺便自己也做下笔记。
简介
Kafka是Linkedln开发的,基于发布/订阅的,采用Scala编写的分布式流式平台(distributed streaming platform)。
所谓的流式平台,需要满足一下三个要点:
能够发布和订阅流的消息。从该角度来讲,它类似于一个消息队列或者企业级消息系统。
它能够让你以容错的方式(in a fault-tolerant way)存储流记录。
它能够让你在流记录出现的时候处理它(实时处理的意思)。
kafka通常被运用在以下两类应用中:
建立实时的流处理管道,从而可以可靠的获取系统或者应用直接的数据。
建立实时流处理应用,传输流数据或者对其反应。
一些关于kafka的概念:
kafka以集群的形式在一个或多个服务器上运行。
kafka集群在被叫做topics的类别下存储流数据(与RabbitMQ挺类似的)
每条记录包含一个key,一个值还有一个时间戳
kafka主要包含四个核心APIs:
- Producer API允许一个应用发布流记录到一或多个kafka的topics。
- Consumer API允许一个应用订阅topic,然后处理其中的流记录。
- Streams API允许应用扮演stream processor的角色,从一或多个topics消费一个输入流,同时生产一个输出流到一或多个topics。
- Connector API允许构建并运行可重用的消费者与生产者来连接kafka的topics到已经存在的应用或者数据系统,例如连接到一个RDS数据库,来捕获每次表的变化。
Topics与Logs
所谓topic,也就是类别,或者说发布记录的地方。topic经常有很多消费者,同时读取其中数据。对于每个topic,kafka集群维持一个类似以下的分区日志:
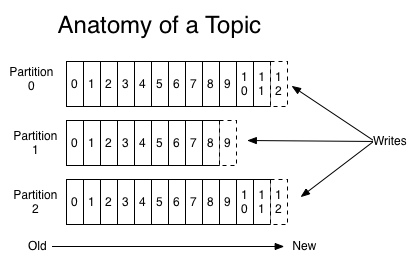
每一个分区都是一个有序不可变的序列记录,并且不断被追加,从而形成一个结构化的操作日志。每条记录都分配一个连续的偏移量offset,唯一标识该记录。
无论是否被消费,kafka使用一个可配置的有效期来保持所有的发布记录,从而在一定期限内可以被消费,之后就被舍弃释放空间。针对不同数据大小,kafka性能是常数级别的,所以不用担心存放时间太长。
实际上,对于每个消费者唯一的元数据是偏移量,也就是消费者在log中的消费到的位置。消费者可以任意控制该位置。
以上功能意味着消费者非常轻便(cheap),并不会对集群或其他消费者带来较大影响(互不影响)。
分区的日志有以下几个目的:
- 允许日志大小超过单机限制。每个单独的分区必须兼容宿主机,而一个topic可以有多个分区来处理任意数量的数据。
- 日志作为并行计算的最小单元。
分布
日志分区分布在kafka集群的服务器上。为了容错,每个分区在一个可配置数量的服务器上留有备份。
每个分区都有一个服务器充当leader,其余作为followers。leader处理所有读与写请求,followers被动进行复制。如果leader挂掉了,一个followers会成为新的leader。每个服务器充当一些分区的leader,同时其他分区的follower,所以集群很均衡。
生产者
生产者可以指定将哪条记录分配到topic下的哪个分区,可以通过循环的方式来简单的进行负载均衡,也可以根据一些语义函数进行。
消费者
消费者以consumer group进行标签分类化,每条记录只被交付给订阅该主题的group中的一个消费者。
如果所有的消费者实例都在同一个消费组中,那么一条消息将会有效地负载平衡给这些消费者实例。如果所有的消费者实例在不同的消费组中,那么每一条消息将会被广播给所有的消费者处理。

kafka仅在分区内维持一个完整的顺序记录,对于大多数应用来说已足够。
保证
生产者发送的消息会按顺序追加到分区上。比如,如果M1和M2消息都被同一个生产者发送,M1先发送,M1的偏移量将比M2的小且更早出现在日志上面。
一个消费者实例按照记录存储在日志上的顺序读取。
一个主题的副本数是N,我们可以容忍N-1个服务器发生故障而不会丢失任何提交到日志中的记录。
- Kafka简要介绍
- Kafka简要介绍
- kafka简要介绍
- Kafka简要图解
- 简要介绍
- 简要介绍
- kafka 介绍
- Kafka介绍
- Kafka介绍
- Kafka 介绍
- kafka介绍
- kafka介绍
- Kafka介绍
- kafka 介绍
- Kafka介绍
- Kafka介绍
- Kafka介绍
- Kafka介绍
- c++中的虚函数
- 树状数组(2) 小白算法学习
- hust 1010 The Minimum Length (KMP)
- static修饰符的作用及应用
- 3676: [Apio2014]回文串
- kafka简要介绍
- Show and Tell Lessons learned from the 2015 MSCOCO Image Captioning Challenge论文及tensorflow源码解读
- 软件开发模型
- 网络请求No peer certificate
- 更改PDF文件中的背景颜色需要如何去操作
- 兔子与星空(POJ NO.5442)
- 学习资源
- VS插件TabsStudio
- 排序算法


