百万数据进行查询与排序
来源:互联网 发布:winaip阅读器软件下载 编辑:程序博客网 时间:2024/05/13 13:36
百万数据进行查询与排序!
在网上找了一堆,有一下几大排序算法如:快速排序,归并排序,堆排序,百万数据查询 。
那什么是快速排序:
1. 快速排序算法是一种不稳定的排序算法。其时间复杂度为O(nlogn),最坏复杂度为O(n^2);快排的平均空间复杂度为O(logn),关于空间界的论断来自于《编程珠玑第2版》第113页。但是其最坏空间复杂度为O(n)。
快速排序的基本思想是使用两个指针来遍历待排序的数组,根据两个指针遍历的方向可以分为两类:第一,两个指针从待排序数组的同一个方向遍历。第二,两个指针分别从带排序数组的两端进行遍历。下列的几种算法都可以归为这两类中的某类。
下图给出的是两个指针从同一方向遍历时的状态。下图的第一个图给出的是循环过程中的状态,在循环中,low指向的是小于枢纽的那部分元素的最右端,high在未排序的部分遍历。循环直到high指针到达right的位置(数组的最右端),如下图第二个图所示。此时数组除了枢纽pivot被划分为两部分:小于pivot的和大于等于pivot的。然后将low和枢纽元素交换就可以得到本次排序的第一趟结果,如下图的第三幅图所示。

当从两个方向分别遍历数组时,下图是遍历的循环过程状态。循环时,low向右移动,high向左移动。

那什么是归并排序:
2.归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该算法采用经典的分治(divide-and-conquer)策略(分治法将问题分(divide)成一些小的问题然后递归求解,而治(conquer)的阶段则将分的阶段得到的各答案"修补"在一起,即分而治之)。
分而治之

可以看到这种结构很像一棵完全二叉树,本文的归并排序我们采用递归去实现(也可采用迭代的方式去实现)。分阶段可以理解为就是递归拆分子序列的过程,递归深度为log2n。
合并相邻有序子序列
再来看看治阶段,我们需要将两个已经有序的子序列合并成一个有序序列,比如上图中的最后一次合并,要将[4,5,7,8]和[1,2,3,6]两个已经有序的子序列,合并为最终序列[1,2,3,4,5,6,7,8],来看下实现步骤。
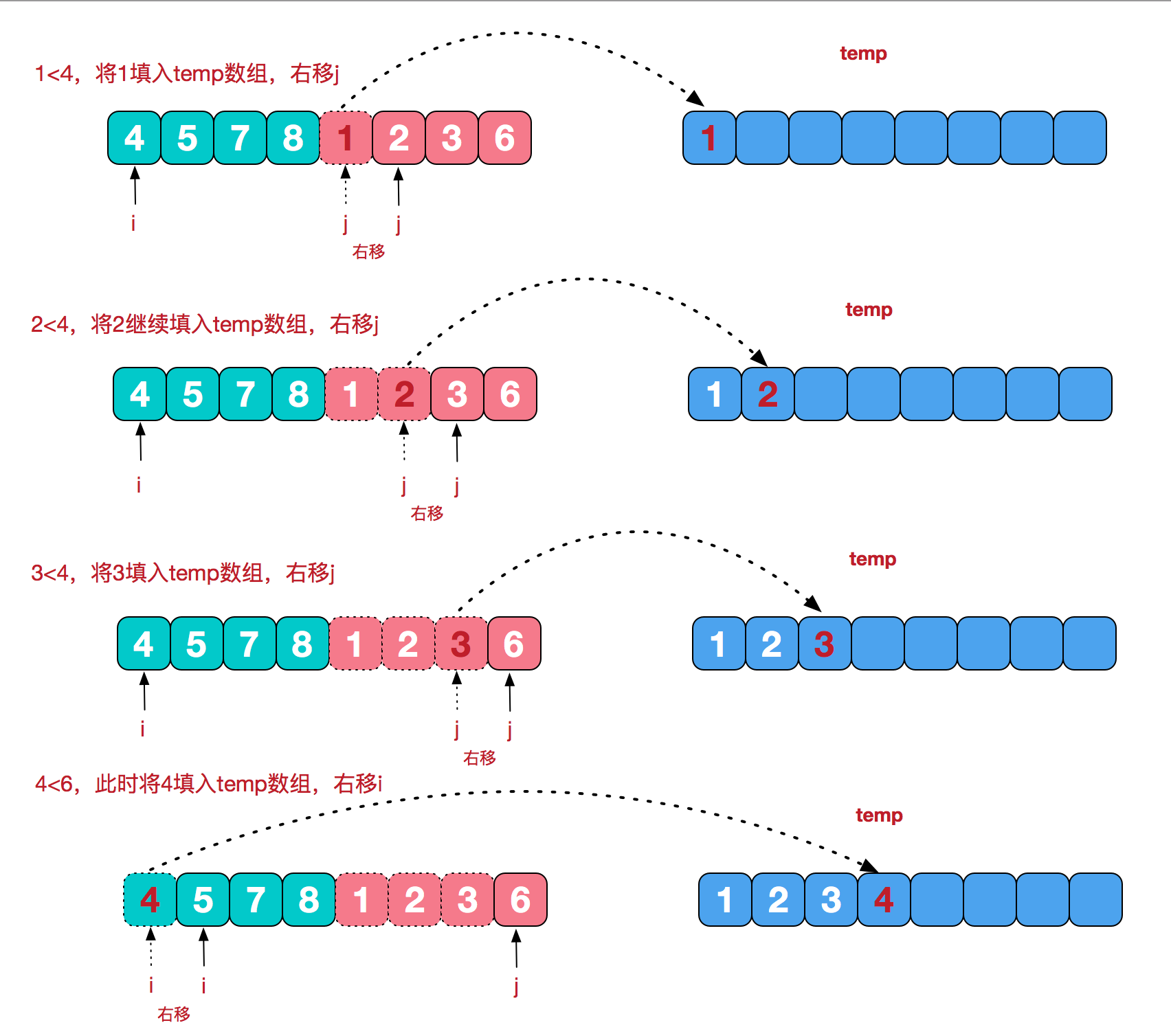
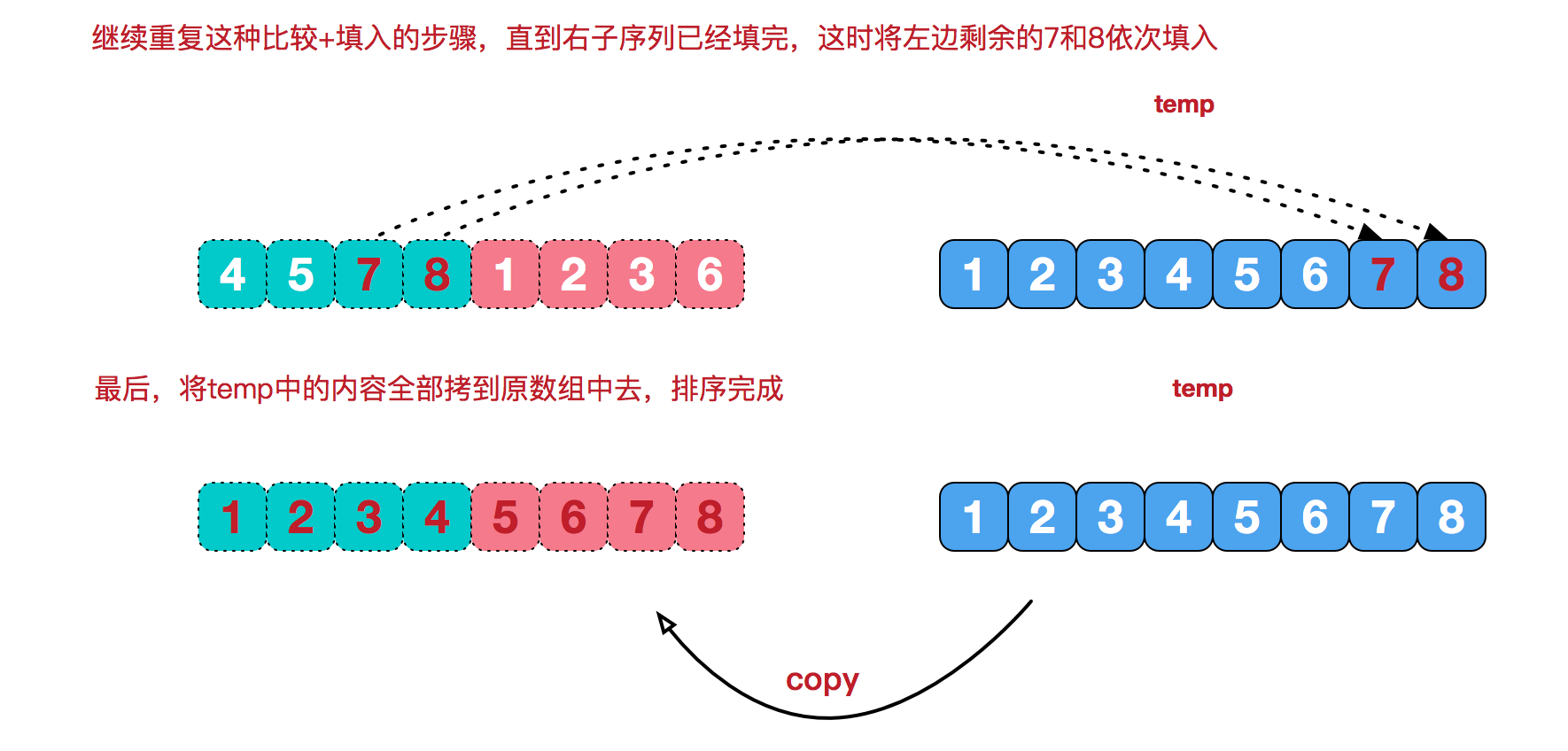
代码实现

package sortdemo;import java.util.Arrays;/** * Created by chengxiao on 2016/12/8. */public class MergeSort { public static void main(String []args){ int []arr = {9,8,7,6,5,4,3,2,1}; sort(arr); System.out.println(Arrays.toString(arr)); } public static void sort(int []arr){ int []temp = new int[arr.length];//在排序前,先建好一个长度等于原数组长度的临时数组,避免递归中频繁开辟空间 sort(arr,0,arr.length-1,temp); } private static void sort(int[] arr,int left,int right,int []temp){ if(left<right){ int mid = (left+right)/2; sort(arr,left,mid,temp);//左边归并排序,使得左子序列有序 sort(arr,mid+1,right,temp);//右边归并排序,使得右子序列有序 merge(arr,left,mid,right,temp);//将两个有序子数组合并操作 } } private static void merge(int[] arr,int left,int mid,int right,int[] temp){ int i = left;//左序列指针 int j = mid+1;//右序列指针 int t = 0;//临时数组指针 while (i<=mid && j<=right){ if(arr[i]<=arr[j]){ temp[t++] = arr[i++]; }else { temp[t++] = arr[j++]; } } while(i<=mid){//将左边剩余元素填充进temp中 temp[t++] = arr[i++]; } while(j<=right){//将右序列剩余元素填充进temp中 temp[t++] = arr[j++]; } t = 0; //将temp中的元素全部拷贝到原数组中 while(left <= right){ arr[left++] = temp[t++]; } }}
执行结果
[1, 2, 3, 4, 5, 6, 7, 8, 9]
最后
归并排序是稳定排序,它也是一种十分高效的排序,能利用完全二叉树特性的排序一般性能都不会太差。java中Arrays.sort()采用了一种名为TimSort的排序算法,就是归并排序的优化版本。从上文的图中可看出,每次合并操作的平均时间复杂度为O(n),而完全二叉树的深度为|log2n|。总的平均时间复杂度为O(nlogn)。而且,归并排序的最好,最坏,平均时间复杂度均为O(nlogn)。
那什么是堆排序:
3.堆排序是一种选择排序,其时间复杂度为O(nlogn)。
堆的定义
n个元素的序列{k1,k2,…,kn}当且仅当满足下列关系之一时,称之为堆。
情形1:ki <= k2i 且ki <= k2i+1 (最小化堆或小顶堆)
情形2:ki >= k2i 且ki >= k2i+1 (最大化堆或大顶堆)
其中i=1,2,…,n/2向下取整;

若将和此序列对应的一维数组(即以一维数组作此序列的存储结构)看成是一个完全二叉树,则堆的含义表明,完全二叉树中所有非终端结点的值均不大于(或不小于)其左、右孩子结点的值。
由此,若序列{k1,k2,…,kn}是堆,则堆顶元素(或完全二叉树的根)必为序列中n个元素的最小值(或最大值)。
例如,下列两个序列为堆,对应的完全二叉树如图:

若在输出堆顶的最小值之后,使得剩余n-1个元素的序列重又建成一个堆,则得到n个元素的次小值。如此反复执行,便能得到一个有序序列,这个过程称之为堆排序。
堆排序(Heap Sort)只需要一个记录元素大小的辅助空间(供交换用),每个待排序的记录仅占有一个存储空间。
堆的存储
一般用数组来表示堆,若根结点存在序号0处, i结点的父结点下标就为(i-1)/2。i结点的左右子结点下标分别为2*i+1和2*i+2。
(注:如果根结点是从1开始,则左右孩子结点分别是2i和2i+1。)
如第0个结点左右子结点下标分别为1和2。
如最大化堆如下:

左图为其存储结构,右图为其逻辑结构。
堆排序的实现
实现堆排序需要解决两个问题:
1.如何由一个无序序列建成一个堆?
2.如何在输出堆顶元素之后,调整剩余元素成为一个新的堆?
先考虑第二个问题,一般在输出堆顶元素之后,视为将这个元素排除,然后用表中最后一个元素填补它的位置,自上向下进行调整:首先将堆顶元素和它的左右子树的根结点进行比较,把最小的元素交换到堆顶;然后顺着被破坏的路径一路调整下去,直至叶子结点,就得到新的堆。
我们称这个自堆顶至叶子的调整过程为“筛选”。
从无序序列建立堆的过程就是一个反复“筛选”的过程。
构造初始堆
初始化堆的时候是对所有的非叶子结点进行筛选。
最后一个非终端元素的下标是[n/2]向下取整,所以筛选只需要从第[n/2]向下取整个元素开始,从后往前进行调整。
比如,给定一个数组,首先根据该数组元素构造一个完全二叉树。
然后从最后一个非叶子结点开始,每次都是从父结点、左孩子、右孩子中进行比较交换,交换可能会引起孩子结点不满足堆的性质,所以每次交换之后需要重新对被交换的孩子结点进行调整。
进行堆排序
有了初始堆之后就可以进行排序了。
堆排序是一种选择排序。建立的初始堆为初始的无序区。
排序开始,首先输出堆顶元素(因为它是最值),将堆顶元素和最后一个元素交换,这样,第n个位置(即最后一个位置)作为有序区,前n-1个位置仍是无序区,对无序区进行调整,得到堆之后,再交换堆顶和最后一个元素,这样有序区长度变为2。。。
不断进行此操作,将剩下的元素重新调整为堆,然后输出堆顶元素到有序区。每次交换都导致无序区-1,有序区+1。不断重复此过程直到有序区长度增长为n-1,排序完成。
堆排序实例
首先,建立初始的堆结构如图:

然后,交换堆顶的元素和最后一个元素,此时最后一个位置作为有序区(有序区显示为黄色),然后进行其他无序区的堆调整,重新得到大顶堆后,交换堆顶和倒数第二个元素的位置……

重复此过程:

最后,有序区扩展完成即排序完成:

由排序过程可见,若想得到升序,则建立大顶堆,若想得到降序,则建立小顶堆。
代码
假设排列的元素为整型,且元素的关键字为其本身。
因为要进行升序排列,所以用大顶堆。
根结点从0开始,所以i结点的左右孩子结点的下标为2i+1和2i+2。
堆排序分析
堆排序方法对记录数较少的文件并不值得提倡,但对n较大的文件还是很有效的。因为其运行时间主要耗费在建初始堆和调整建新堆时进行的反复“筛选”上。
堆排序在最坏的情况下,其时间复杂度也为O(nlogn)。相对于快速排序来说,这是堆排序的最大优点。此外,堆排序仅需一个记录大小的供交换用的辅助存储空间。
查百万数据查询几种方法:第一种:
经过测试 在USERID上建立聚集索引 是这样DBCC DROPCLEANBUFFERS DBCC FREEPROCCACHESET STATISTICS IO ONSET STATISTICS TIME ONselect * from csdn where userid='yudannm1'--set statistics time off/* SQL Server 执行时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。userid password email------------------------------------------------------------------------------------------------------------------------------------------------------
yudannm1 yudannm11 490219906@qq.com(1 行受影响)表 'csdn'。扫描计数 1,逻辑读取 4 次,物理读取 4 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 SQL Server 执行时间: CPU 时间 = 16 毫秒,占用时间 = 28 毫秒。*/第二种:
几种方法, 供你参考:
1. 设置行版本控制级别, 防止堵塞;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED ;SELECT * FROM TABLE_NAME ;COMMIT ;第三种:
使用索引引擎。
第四种:
用算法与数据库结合。
- 百万数据进行查询与排序
- 百万数据查询优化
- 百万数据查询优化
- 百万数据查询优化
- 百万数据查询优化
- 百万数据查询优化
- 百万数据查询优化
- 百万数据查询优化法则
- 百万条数据查询优化
- SQL 百万数据查询优化
- 百万数据查询优化技巧
- 查询百万级条数据
- 根据需求对数据中查询的数据进行排序
- sql查询一些数据进行正序排序,除外的数据进行倒序排序
- 百万数据查询优化技巧三十则
- 百万数据查询优化技巧三十则
- 百万数据查询优化技巧三十则
- 百万数据查询优化技巧三十则
- windows端ftp服务端和客户端配置
- 数据结构-AVL树
- 早起21天
- Canvas---七巧板
- Aizu
- 百万数据进行查询与排序
- 请假管理系统
- poj3692 Kindergarten
- 了解Java并学会创建Java项目(一个菜鸟的成长历程)
- A,B,C类地址
- hibernate属性集合为组件
- 分组背包
- django1.11.4 从mysql中同步已存在的表,自动创建models
- Gym


