Core ML 和 Vision: iOS 机器学习教程
来源:互联网 发布:java 1秒等于多少毫秒 编辑:程序博客网 时间:2024/05/24 00:06
原文:Core ML and Vision: Machine Learning in iOS 11 Tutorial
作者:Audrey Tam
译者:kmyhy注意:本教程需要 Xcode 9 Beta 1 以上,SWift 4 和 iOS 11。
机器学习风头正旺。许多人听说过它,但了解得并不多。
在本教程中,将教你使用 Core ML 和 Vision,这是 iOS 11 中出现的两个全新框架。
最重要的是,你将学习如何使用新的 API 以及 Places205-GoogLeNet 模型来识别图片中的场景。
开始
从这里下载开始项目。其中已经包含了一个用于显示用户从照片库中挑选出的图片的 UI。你可以把精力集中在 app 的机器学习和视觉方面。
Build & run,你会看到一张城市夜景照片和一个按钮:

从照片库中选择其它图片。这个开始项目的 Info.plist 已经添加了 Privacy – Photo Library Usage Description,因此可能会弹出请求授权的窗口。
在图片和按钮之间有一片空白,这里有一个 Label,用于显示对图片中所示场景进行模型识别的结果。
iOS 机器学习
机器学习是一种人工智能技术,计算机不需要经过显示的编程就能够学会一些东西。和进行算法编码不同,机器学习工具能够让计算机发现并提炼出算法,通过在海量数据中查找出模式。
深度学习
从上世纪 50 年代开始,AI 专家发现了许多机器学习的方法。苹果的 Core ML 框架支持神经网络,tree ensembles,支持向量机、广义线性模型、特征工程和管道模型。但是神经网络自从 Google 2012 年用 YouTube 视频训练 AI 识别猫和人开始,创造了一系列显著的成果。而在 5 年之后,Google 赞助了一次识别 5000 种动植物的比赛。Siri 和 Alexa 之类的 app 的出现也得归功于神经网络。
神经网络通过将多层级的节点以不同方式连接在一起,来模拟人类大脑进行处理的过程。每增加一层都需要增加大量的计算能力:Inception v3,一个对象识别模型,拥有 48 层接近 20,000,000 的参数。计算基本上矩阵乘法,GPU 处理起来非常高效。GPU 成本的下降导致人们能够创建多层深度神经网络,也就是所谓的深度学习。

神经网络需要大量的训练数据,最理想的情况是全面模拟各种可能性。用户数据的爆发导致了机器学习焕发生机。
训练模型意味着用训练数据提供给神经网络,让它计算出一个通过输入产生输出的公式。训练是离线的,通常是在一个拥有多 GPU 的机器上进行。
要使用这个模型,只需要给它一个输入,它就会计算出输出:这叫推断。推断也需要大量计算,才能从新的输入计算出输出。通过 Metal 这样的框架,可以在便携式设备上进行推断。
在教程最后你会看到,深度学习远远还未达到完美。因为很难构造真正有代表性的训练数据,而且很容易出现过度训练,这会导致一些罕见特性被放大。
苹果做了些什么?
苹果从 iOS 5 开始引入 NSLinguisticTagger 用于分析神经语言。在 iOS 8 中又出现了 Metal,Metal 提供了对 GPU 底层进行访问的能力。
去年,苹果在 Accelerate 框架中加入了基本神经网络子例程(BNNS),使得开发者能够创建用于推断(不是训练)的神经网络。
今年,苹果推出了 Core ML 和 Vision!
Core ML 使得在你的 app 中使用训练模型更加容易。
Vision 允许你轻松访问到苹果的面部识别、面部特征、文本、矩形、条形码和对象模型。
你可以任何图像分析 Core ML 模型封装成 Vision 模型,这正是本教程中要做的。因为这两个框架是内置在 Metal 中的,它们高效运行在设备上,因此你并不需要将用户数据发送给服务器。
集成 Core ML
本教程使用 Places205-GoogLeNet 模型,你可以去苹果的机器学习网页,找到 Working with Models, 下载第一个。在这页面中还有另外 3 个模型,那是用于检测照片中其它对象比如树、动物和人的。
注意:如果你有用兼容的机器学习工具比如 Caffe、Keras 或者 scikit-learn 做出的其它训练模型,这篇文章“将训练模型转变为 Core ML会告诉你如何将它转换为 Core ML 格式。
添加模型
下完 GoogLeNetPlaces.mlmodel,将它从 Finder拖进项目导航器的 Resource 文件组。
选中这个文件,稍等一小会。当 Xcode 生成模型类完成之后,会出现一个箭头:
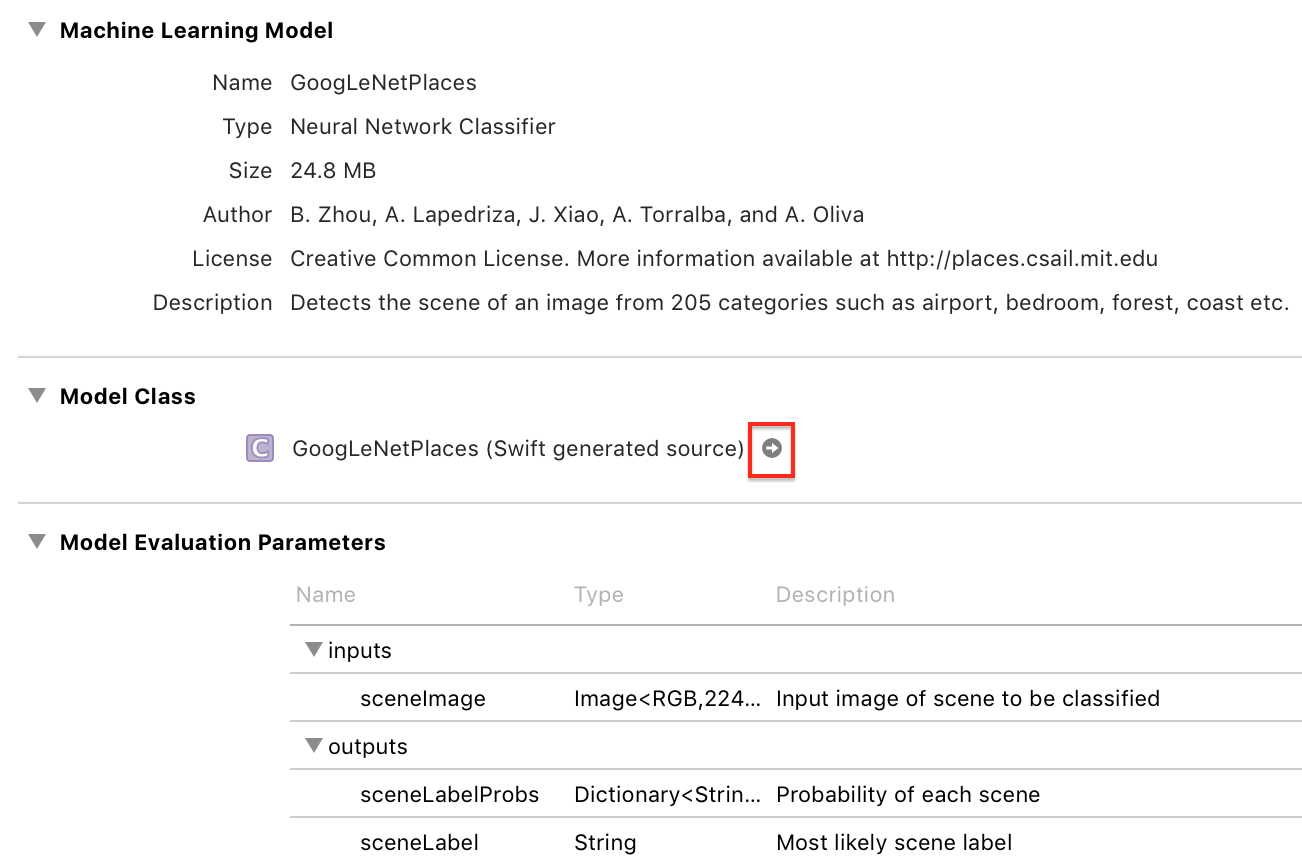
点击这个箭头,查看生成的类:

Xcode 会生成输入和输出类,以及一个 model 属性和两个 prediction 方法的主类 GoogLeNetPlaces。
GoogLeNetPlacesInput 有一个 sceneImage 属性,类型是 CVPixelBuffer。齐声惊呼:这是什么鬼?。别担心,Vision 框架会为你将我们熟悉的图片格式转换为正确的输入类型:]
Vision 框架还会将 GoogLeNetPlacesOutput 属性转换成它自己的结果类型,并负责调用 predition 方法,因此抛开这些自动生成的代码,你的代码只会和 model 属性打交道。
将 Core ML 模型封装成 Vision 模型
终于开始编写代码了!打开 ViewController.swift,导入两个框架:
import CoreMLimport Vision然后,在 IBActions 扩展后添加新扩展:
// MARK: - Methodsextension ViewController { func detectScene(image: CIImage) { answerLabel.text = "detecting scene..." // Load the ML model through its generated class guard let model = try? VNCoreMLModel(for: GoogLeNetPlaces().model) else { fatalError("can't load Places ML model") } }}代码解释如下:
首先,显示一段文本,告诉用户将发生什么事情。
GoogLeNetPlaces 的指定初始化方法会抛出一个错误,因此在创建实例时必须使用 try 关键字。
VNCoreMLModel 是一个简单 Core ML 模型容易,用于请求 Visio。
标准的 Vision 框架是创建模型、创建一个或多个请求,创建并执行请求 handler。现在我们只是创建模型,下一步就来创建请求。
在 detectScene(image:) 方法中添加代码:
// Create a Vision request with completion handlerlet request = VNCoreMLRequest(model: model) { [weak self] request, error in guard let results = request.results as? [VNClassificationObservation], let topResult = results.first else { fatalError("unexpected result type from VNCoreMLRequest") } // Update UI on main queue let article = (self?.vowels.contains(topResult.identifier.first!))! ? "an" : "a" DispatchQueue.main.async { [weak self] in self?.answerLabel.text = "\(Int(topResult.confidence * 100))% it's \(article) \(topResult.identifier)" }}VNCoreMLRequest 是一个图形分析请求,使用 Core ML 模型作为参数。它的完成回调中带一个 request 参数和一个错误对象。
首先判断 request.results 是否是一个 VNClassificationObservation 对象数组,当 Core ML 模型是一个分类器,而不是预测器和图像处理器的时候会返回这种类型的数组。GoogLeNetPlaces 是一个分类器,因为它只会预测一种特性:图片的场景类型。
VNClassificationObservation 有两个属性: identifier — 一个字符串 — 和 confidence — 一个 0 和 1 之间的数字 — 表示分类正确性的概率。当使用对象检测模型时,你可能是通过大于某个可信度来识别对象的,比如 30%.
然后拿到第一个结果,它的可信度是最高的,然后设置冠词为 a 或 an,这取决于 identifier 的一个字母。最后,在主线程中刷新 Label。稍后你会看到识别工作将放在主线程之外进行,因为它速度较慢。
现在是第三步:创建并执行请求回调。
在 detectScene(image:)方法最后加入代码:
// Run the Core ML GoogLeNetPlaces classifier on global dispatch queuelet handler = VNImageRequestHandler(ciImage: image)DispatchQueue.global(qos: .userInteractive).async { do { try handler.perform([request]) } catch { print(error) }}VNImageRequestHandler 是 Vision 框架中的标准请求 handler;它不针对任何特定的 Core ML 模型。我们将方法的 image 参数传递给它。然后调用它的 perform 方法运行这个 handler,将一个请求数组传递给它。当然,现在我们只有一个请求。
perform 方法会抛出一个错误,因此要用 try-catch 块包裹。
使用模型识别场景
嘘,写了好多的代码!但现在,你只需要在两个地方调用 detectScene(image:) 方法。
在 viewDidLoad() 方法最后和 imagePickerController(_:didFinishPickingMediaWithInofo:) 方法最后添加代码:
guard let ciImage = CIImage(image: image) else { fatalError("couldn't convert UIImage to CIImage")}detectScene(image: ciImage)Build & run。不一会你会看到一个分类结果:
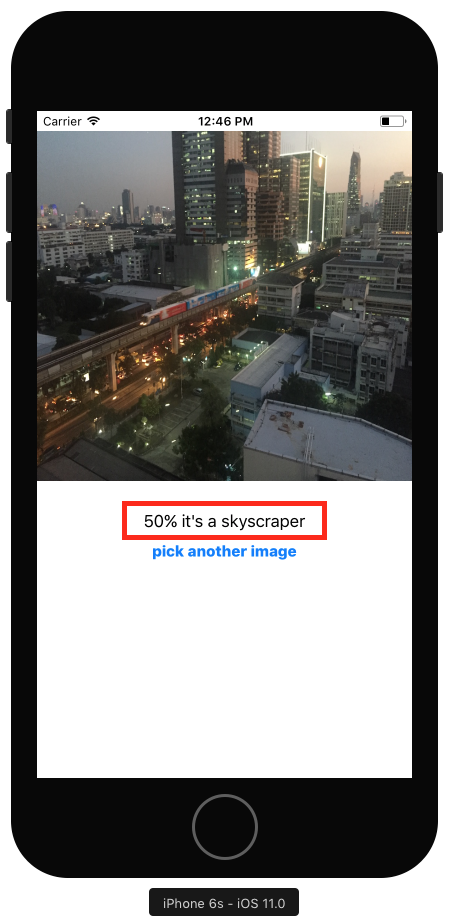
神了,图中真的有摩天大楼!还有一列列车。
点击按钮,从照片库中选择一张图片,一张阳光斑驳的树叶的特写。

嗯,还真别说,如果你眯起眼,看起来还真像是小丑鱼或小渔船在游动?但有一点是确认的,a 和 an 是对的。
苹果 Core ML 示例 app
本教程的 demo 和“WWDC 2017 会议视频 506 Vision 框架:Building on Core ML”的 demo 项目 类似。这个 Vision + ML Example app 使用的是 MNINST 分类器,它用于识别手写数字——对于邮政自动分拣非常有用。它同样使用了原生 Vision 框架的 VNDetectRectangleRequest 方法,并调用 Core Image 去矫正矩形的透视。
你可以从 Core ML 文档页 下载其它示例项目。MarsHabitatPricePredictor 模型的输入只能是数字,因此可以直接调用生成的 MarsHabitatPricer 方法和属性,而不用将模型封装成 Vision 模型。一次只修改一个参数,这样就很容易看到这个模型是一个线性回归:
137 * solarPanels + 653.50 * greenHouses + 5854 * acres结尾
你可以从这里下载完成项目。如果模型显示为不存在,请替换成你下载的模型。
你现在已经掌握如何在项目中集成已有模型了。
更多内容,请参考:
- 苹果的 Core ML 框架文档
- WWDC 2017 会议视频 703:介绍 Core ML
- WWDC 2017 会议视频 710:深入 Core ML
以及 2016 年:
- WWDC 2016 会议视频 605 What’s New in Metal, Part 2: demos show how fast the app does the Inception model classification calculations 感谢 Metal。
- 苹果的基本神经网络子例程文档
想创建自己的模型?这已经大大超出本文的范畴了(以及我的专业水平)。你可以参考下列资源:
- RWDevCon 2017 会议视频 3 iOS 中的机器学习: Alexis Gallagher 做了一件很了不起的事情,教你如何采集某个神经网络所需的训练数据(你微笑或者皱眉头的视频),然后检查它是否运行良好(或者相反)。他得出了结论:除了数学家和大公司之外,你也可以构建实用的模型。
- 苹果AI 科研论文中的 Quartz 文章:Dave Gershgorn 的关于 AI 的文章非常清晰透彻。这篇文章做了一件非常棒的事情,总结了苹果的第一个 AI 科研论文: 研究者用训练神经网络去通过真实图片来生成合成图片,同时高效低生成了海量的优质训练数据,从而避免个人数据隐私问题。
最后,我也从 Andreessen Horowitz 公司的 Frank Chen 写的这篇AI 简史中获益良多:AI 和深度学习 a16z 播客。
希望本文对你有所帮助。请在下面留言!
- Core ML 和 Vision: iOS 机器学习教程
- Core ML 与 Vision:iOS 11 机器学习教程
- Core ML 与 Vision:iOS 11 机器学习教程
- Core ML 与 Vision:iOS 11 机器学习教程
- Core ML 与 Vision:iOS 11 机器学习教程
- Core ML 与 Vision:iOS 11 机器学习教程
- Core ML and Vision
- Core ML介绍 (Apple机器学习框架)
- 手把手教你在应用里用上iOS机器学习框架Core ML
- ios 11 CORE ML 学习入门
- Core ML学习
- CoreML 机器学习 VISION
- 机器学习ML简史
- 机器学习ML策略
- 隐马尔可夫链-机器学习ML
- PHP-ML 学习/机器学习和PHP的神经网络
- == 人工智能和机器学习 AI&ML ==
- 机器学习和PHP的神经网络:PHP-ML库
- ugly number & ugly numberii
- Android的Webview中H5支付调起微信支付
- 【已解决】IOError: [Errno socket error] [SSL: UNKNOWN_PROTOCOL] unknown protocol (_ssl.c:590)
- 2. Spring Boot返回json数据【从零开始学Spring Boot
- NYOJ 42-一笔画问题
- Core ML 和 Vision: iOS 机器学习教程
- sap CAD桌面集成 CDESK增强
- C++类和对象总结
- HDUOJ 2066 一个人的旅行(dijkstra算法)
- UI 一一 自定义等高cell (纯代码-Frame)方式
- 微信小程序 wx:key详细介绍
- MindManager安装环境
- 【PRML】—— 共轭分布
- /usr/bin/ld: cannot open output file a.out: Permission denied,解决办法在最后


