聚簇索引与非聚簇索引的区别
来源:互联网 发布:淘宝买家信用 编辑:程序博客网 时间:2024/05/16 17:50
通常情况下,建立索引是加快查询速度的有效手段,但是索引不是万能的,仅仅依赖索引并不能实现对所有数据的快速存取。事实上,如果索引策略与数据检索需求严重不符的话,建立索引反而会降低查询性能。因此在实际使用当中,应当充分考虑索引的开销,包括磁盘空间的开销及处理开销(如:资源开销与加锁)。例如,数据如果频繁的跟新或删加,就不宜建立索引。
本文简要讨论一下聚簇索引的特点及其与非聚簇索引的区别。
(1)定义
聚簇索引的顺序就是数据的物理存储顺序,即表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致;
非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。
(2)索引底层实现结构是B+树,二叉树的一种;
聚簇索引:索引的叶节点就是数据节点(索引值),对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。
而非聚簇索引的叶节点仍然是索引节点(告诉你怎么在表中查找这一记录),只不过有一个指针指向对应的数据块。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。如下图(原图请见http://www.jb51.NET/article/29693.htm):
(3)建立索引:
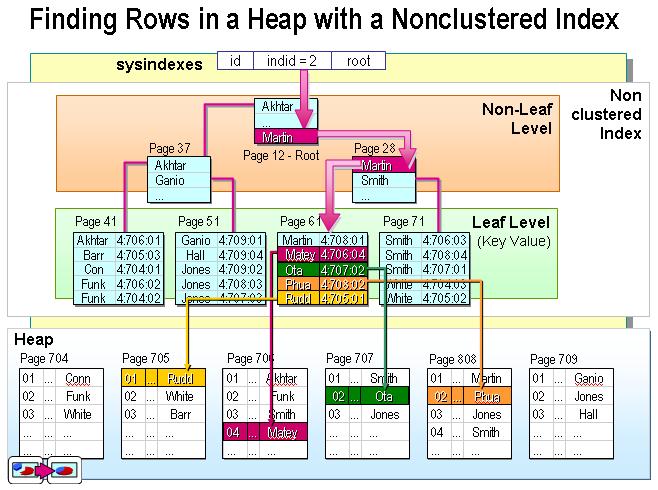
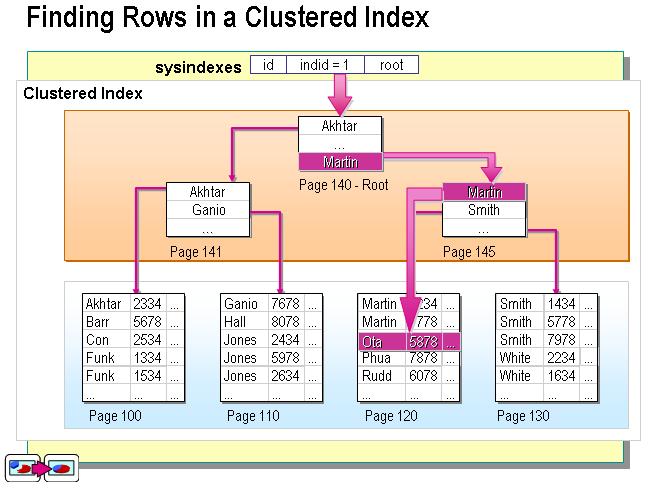
索引快的原因:
大家都知道,索引可以提高检索效率,因为它的二叉树结构以及占用空间小,所以访问速度块。让我们来算一道数学题:如果表中的一条记录在磁盘上占用 1000字节的话,我们对其中10字节的一个字段建立索引,那么该记录对应的索引块的大小只有10字节。我们知道,SQL Server的最小空间分配单元是“页(Page)”,一个页在磁盘上占用8K空间,那么这一个页可以存储上述记录8条,但可以存储索引800条。现在我 们要从一个有8000条记录的表中检索符合某个条件的记录,如果没有索引的话,我们可能需要遍历8000条×1000字节/8K字节=1000个页面(数据块)才能 够找到结果。如果在检索字段上有上述索引的话,那么我们可以在8000条×10字节/8K字节=10个页面(索引快)中就检索到满足条件的索引块,然后根据索引块上 的指针逐一找到结果数据块,这样IO访问量要少的多。
索引优化技术
是不是有索引就一定检索的快呢?答案是否。有些时候用索引还不如不用索引快。比如说我们要检索上述表中的所有记录,如果不用索引,需要访问8000 条×1000字节/8K字节=1000个页面,如果使用索引的话,首先检索索引,访问8000条×10字节/8K字节=10个页面得到索引检索结果,再根 据索引检索结果去对应数据页面,由于是检索所有数据(B+树查询是从根节点到子节点遍历一遍的,所以需要检索所有数据),所以需要再访问8000条×1000字节/8K字节=1000个页面将全部数据读取出来,一共访问了 1010个页面,这显然不如不用索引快。
索引对应的SQL语句
(1)为student表的sno列创建非聚簇索引
use db1
create index IX_Stu_Sno on Student(sno)
(2)为student表的sno列创建唯一的聚簇索引
use db1
create unique clustered index IX_Stu_Sno1 on Student(sno)
总结索引使用场景:
1:不要索引数据量不大的表,对于小表来讲,表扫描的成本并不高。2:不要设置过多的索引,在没有聚集索引的表中,最大可以设置249个非聚集索引,过多的索引首先会带来更大的磁盘空间,而且在数据发生修改时,对索引的维护是特别消耗性能的。
3:合理应用复合索引,有某些情况下可以考虑创建包含所有输出列的覆盖索引。
4:对经常使用范围查询的字段,可能考虑聚集索引。
5:避免对不常用的列,逻辑性列,大字段列创建索引。
- MySQL索引:聚簇索引与非聚簇索引的区别
- MySQL索引:聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的语义区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 聚簇索引与非聚簇索引的区别
- 买单侠微服务的API网关演化之路
- Android 7.0 ActivityManagerService(1) AMS的启动过程
- HDU 6070 Dirt Ratio【分数规划】【线段树】
- Apache Torque连接多个数据库及其使用
- hdu 3292 佩尔方程一系列操作
- 聚簇索引与非聚簇索引的区别
- Bootstrap框架 模态框插件 禁止点击空白处关闭模态框事件
- iOS上传应用到蒲公英分发测试
- 初学JAVA02
- 【phantomjs系列】Phantomjs Api介绍
- 在 Ubuntu16.04 上安装 OpenCV3.2.0
- Android ActionBar完全解析,使用官方推荐的最佳导航栏(下)
- 全排列的实现
- memcpy


