激活函数
来源:互联网 发布:python 链接数据库 编辑:程序博客网 时间:2024/04/30 00:51
激活函数的作用
在神经网络中,激活函数的作用是能够给神经网络加入一些非线性因素,使得神经网络可以更好地解决较为复杂的问题,能够把输入的特征保留并映射下来。
激活函数(Activation Function)的特点:
- 非线性: 当激活函数是线性的时候,一个两层的神经网络就可以逼近基本上所有的函数了。
- 可微: 当优化方法是基于梯度的时候,这个性质是必须的。
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
- f(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是random的很小的值,那么神经网络的训练将会很高效。
- 输出值范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的学习率。
激活函数(Activation Function):
激活函数是用来加入非线性因素的,因为线性模型的表达力不够 ,,因为神经网络的数学基础是处处可微的,所以选取的激活函数要能保证数据输入与输出也是可微的,运算特征是不断进行循环计算,所以在每代循环过程中,每个神经元的值也是在不断变化的。
这就导致了tanh特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果显示出来,但有是,在特征相差比较复杂或是相差不是特别大时,需要更细微的分类判断的时候,sigmoid效果就好了。
常用的激活函数
SigmoidTanhReLULeaky ReLUMaxout
Sigmoid
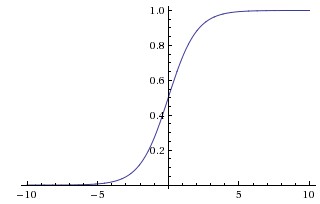
Sigmoid 的数学形式:
simoid 函数也称 S 曲线:simoid函数也称S曲线:
优点:
1.Sigmoid函数的输出映射在(0,1)之间,单调连续,输出范围有限,优化稳定,可以用作输出层。
2.求导容易。
缺点:
1.由于其软饱和性,容易产生梯度消失,导致训练出现问题。
2.其输出并不是以0为中心的。
历史上,sigmoid 函数曾非常常用,然而现在它已经不太受欢迎,实际很少使用了,因为它主要有两个缺点:
1. 函数饱和使梯度消失
sigmoid 神经元在值为 0 或 1 的时候接近饱和,这些区域,梯度几乎为 0。因此在反向传播时,这个局部梯度会与整个代价函数关于该单元输出的梯度相乘,结果也会接近为 0 。
这样,几乎就没有信号通过神经元传到权重再到数据了,因此这时梯度就对模型的更新没有任何贡献。
除此之外,为了防止饱和,必须对于权重矩阵的初始化特别留意。比如,如果初始化权重过大,那么大多数神经元将会饱和,导致网络就几乎不学习。
2. sigmoid 函数不是关于原点中心对称的
这个特性会导致后面网络层的输入也不是零中心的,进而影响梯度下降的运作。
因为如果输入都是正数的话(如 中每个元素都 ),那么关于 的梯度在反向传播过程中,要么全是正数,要么全是负数(具体依据整个表达式 而定),这将会导致梯度下降权重更新时出现 z 字型的下降。
当然,如果是按 batch 去训练,那么每个 batch 可能得到不同的信号,整个批量的梯度加起来后可以缓解这个问题。因此,该问题相对于上面的神经元饱和问题来说只是个小麻烦,没有那么严重。
tanh
tanh 函数同样存在饱和问题,但它的输出是零中心的,因此实际中 tanh 比 sigmoid 更受欢迎。
##### tanh 的数学形式:
现在,比起Sigmoid函数我们通常更倾向于tanh函数。tanh函数被定义为
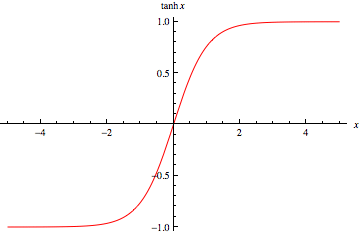
tanh 函数实际上是一个放大的 sigmoid 函数
优点:
1.比Sigmoid函数收敛速度更快。
2.相比Sigmoid函数,其输出以0为中心。
缺点:
还是没有改变Sigmoid函数的最大问题——由于饱和性产生的梯度消失。
ReLU
ReLU 的数学形式:
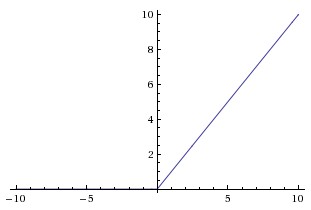
ReLU 的优点:
1.相较于
sigmoid 和 tanh 函数,ReLU 对于 SGD 的收敛有巨大的加速作用(Alex Krizhevsky 指出有 6 倍之多)。有人认为这是由它的线性、非饱和的公式导致的。 相比于 sigmoid/tanh,ReLU 只需要一个阈值就可以得到激活值,而不用去算一大堆复杂的(指数)运算。
2.ReLU 的缺点是,它在训练时比较脆弱并且可能“死掉”。
举例来说:一个非常大的梯度经过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了。如果这种情况发生,那么从此所有流过这个神经元的梯度将都变成 0。
也就是说,这个 ReLU 单元在训练中将不可逆转的死亡,导致了数据多样化的丢失。实际中,如果学习率设置得太高,可能会发现网络中 40% 的神经元都会死掉(在整个训练集中这些神经元都不会被激活)。
合理设置学习率,会降低这种情况的发生概率。
3.Sigmoid和tanh涉及了很多很expensive的操作(比如指数),ReLU可以更加简单的实现。
4.有效缓解了梯度消失的问题。
5.在没有无监督预训练的时候也能有较好的表现。
Leaky ReLU
Leaky ReLU 是为解决“ ReLU 死亡”问题的尝试。
ReLU 中当 x<0 时,函数值为 0。而 Leaky ReLU 则是给出一个很小的负数梯度值,比如 0.01。 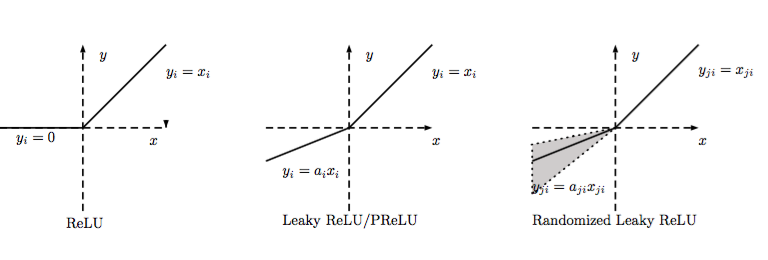
通常在LReLU和PReLU中,我们定义一个激活函数为
有些研究者的论文指出这个激活函数表现很不错,但是其效果并不是很稳定,
Kaiming He 等人在 2015 年发布的论文 Delving Deep into Rectifiers 中介绍了一种新方法PReLU,把负区间上的斜率当做每个神经元中的一个参数来训练。然而该激活函数在在不同任务中表现的效果也没有特别清晰。
PReLU
PReLU是LReLU的改进,可以自适应地从数据中学习参数。PReLU具有收敛速度快、错误率低的特点。PReLU可以用于反向传播的训练,可以与其他层同时优化 .
在测试中是固定的。RReLU在一定程度上能起到正则效果.
Softplus与Softsign
优点:
1.ELU减少了正常梯度与单位自然梯度之间的差距,从而加快了学习。
2.在负的限制条件下能够更有鲁棒性。
Softplus与Softsign
Softplus被定义为
Softsign被定义为
Maxout
Maxout 是对 ReLU 和 Leaky ReLU 的一般化归纳,它的函数公式是(二维时):。ReLU 和 Leaky ReLU 都是这个公式的特殊情况(比如 ReLU 就是当 时)。
这样 Maxout 神经元就拥有 ReLU 单元的所有优点(线性和不饱和),而没有它的缺点(死亡的ReLU单元)。然而和 ReLU 对比,它每个神经元的参数数量增加了一倍,这就导致整体参数的数量激增。
如何选择激活函数?
通常来说,很少会把各种激活函数串起来在一个网络中使用的。
如果使用 ReLU,那么一定要小心设置 learning rate,而且要注意不要让你的网络出现很多 “dead” 神经元,如果这个问题不好解决,那么可以试试 Leaky ReLU、PReLU 或者 Maxout.
最好不要用 sigmoid,可以试试 tanh,不过可以预期它的效果会比不上 ReLU 和 Maxout.
参考
常用激活函数的总结与比较 https://livc.io/176
激活函数Sigmoid/Tanh/ReLU http://blog.csdn.net/zchang81/article/details/70224688
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 激活函数
- 损失函数+激活函数
- 13.3节 交换操作练习
- MySQL索引以及优化
- Java8源码-Map整体架构
- 字符串匹配-Sunday算法
- 创建oracle自增序列
- 激活函数
- github文件托管简单步骤整理
- 在ios上面点击失效的问题
- FileUpLoad组件工作流程
- 优先队列详解
- Android布局中的空格以及占一个汉字宽度的空格的实现
- JavaScript Date 对象
- [caioj 1480,利用矩阵乘法解决的经典题目二]矩阵无限方
- java开发环境配置


