与 Hadoop 对比,如何看待 Spark 技术?
来源:互联网 发布:网络直销平台有哪些 编辑:程序博客网 时间:2024/06/05 03:49
转自:https://www.zhihu.com/question/26568496
与 Hadoop 对比,如何看待 Spark 技术?
75 个回答
首先看一下Hadoop解决了什么问题,Hadoop就是解决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的可靠存储和处理。
- HDFS,在由普通PC组成的集群上提供高可靠的文件存储,通过将块保存多个副本的办法解决服务器或硬盘坏掉的问题。
- MapReduce,通过简单的Mapper和Reducer的抽象提供一个编程模型,可以在一个由几十台上百台的PC组成的不可靠集群上并发地,分布式地处理大量的数据集,而把并发、分布式(如机器间通信)和故障恢复等计算细节隐藏起来。而Mapper和Reducer的抽象,又是各种各样的复杂数据处理都可以分解为的基本元素。这样,复杂的数据处理可以分解为由多个Job(包含一个Mapper和一个Reducer)组成的有向无环图(DAG),然后每个Mapper和Reducer放到Hadoop集群上执行,就可以得出结果。
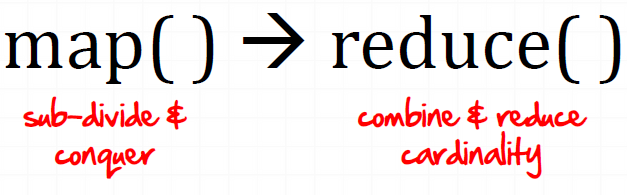
(图片来源:http://www.slideshare.net/davidengfer/intro-to-the-hadoop-stack-javamug)
用MapReduce统计一个文本文件中单词出现的频率的示例WordCount请参见:WordCount - Hadoop Wiki,如果对MapReduce不恨熟悉,通过该示例对MapReduce进行一些了解对理解下文有帮助。
在MapReduce中,Shuffle是一个非常重要的过程,正是有了看不见的Shuffle过程,才可以使在MapReduce之上写数据处理的开发者完全感知不到分布式和并发的存在。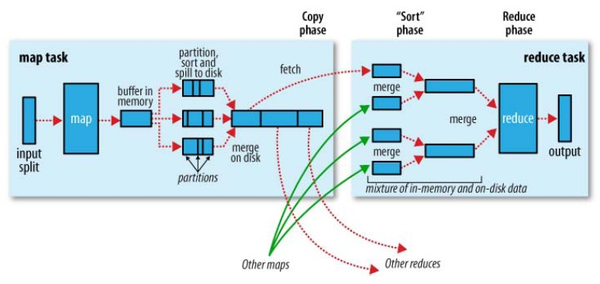
(图片来源: Hadoop Definitive Guide By Tom White)
广义的Shuffle是指图中在Map和Reuce之间的一系列过程。
但是,MapRecue存在以下局限,使用起来比较困难。
- 抽象层次低,需要手工编写代码来完成,使用上难以上手。
- 只提供两个操作,Map和Reduce,表达力欠缺。
- 一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的。
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- 中间结果也放在HDFS文件系统中
- ReduceTask需要等待所有MapTask都完成后才可以开始
- 时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
- 对于迭代式数据处理性能比较差
比如说,用MapReduce实现两个表的Join都是一个很有技巧性的过程,如下图所示:
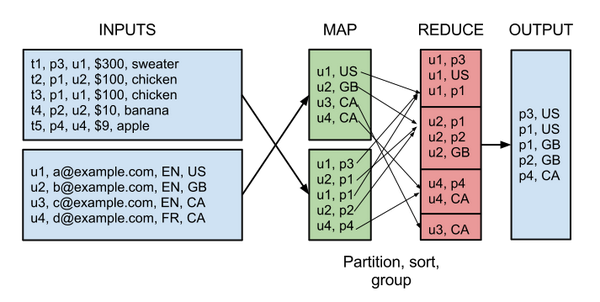
(图片来源:Real World Hadoop)
因此,在Hadoop推出之后,出现了很多相关的技术对其中的局限进行改进,如Pig,Cascading,JAQL,OOzie,Tez,Spark等。
Apache PigApache Pig也是Hadoop框架中的一部分,Pig提供类SQL语言(Pig Latin)通过MapReduce来处理大规模半结构化数据。而Pig Latin是更高级的过程语言,通过将MapReduce中的设计模式抽象为操作,如Filter,GroupBy,Join,OrderBy,由这些操作组成有向无环图(DAG)。例如如下程序:
visits = load ‘/data/visits’ as (user, url, time);gVisits = group visits by url;visitCounts = foreach gVisits generate url, count(visits);urlInfo = load ‘/data/urlInfo’ as (url, category, pRank);visitCounts = join visitCounts by url, urlInfo by url;gCategories = group visitCounts by category;topUrls = foreach gCategories generate top(visitCounts,10);store topUrls into ‘/data/topUrls’;描述了数据处理的整个过程。
而Pig Latin又是通过编译为MapReduce,在Hadoop集群上执行的。上述程序被编译成MapReduce时,会产生如下图所示的Map和Reduce: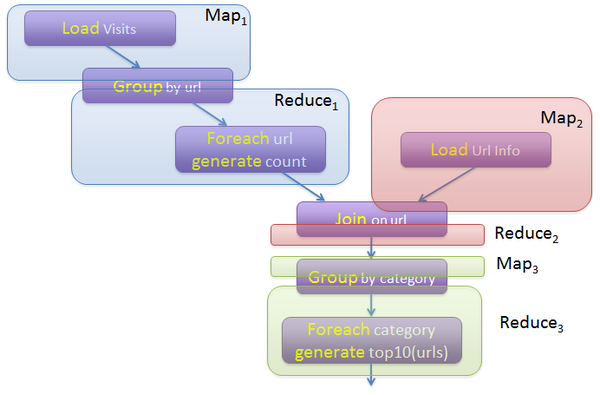
(图片来源:http://cs.nyu.edu/courses/Fall12/CSCI-GA.2434-001/sigmod08-pig-latin.ppt)
Apache Pig解决了MapReduce存在的大量手写代码,语义隐藏,提供操作种类少的问题。类似的项目还有Cascading,JAQL等。
Apache Tez
Apache Tez,Tez是HortonWorks的Stinger Initiative的的一部分。作为执行引擎,Tez也提供了有向无环图(DAG),DAG由顶点(Vertex)和边(Edge)组成,Edge是对数据的移动的抽象,提供了One-To-One,BroadCast,和Scatter-Gather三种类型,只有Scatter-Gather才需要进行Shuffle。
SELECT a.state, COUNT(*),AVERAGE(c.price)FROM aJOIN b ON (a.id = b.id)JOIN c ON (a.itemId = c.itemId)GROUP BY a.state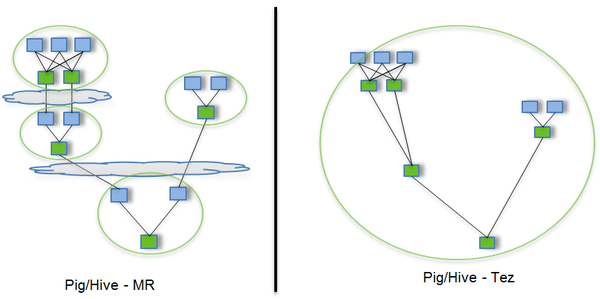 (图片来源:http://www.slideshare.net/hortonworks/apache-tez-accelerating-hadoop-query-processing)
(图片来源:http://www.slideshare.net/hortonworks/apache-tez-accelerating-hadoop-query-processing)途中蓝色方块表示Map,绿色方块表示Reduce,云状表示写屏障(write barrier,一种内核机制,可以理解为持久的写),Tez的优化主要体现在:
- 去除了连续两个作业之间的写屏障
- 去除了每个工作流中多余的Map阶段(Stage)
通过提供DAG语义和操作,提供了整体的逻辑,通过减少不必要的操作,Tez提升了数据处理的执行性能。
Apache Spark
Apache Spark是一个新兴的大数据处理的引擎,主要特点是提供了一个集群的分布式内存抽象,以支持需要工作集的应用。
这个抽象就是RDD(Resilient Distributed Dataset),RDD就是一个不可变的带分区的记录集合,RDD也是Spark中的编程模型。Spark提供了RDD上的两类操作,转换和动作。转换是用来定义一个新的RDD,包括map, flatMap, filter, union, sample, join, groupByKey, cogroup, ReduceByKey, cros, sortByKey, mapValues等,动作是返回一个结果,包括collect, reduce, count, save, lookupKey。
Spark的API非常简单易用,Spark的WordCount的示例如下所示:val spark = new SparkContext(master, appName, [sparkHome], [jars])val file = spark.textFile("hdfs://...")val counts = file.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _)counts.saveAsTextFile("hdfs://...")其中的file是根据HDFS上的文件创建的RDD,后面的flatMap,map,reduceByKe都创建出一个新的RDD,一个简短的程序就能够执行很多个转换和动作。
在Spark中,所有RDD的转换都是是惰性求值的。RDD的转换操作会生成新的RDD,新的RDD的数据依赖于原来的RDD的数据,每个RDD又包含多个分区。那么一段程序实际上就构造了一个由相互依赖的多个RDD组成的有向无环图(DAG)。并通过在RDD上执行动作将这个有向无环图作为一个Job提交给Spark执行。
例如,上面的WordCount程序就会生成如下的DAGscala> counts.toDebugStringres0: String =MapPartitionsRDD[7] at reduceByKey at <console>:14 (1 partitions) ShuffledRDD[6] at reduceByKey at <console>:14 (1 partitions) MapPartitionsRDD[5] at reduceByKey at <console>:14 (1 partitions) MappedRDD[4] at map at <console>:14 (1 partitions) FlatMappedRDD[3] at flatMap at <console>:14 (1 partitions) MappedRDD[1] at textFile at <console>:12 (1 partitions) HadoopRDD[0] at textFile at <console>:12 (1 partitions)Spark对于有向无环图Job进行调度,确定阶段(Stage),分区(Partition),流水线(Pipeline),任务(Task)和缓存(Cache),进行优化,并在Spark集群上运行Job。RDD之间的依赖分为宽依赖(依赖多个分区)和窄依赖(只依赖一个分区),在确定阶段时,需要根据宽依赖划分阶段。根据分区划分任务。
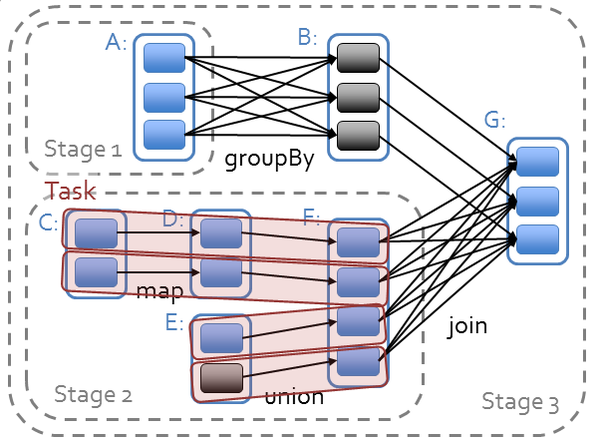
(图片来源:https://databricks-training.s3.amazonaws.com/slides/advanced-spark-training.pdf)
Spark支持故障恢复的方式也不同,提供两种方式,Linage,通过数据的血缘关系,再执行一遍前面的处理,Checkpoint,将数据集存储到持久存储中。
Spark为迭代式数据处理提供更好的支持。每次迭代的数据可以保存在内存中,而不是写入文件。
Spark的性能相比Hadoop有很大提升,2014年10月,Spark完成了一个Daytona Gray类别的Sort Benchmark测试,排序完全是在磁盘上进行的,与Hadoop之前的测试的对比结果如表格所示: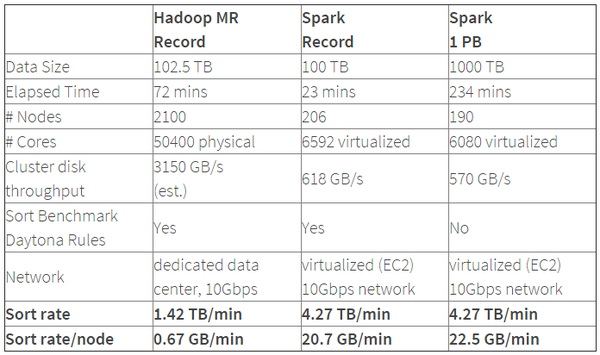
(表格来源: Spark officially sets a new record in large-scale sorting)
从表格中可以看出排序100TB的数据(1万亿条数据),Spark只用了Hadoop所用1/10的计算资源,耗时只有Hadoop的1/3。
Spark的优势不仅体现在性能提升上的,Spark框架为批处理(Spark Core),交互式(Spark SQL),流式(Spark Streaming),机器学习(MLlib),图计算(GraphX)提供一个统一的数据处理平台,这相对于使用Hadoop有很大优势。
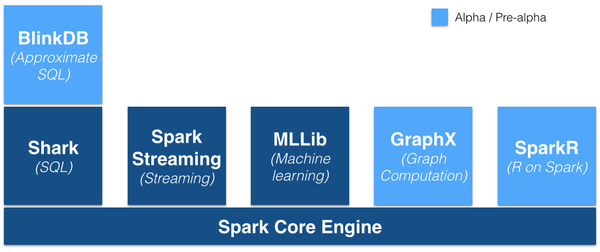
(图片来源:https://gigaom.com/2014/06/28/4-reasons-why-spark-could-jolt-hadoop-into-hyperdrive/)
按照Databricks的连城的说法是One Stack To Rule Them All
特别是在有些情况下,你需要进行一些ETL工作,然后训练一个机器学习的模型,最后进行一些查询,如果是使用Spark,你可以在一段程序中将这三部分的逻辑完成形成一个大的有向无环图(DAG),而且Spark会对大的有向无环图进行整体优化。
例如下面的程序:val points = sqlContext.sql( “SELECT latitude, longitude FROM historic_tweets”) val model = KMeans.train(points, 10) sc.twitterStream(...) .map(t => (model.closestCenter(t.location), 1)) .reduceByWindow(“5s”, _ + _)(示例来源:http://www.slideshare.net/Hadoop_Summit/building-a-unified-data-pipeline-in-apache-spark)
这段程序的第一行是用Spark SQL 查寻出了一些点,第二行是用MLlib中的K-means算法使用这些点训练了一个模型,第三行是用Spark Streaming处理流中的消息,使用了训练好的模型。
Lambda Architecture是一个大数据处理平台的参考模型,如下图所示:
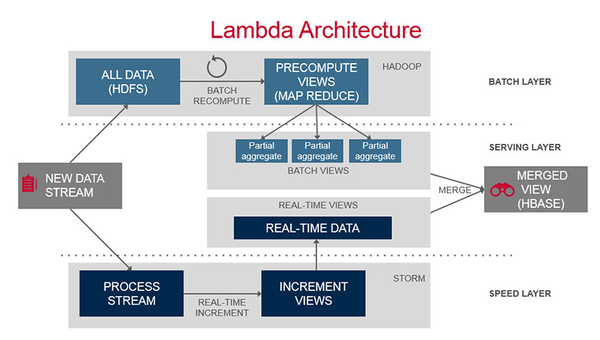
(图片来源: Lambda Architecture)
其中包含3层,Batch Layer,Speed Layer和Serving Layer,由于Batch Layer和Speed Layer的数据处理逻辑是一致的,如果用Hadoop作为Batch Layer,而用Storm作为Speed Layer,你需要维护两份使用不同技术的代码。
- Batch Layer,HDFS+Spark Core,将实时的增量数据追加到HDFS中,使用Spark Core批量处理全量数据,生成全量数据的视图。,
- Speed Layer,Spark Streaming来处理实时的增量数据,以较低的时延生成实时数据的视图。
- Serving Layer,HDFS+Spark SQL(也许还有BlinkDB),存储Batch Layer和Speed Layer输出的视图,提供低时延的即席查询功能,将批量数据的视图与实时数据的视图合并。
总结
如果说,MapReduce是公认的分布式数据处理的低层次抽象,类似逻辑门电路中的与门,或门和非门,那么Spark的RDD就是分布式大数据处理的高层次抽象,类似逻辑电路中的编码器或译码器等。
RDD就是一个分布式的数据集合(Collection),对这个集合的任何操作都可以像函数式编程中操作内存中的集合一样直观、简便,但集合操作的实现确是在后台分解成一系列Task发送到几十台上百台服务器组成的集群上完成的。最近新推出的大数据处理框架Apache Flink也使用数据集(Data Set)和其上的操作作为编程模型的。
由RDD组成的有向无环图(DAG)的执行是调度程序将其生成物理计划并进行优化,然后在Spark集群上执行的。Spark还提供了一个类似于MapReduce的执行引擎,该引擎更多地使用内存,而不是磁盘,得到了更好的执行性能。
那么Spark解决了Hadoop的哪些问题呢?- 抽象层次低,需要手工编写代码来完成,使用上难以上手。
- =>基于RDD的抽象,实数据处理逻辑的代码非常简短。。
- 只提供两个操作,Map和Reduce,表达力欠缺。
- =>提供很多转换和动作,很多基本操作如Join,GroupBy已经在RDD转换和动作中实现。
- 一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的。
- =>一个Job可以包含RDD的多个转换操作,在调度时可以生成多个阶段(Stage),而且如果多个map操作的RDD的分区不变,是可以放在同一个Task中进行。
- 处理逻辑隐藏在代码细节中,没有整体逻辑
- =>在Scala中,通过匿名函数和高阶函数,RDD的转换支持流式API,可以提供处理逻辑的整体视图。代码不包含具体操作的实现细节,逻辑更清晰。
- 中间结果也放在HDFS文件系统中
- =>中间结果放在内存中,内存放不下了会写入本地磁盘,而不是HDFS。
- ReduceTask需要等待所有MapTask都完成后才可以开始
- => 分区相同的转换构成流水线放在一个Task中运行,分区不同的转换需要Shuffle,被划分到不同的Stage中,需要等待前面的Stage完成后才可以开始。
- 时延高,只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够
- =>通过将流拆成小的batch提供Discretized Stream处理流数据。
- 对于迭代式数据处理性能比较差
- =>通过在内存中缓存数据,提高迭代式计算的性能。
因此,Hadoop MapReduce会被新一代的大数据处理平台替代是技术发展的趋势,而在新一代的大数据处理平台中,Spark目前得到了最广泛的认可和支持,从参加Spark Summit 2014的厂商的各种基于Spark平台进行的开发就可以看出一二。
我本人是类似Hive平台的系统工程师,我对MapReduce的熟悉程度是一般,它是我的底层框架。我隔壁组在实验Spark,想将一部分计算迁移到Spark上。
年初的时候,看Spark的评价,几乎一致表示,Spark是小数据集上处理复杂迭代的交互系统,并不擅长大数据集,也没有稳定性。但是最近的风评已经变化,尤其是14年10月他们完成了Peta sort的实验,这标志着Spark越来越接近替代Hadoop MapReduce了。
Spark the fastest open source engine for sorting a petabyte
Sort和Shuffle是MapReduce上最核心的操作之一,比如上千个Mapper之后,按照Key将数据集分发到对应的Reducer上,要走一个复杂的过程,要平衡各种因素。Spark能处理Peta sort的话,本质上已经没有什么能阻止它处理Peta级别的数据了。这差不多远超大多数公司单次Job所需要处理的数据上限了。
回到本题,来说说Hadoop和Spark。Hadoop包括Yarn和HDFS以及MapReduce,说Spark代替Hadoop应该说是代替MapReduce。
MapReduce的缺陷很多,最大的缺陷之一是Map + Reduce的模型。这个模型并不适合描述复杂的数据处理过程。很多公司(包括我们)把各种奇怪的Machine Learning计算用MR模型描述,不断挖(lan)掘(yong)MR潜力,对系统工程师和Ops也是极大挑战了。很多计算,本质上并不是一个Map,Shuffle再Reduce的结构,比如我编译一个SubQuery的SQL,每个Query都做一次Group By,我可能需要Map,Reduce+Reduce,中间不希望有无用的Map;又或者我需要Join,这对MapReduce来说简直是噩梦,什么给左右表加标签,小表用Distributed Cache分发,各种不同Join的Hack,都是因为MapReduce本身是不直接支持Join的,其实我需要的是,两组不同的计算节点扫描了数据之后按照Key分发数据到下一个阶段再计算,就这么简单的规则而已;再或者我要表示一组复杂的数据Pipeline,数据在一个无数节点组成的图上流动,而因为MapReduce的呆板模型,我必须一次一次在一个Map/Reduce步骤完成之后不必要地把数据写到磁盘上再读出,才能继续下一个节点,因为Map Reduce2个阶段完成之后,就算是一个独立计算步骤完成,必定会写到磁盘上等待下一个Map Reduce计算。
上面这些问题,算是每个号称下一代平台都尝试解决的。
现在号称次世代平台现在做的相对有前景的是Hortonworks的Tez和Databricks的Spark。他们都尝试解决了上面说的那些问题。Tez和Spark都可以很自由地描述一个Job里执行流(所谓DAG,有向无环图)。他们相对现在的MapReduce模型来说,极大的提升了对各种复杂处理的直接支持,不需要再绞尽脑汁“挖掘”MR模型的潜力。
有兴趣的童鞋可以看看这个PPT
http://www.slideshare.net/Hadoop_Summit/w-235phall1pandey
这是Hadoop峰会上Tez的材料,第九页开始有描述Hive on Tez和传统MR Hive的区别,这些区别应该也适用于MR Hive和Spark SQL,也很清楚的体现了为何MR模型很笨重。
相比Tez,Spark加入了更多内存Cache操作,但据了解它也是可以不Cache直接处理的,只是效率就会下降。
再说Programming Interface,Tez的Interface更像MapReduce,但是允许你定义各种Edge来连接不同逻辑节点。Spark则利用了Functional Programming的理念,API十分简洁,相比MR和Tez简单到令人发指。我不清楚Spark如果要表现复杂的DAG会不会也变得很麻烦,但是至少wordcount的例子看起来是这样的,大家可以比较感受下:
incubator-tez/WordCount.java at master · apache/incubator-tez · GitHub
Examples | Apache Spark
处理大规模数据而言,他们都需要更多proven cases。至少Hadoop MapReduce是被证明可行的。
作为Data Pipeline引擎来说,MapReduce每个步骤都会存盘,而Spark和Tez可以直接网络发送到下一个步骤,速度上是相差很多的,但是存盘的好处是允许继续在失败的数据上继续跑,所以直观上说MapReduce作为pipeline引擎更稳健。但理论上来说,如果选择在每个完成的小步骤上加CheckPoint,那Tez和Spark完全能和现在的MapReduce达到一样的稳健。
总结来说,即便现在不成熟,但是并没有什么阻碍他们代替现有的MapReduce Batch Process。对Tez而言,似乎商业上宣传不如Spark成功。Databricks头顶Berkley的光环,商业宣传又十分老道,阵营增长极快。光就系统设计理念,没有太大的优劣,但是商业上可能会拉开差距。Cloudera也加入了Spark阵营,以及很多其他大小公司,可以预见的是,Spark会成熟的很快,相比Tez。
但Tez对于Hortonworks来说是赢取白富美的关键,相信为了幸福他们也必须努力打磨推广tez。
所以就算现在各家试用会有种种问题,但是毕竟现在也就出现了2个看起来有戏的“次世代”平台,那慢慢试用,不断观望,逐步替换,会是大多数公司的策略。
Spark 的优点,排名第一(用心阁)的已经说得很好了
根据最近走读spark core/shuffle, core/scheduler and core/rdd 的部分代码来说说自己的感受
1. spark 是hadoop mapreduce 的不断改进,同时又兼容并包了很多数据库里面的一些基本思想来实现和发展。没有什么怪力乱神,什么内存计算,什么下一代之类的花哨说法的。spark 是站在hadoop and database 这两个巨人肩膀上的。
举个spark 处理迭代计算的Example
2. Spark 版本的PageRank 比Hadoop 快的不是一点点。根本原因就是在每一步迭代的时候,需要做两个big table euqi-join。hadoop mr 的算法是要做data shuffle,同时需要把需要计算的数据从hdfs 多次读出写入。回溯到5年前,最先发现Hadoop 在处理迭代计算,存在i/o 读写浪费的瓶颈的是 vldb10 的 LoopHadoop 的论文,其中的一作是一个中国哥们,现在citation 已经超过400多了。解决的方法就是把多个迭代中不变的数据,cache 下来,下一步计算就不需要从disk 里面读写了,Spark 也是根据类似的idea 可以把需要反复计算的数据, cache 下来。
3. 接着上面的问题,数据cache 下来之后,why spark 在迭代的时候不需要shuffle 了阿? 因为spark 定义了rdd 之间的dependence 关系,这个关系决定了是否需要shuffle. 比如一个spark 有多个partition, 如果一个rdd 到另外一个rdd 是 全依赖关系,就是说一个partition 的数据,始终在local 计算,或者只是需要去取指定的一个partition 的数据的话,那么shuffle 就是不需要了。我们可以看到,所有计算的依赖关系都是在计算之前就定义好了。有了 rdd 之间的依赖关系,就是可以得到计算的 logical plan and physical plan, 然后去执行计算. 这就是典型的数据库的思想。当然rdd 也就是数据库view 的思想的实现,因为rdd 和view 都是需要的时候再计算的模式,这样就可以有了计算的pipeline,也完全是数据库pipeline 的实现的吗。大家如果看到spark rdd code 里面到处的iterator,就更明白了 。
4. 回到page rank 的列子,两个大表(A,B)之间的join, 因为数据已经按照hash patitioner 把数据分块划好了。就是A B 数据的key 在一个范围的已经分入到具体的partition 里面了,那join的时候,就只是需要对应的partition 作对应的join 就可以的。这样就避免了数据的shuffle 了的。
5. 其实spark 是一点点一点点的工程和学术的结合基础上做出来的, 本质就是Hadoop mapreduce 的增强版本。大家可以看到,在理论上都没有太多新的东西。 所以人家马铁大神当年论文也是被拒了好多遍的。但是系统就是这一点点的改进的基础上做出的。马铁的老板之一是Franklin,F的老板是 UCI 的大牛Carey, Carey 的老板大家自己google 吧。UCB的人的确是牛!
6. 最后我觉得比较hadoop vs spark 不是一个很好的比较方式,因为他们都是一个流派的。比较合适的,是比较 MapReduce Vs MPI,因为在MPI 的计算模式和MapReduce 有大的区别。如果在计算传输数据量不大的时候,比如单纯的numerical 计算的时侯,MPI 都要甩 MapReduce 几条街。最简单就是你想想人家超算做了几十年了,在大的计算集群上的计算上则几万核啊,经典的 one to all, all to all, all to one, data grid 都是很妙的方法好吧。但是如果在处理文本啊之类的数据的时候,一个单词可能出现了很多次,需要大量的数据传输,这时候MapReduce shuffle 机制就显示出优势来了。当然MPI 没有考虑 fault tolerance,也是在cloud 环境下,MapReduce 更有效的原因之一。我根据我有限的知识对Hadoop和Spark做一下对比,在附加一点自己的评论就好了。
原生语言:hadoop-JAVA,Spark-scala
评注:虽然可以实现接口,但原生的语言就是好用,如果某人痛恨java,Spark给你一条生路。
计算模型:hadoop-MapReduce,Spark-DAG(有向无环图)
评注:经常有人说Spark就是内存版的MapReduce,实际上不是的。Spark使用的DAG计算模型可以有效的减少Map和Reduce人物之间传递的数据,尤其适合反复迭代的机器学习场景。而Hadoop则更擅长批处理。不过Tez也是使用的DAG计算模型,他也是Hadoop,明眼人都知道DAG计算模型比MR更好。
评注:spark既可以仅用内存存储,也可以在HDFS上存储,即使Spark在HDFS上存储,DAG计算模型在迭代计算上还是比MR的更有效率。
我并不觉得这两个及系统又大多的矛盾,只不过Spark一直宣称比hadoop快而已。实际上从应用场景上区分,Hadoop更适合做批处理,而Spark更适合做需要反复迭代的机器学习。
主要是先看MapReduce模型有什么问题?
第一:需要写很多底层的代码不够高效,第二:所有的事情必须要转化成两个操作Map/Reduce,这本身就很奇怪,也不能解决所有的情况。
其实Spark出现就是为了解决上面的问题。介绍一些Spark的起源。发自 2010年Berkeley AMPLab,发表在hotCloud 是一个从学术界到工业界的成功典范,也吸引了顶级VC:Andreessen Horowitz的 注资 AMPLab这个实验室非常厉害,做大数据,云计算,跟工业界结合很紧密,之前就是他们做Mesos,Hadoop online, 在2013年,这些大牛(MIT最年轻的助理教授)从Berkeley AMPLab出去成立了Databricks。它是用函数式语言Scala编写,Spark简单说就是内存计算(包含迭代式计算,DAG计算,流式计算 )框架,之前MapReduce因效率低下大家经常嘲笑,而Spark的出现让大家很清新。 Reynod 作为Spark核心开发者, 介绍Spark性能超Hadoop百倍,算法实现仅有其1/10或1/100。
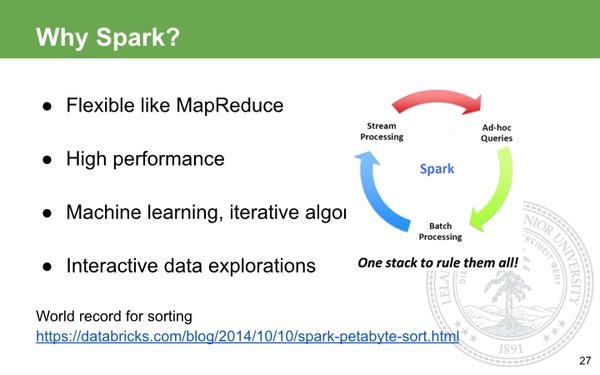
为啥用Spark,最直接的就是快啊,你用Hadoop跑大规模数据几个小时跑完,这边才几十秒,这种变化不仅是数量级的,并且是对你的开发方式翻天覆地的变化,比如你想验证一个算法,你也不知道到底效果如何,但如果能在秒级就给你反馈,你可以立马去调节。其他的如比MapReduce灵活啊,支持迭代的算法,ad-hoc query, 不需要你费很多力气花在软件的搭建上。在去年的Sorting Benchmark上,Spark用了比Hadoop更少的节点在23min跑完了100TB的排序,刷新了之前Hadoop保持的世界纪录。
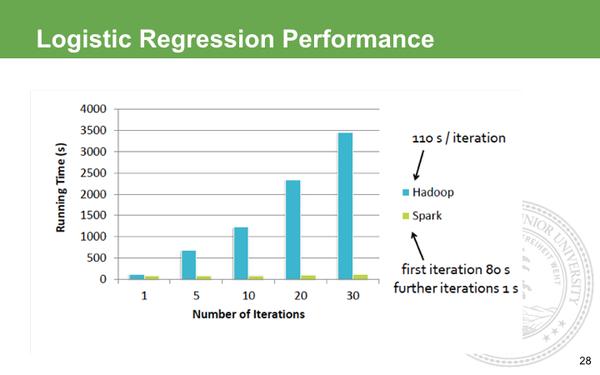
这个是跟Hadoop跟Spark在回归算法上比较,在Hadoop的世界里,做迭代计算是非常耗资源,它每次的IO 序列画代价很大,所以每次迭代需要差不多的等待。而Spark第一次启动需要载入到内存,之后迭代直接在内存利用中间结果做不落地的运算,所以后期的迭代速度快到可以忽略不计。
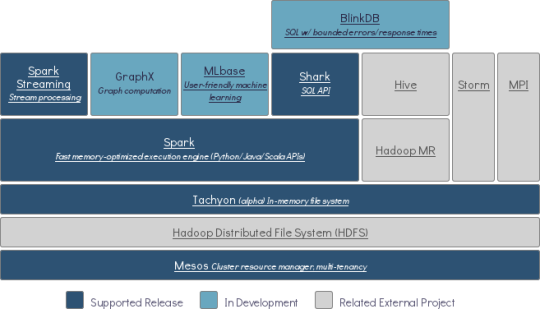 这个是著名的Berkeley Data Analytics Stack, 除了Spark,还有Mesos 和Techyon
这个是著名的Berkeley Data Analytics Stack, 除了Spark,还有Mesos 和Techyon
Mesos:一个分布式环境的资源管理平台,它使得Hadoop、MPI、Spark作业在统一资源管理环境下执行。它对Hadoop2.0支持很好。Twitter,Coursera都在使用。
Tachyon:是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark和MapReduce那样。有幸跟项目发起人李浩源聊过几次,这个项目目前发展非常快,甚至比Spark当时还要惊人。目前到0.6版本,参与开源的规模和版本迭代速度都很快。已经拿到著名VC A16Z 750万美金的投资,https://www.crunchbase.com/organization/tachyon-networks
最新做出的Spark SQL提出Dataframe接口,看起来确实很有野心!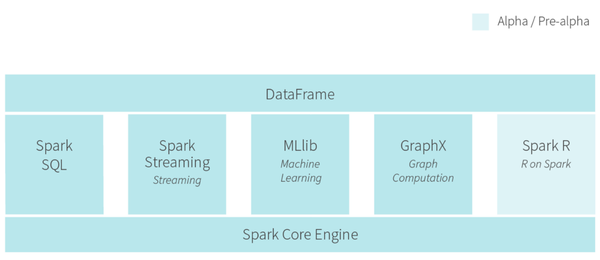
Spark是基于内存的分布式计算引擎,以处理的高效和稳定著称。然而在实际的应用开发过程中,开发者还是会遇到种种问题,其中一大类就是和性能相关。在本文中,笔者将结合自身实践,谈谈如何尽可能地提高应用程序性能。
分布式计算引擎在调优方面有四个主要关注方向,分别是CPU、内存、网络开销和I/O,其具体调优目标如下:
- 提高CPU利用率。
- 避免OOM。
- 降低网络开销。
- 减少I/O操作。
数据倾斜意味着某一个或某几个Partition中的数据量特别的大,这意味着完成针对这几个Partition的计算需要耗费相当长的时间。
如果大量数据集中到某一个Partition,那么这个Partition在计算的时候就会成为瓶颈。图1是Spark应用程序执行并发的示意图,在Spark中,同一个应用程序的不同Stage是串行执行的,而同一Stage中的不同Task可以并发执行,Task数目由Partition数来决定,如果某一个Partition的数据量特别大,则相应的task完成时间会特别长,由此导致接下来的Stage无法开始,整个Job完成的时间就会非常长。
要避免数据倾斜的出现,一种方法就是选择合适的key,或者是自己定义相关的partitioner。在Spark中Block使用了ByteBuffer来存储数据,而ByteBuffer能够存储的最大数据量不超过2GB。如果某一个key有大量的数据,那么在调用cache或persist函数时就会碰到spark-1476这个异常。
下面列出的这些API会导致Shuffle操作,是数据倾斜可能发生的关键点所在
- groupByKey
- reduceByKey
- aggregateByKey
- sortByKey
- join
- cogroup
- cartesian
- coalesce
- repartition
- repartitionAndSortWithinPartitions
图1: Spark任务并发模型
def rdd: RDD[T]}// TODO View bounds are deprecated, should use context bounds// Might need to change ClassManifest for ClassTag in spark 1.0.0case class DemoPairRDD[K <% Ordered[K] : ClassManifest, V: ClassManifest]( rdd: RDD[(K, V)]) extends RDDWrapper[(K, V)] { // Here we use a single Long to try to ensure the sort is balanced, // but for really large dataset, we may want to consider // using a tuple of many Longs or even a GUID def sortByKeyGrouped(numPartitions: Int): RDD[(K, V)] = rdd.map(kv => ((kv._1, Random.nextLong()), kv._2)).sortByKey() .grouped(numPartitions).map(t => (t._1._1, t._2))}case class DemoRDD[T: ClassManifest](rdd: RDD[T]) extends RDDWrapper[T] { def grouped(size: Int): RDD[T] = { // TODO Version where withIndex is cached val withIndex = rdd.mapPartitions(_.zipWithIndex) val startValues = withIndex.mapPartitionsWithIndex((i, iter) => Iterator((i, iter.toIterable.last))).toArray().toList .sortBy(_._1).map(_._2._2.toLong).scan(-1L)(_ + _).map(_ + 1L) withIndex.mapPartitionsWithIndex((i, iter) => iter.map { case (value, index) => (startValues(i) + index.toLong, value) }) .partitionBy(new Partitioner { def numPartitions: Int = size def getPartition(key: Any): Int = (key.asInstanceOf[Long] * numPartitions.toLong / startValues.last).toInt }) .map(_._2) }}定义隐式的转换
implicit def toDemoRDD[T: ClassManifest](rdd: RDD[T]): DemoRDD[T] = new DemoRDD[T](rdd) implicit def toDemoPairRDD[K <% Ordered[K] : ClassManifest, V: ClassManifest]( rdd: RDD[(K, V)]): DemoPairRDD[K, V] = DemoPairRDD(rdd) implicit def toRDD[T](rdd: RDDWrapper[T]): RDD[T] = rdd.rdd}在spark-shell中就可以使用了
import RDDConversions._yourRdd.grouped(5)Spark的Shuffle过程非常消耗资源,Shuffle过程意味着在相应的计算节点,要先将计算结果存储到磁盘,后续的Stage需要将上一个Stage的结果再次读入。数据的写入和读取意味着Disk I/O操作,与内存操作相比,Disk I/O操作是非常低效的。
使用iostat来查看disk i/o的使用情况,disk i/o操作频繁一般会伴随着cpu load很高。
如果数据和计算节点都在同一台机器上,那么可以避免网络开销,否则还要加上相应的网络开销。 使用iftop来查看网络带宽使用情况,看哪几个节点之间有大量的网络传输。 图2是Spark节点间数据传输的示意图,Spark Task的计算函数是通过Akka通道由Driver发送到Executor上,而Shuffle的数据则是通过Netty网络接口来实现。由于Akka通道中参数spark.akka.framesize决定了能够传输消息的最大值,所以应该避免在Spark Task中引入超大的局部变量。
图2: Spark节点间的数据传输
第1节 选择合适的并发数为了提高Spark应用程序的效率,尽可能的提升CPU的利用率。并发数应该是可用CPU物理核数的两倍。在这里,并发数过低,CPU得不到充分的利用,并发数过大,由于spark是每一个task都要分发到计算结点,所以任务启动的开销会上升。
并发数的修改,通过配置参数来改变spark.default.parallelism,如果是sql的话,可能通过修改spark.sql.shuffle.partitions来修改。
第1项 Repartition vs. Coalescerepartition和coalesce都能实现数据分区的动态调整,但需要注意的是repartition会导致shuffle操作,而coalesce不会。
第2节 reduceByKey vs. groupBygroupBy操作应该尽可能的避免,第一是有可能造成大量的网络开销,第二是可能导致OOM。以WordCount为例来演示reduceByKey和groupBy的差异
reduceByKey sc.textFile(“README.md”).map(l=>l.split(“,”)).map(w=>(w,1)).reduceByKey(_ + _)图3:reduceByKey的Shuffle过程
Shuffle过程如图2所示
groupByKey sc.textFile(“README.md”).map(l=>l.split(“,”)).map(w=>(w,1)).groupByKey.map(r=>(r._1,r._2.sum))图4:groupByKey的Shuffle过程
建议: 尽可能使用reduceByKey, aggregateByKey, foldByKey和combineByKey
假设有一RDD如下所示,求每个key的均值
val data = sc.parallelize( List((0, 2.), (0, 4.), (1, 0.), (1, 10.), (1, 20.)) )
方法一:reduceByKey
data.map(r=>(r._1, (r.2,1))).reduceByKey((a,b)=>(a._1 + b._1, a._2 + b._2)).map(r=>(r._1,(r._2._1/r._2._2)).foreach(println)方法二:combineByKeydata.combineByKey(value=>(value,1), (x:(Double, Int), value:Double)=> (x._1+value, x._2 + 1), (x:(Double,Int), y:(Double, Int))=>(x._1 + y._1, x._2 + y._2))
第3节 BroadcastHashJoin vs. ShuffleHashJoin在Join过程中,经常会遇到大表和小表的join. 为了提高效率可以使用BroadcastHashJoin, 预先将小表的内容广播到各个Executor, 这样将避免针对小表的Shuffle过程,从而极大的提高运行效率。
其实BroadCastHashJoin核心就是利用了BroadCast函数,如果理解清楚broadcast的优点,就能比较好的明白BroadcastHashJoin的优势所在。
以下是一个简单使用broadcast的示例程序。
val lst = 1 to 100 toListval exampleRDD = sc.makeRDD(1 to 20 toSeq, 2)val broadcastLst = sc.broadcast(lst)exampleRDD.filter(i=>broadcastLst.valuecontains(i)).collect.foreach(println)有时需要将计算结果存储到外部数据库,势必会建立到外部数据库的连接。应该尽可能的让更多的元素共享同一个数据连接而不是每一个元素的处理时都去建立数据库连接。
在这种情况下,mapPartitions和foreachPartitons将比map操作高效的多。
第5节 数据就地读取移动计算的开销远远低于移动数据的开销。
Spark中每个Task都需要相应的输入数据,因此输入数据的位置对于Task的性能变得很重要。按照数据获取的速度来区分,由快到慢分别是:
- PROCESS_LOCAL
- NODE_LOCAL
- RACK_LOCAL
Spark在Task执行的时候会尽优先考虑最快的数据获取方式,如果想尽可能的在更多的机器上启动Task,那么可以通过调低spark.locality.wait的值来实现, 默认值是3s。
除了HDFS,Spark能够支持的数据源越来越多,如Cassandra, HBase,MongoDB等知名的NoSQL数据库,随着Elasticsearch的日渐兴起,spark和elasticsearch组合起来提供高速的查询解决方案也成为一种有益的尝试。
上述提到的外部数据源面临的一个相同问题就是如何让spark快速读取其中的数据, 尽可能的将计算结点和数据结点部署在一起是达到该目标的基本方法,比如在部署Hadoop集群的时候,可以将HDFS的DataNode和Spark Worker共享一台机器。
以cassandra为例,如果Spark的部署和Cassandra的机器有部分重叠,那么在读取Cassandra中数据的时候,通过调低spark.locality.wait就可以在没有部署Cassandra的机器上启动Spark Task。
对于Cassandra, 可以在部署Cassandra的机器上部署Spark Worker,需要注意的是Cassandra的compaction操作会极大的消耗CPU,因此在为Spark Worker配置CPU核数时,需要将这些因素综合在一起进行考虑。
这一部分的代码逻辑可以参考源码TaskSetManager::addPendingTask
private def addPendingTask(index: Int, readding: Boolean = false) { // Utility method that adds `index` to a list only if readding=false or it's not already there def addTo(list: ArrayBuffer[Int]) { if (!readding || !list.contains(index)) { list += index } } for (loc <- tasks(index).preferredLocations) { loc match { case e: ExecutorCacheTaskLocation => addTo(pendingTasksForExecutor.getOrElseUpdate(e.executorId, new ArrayBuffer)) case e: HDFSCacheTaskLocation => { val exe = sched.getExecutorsAliveOnHost(loc.host) exe match { case Some(set) => { for (e <- set) { addTo(pendingTasksForExecutor.getOrElseUpdate(e, new ArrayBuffer)) } logInfo(s"Pending task $index has a cached location at ${e.host} " + ", where there are executors " + set.mkString(",")) } case None => logDebug(s"Pending task $index has a cached location at ${e.host} " + ", but there are no executors alive there.") } } case _ => Unit } addTo(pendingTasksForHost.getOrElseUpdate(loc.host, new ArrayBuffer)) for (rack <- sched.getRackForHost(loc.host)) { addTo(pendingTasksForRack.getOrElseUpdate(rack, new ArrayBuffer)) } } if (tasks(index).preferredLocations == Nil) { addTo(pendingTasksWithNoPrefs) } if (!readding) { allPendingTasks += index // No point scanning this whole list to find the old task there }}如果准备让spark支持新的存储源,进而开发相应的RDD,与位置相关的部分就是自定义getPreferredLocations函数,以elasticsearch-hadoop中的EsRDD为例,其代码实现如下。
override def getPreferredLocations(split: Partition): Seq[String] = { val esSplit = split.asInstanceOf[EsPartition] val ip = esSplit.esPartition.nodeIp if (ip != null) Seq(ip) else Nil}使用好的序列化算法能够提高运行速度,同时能够减少内存的使用。
Spark在Shuffle的时候要将数据先存储到磁盘中,存储的内容是经过序列化的。序列化的过程牵涉到两大基本考虑的因素,一是序列化的速度,二是序列化后内容所占用的大小。
kryoSerializer与默认的javaSerializer相比,在序列化速度和序列化结果的大小方面都具有极大的优势。所以建议在应用程序配置中使用KryoSerializer.
spark.serializer org.apache.spark.serializer.KryoSerializer默认的cache没有对缓存的对象进行序列化,使用的StorageLevel是MEMORY_ONLY,这意味着要占用比较大的内存。可以通过指定persist中的参数来对缓存内容进行序列化。
exampleRDD.persist(MEMORY_ONLY_SER)需要特别指出的是persist函数是等到job执行的时候才会将数据缓存起来,属于延迟执行; 而unpersist函数则是立即执行,缓存会被立即清除。
更多内容可以访问 community.qingcloud.com我们公司现在Spark和Hadoop都在用,从我的感受来看,虽然Spark目前还不够成熟,但是今后一定会代替Hadoop。
1. 相同的算法,Spark比Hadoop快数倍,如果是一些迭代或者要对数据反复读取的算法,Spark比Hadoop快数十倍至上百倍
2. Spark对于数据的操作种类更多,对于一些比较特殊的计算需求,比如求两个集合的交集并集,Spark都有函数直接计算,而Hadoop实现这样的计算无比繁琐
3. Spark的开发效率比Hadoop高很多
spark相对hadoop编程模型简单,能进行迭代操作,利用内存(甚至是堆外内存)缓存数据,能进行流水线优化,上层封装了sql、streaming、mlib、graphx等或成熟或不成熟的框架,明显有取hadoop而代之的倾向。
特别是最近以十分之一的资源条件打破了Hadoop之前保持的排序纪录。
利益相关:未来3-5年靠spark吃饭。估计100~1000 rmb可以应对大多数100tb到1pb的运算
巨大的低成本优势 几乎是个人都可以分析大数据了
属于Hadoop生态的一部分,Hadoop生态计算引擎目前包括:Hadoop MapReduce、Spark/Spark 2.0、TEZ、Flink等,这里从计算模型,各自的特点分为了1G、2G、3G、3.8G、4G,分别代表其理论先进程度。Spark理论上并不是最先进的,但是目前来讲应该是最适合的。和封神一起“深挖”Spark-博客-云栖社区-阿里云
Hadoop是10年前的技术了,在这个技术更新换代太快的时代,的确是长江后浪推前浪。
又看到王家林大忽悠。
Spark是完全可以取代Hadoop MapReduce的计算框架。
Hadoop = HDFS + YARN + MapReduce
YARN负责资源调度,依然发挥重要作用,不可获取的重要组件之一,Spark也可以跑在它上面,相比Mesos(C++),YARN是Hadoop自带的,用起来比较方便。
MapReduce计算框架,在Spark面前已失去性能及速度优势,基本面临淘汰。
最近课程需要,认真看了看MapReduce和Spark最初的那两篇paper。从一个学生的角度谈谈自己的看法。文中英文只是出于方便,或者不知道如何恰当翻译。
首先,二者都是并行化计算技术,目的是处理海量数据。因数据量大,也往往需要分布式存储系统(GFS,HDFS等)的支持。
关于MapReduce的原理,很多答案都讲明白了,我就不赘述了。主要说说Spark相比MapReduce的改变。
Spark的提出很大程度上是为了解决MapReduce在处理迭代算法上的缺陷。由于MapReduce的数据流是acyclic的,且数据存储在磁盘,这就导致在迭代计算时需要反复进行磁盘读写操作,大大降低了计算效率。而事实上当前机器学习的大多数算法都是迭代算法,因此解决这一问题具有很大的应用价值。
Spark解决这一问题的方法是提供了一个更强大的primitive数据抽象模型--RDD(Resilient Distributed Datasets),并定义了一系列转化(map,filter,sample,...)和分布式操作(reduce,collect,count...)。
RDD的妙处很多。举例如下:- RDD可以被cache在内存中。这种机制无疑可以简单有效地解决MapReduce在迭代计算时反复读取写出磁盘的问题,但同时大大增大了内存开销。这里有一个tradeoff.
- RDD帮助Fault Recovery. RDD可存储lineage信息来重建lost partitions. 比如记录RDD的转化过程。MapReduce采用的是checkpointing机制,代价要大很多。
- RDD是一个logical单元,甚至不需要实例化,而只需包含从磁盘重建workset的信息。
- Spark无疑更快。原因除了上面所说之外,还有就是RDD是immutable的因此不存在synchronisation的问题。
- Spark的caching机制允许讲数据和中间结果cache在内存中,大大提高了计算效率。
- Spark的recovery机制比MapReduce更有效。
- Spark的API更强大,抽象层次更高。
- Spark更消耗内存。但是在云计算时代性价比更高,参考云收费方法。
- Spark在安全方面还有很大空间,相比之下Hadoop较为成熟。不过随着Spark的发展,此方面的劣势相信也会逐渐减小。
你们公司。。。竟然会被这种典型的骗子骗。。。哎
这是典型骗子,不作过多解释了,你赶紧想办法跳槽吧我们公司也请了这个人授课,貌似价格还不菲…
我也感觉是骗子同时宣布了Hadoop的死刑 ,我觉得这句话说得非常的过。hadoop根深蒂固,怎么可能被干掉?试问现在那个做大数据的能脱离得了hdfs与yarn?spark不也是在yarn上用的模式居多?
当然了,spark确实是一个好东西,我们也基于spark之上做了不少东西,尤其是我们的检索与排序,基于spark之上后,性能不仅杠杠的,而且支持很多复杂的SQL。
下面是我们之前基于spark之上二次开发的一些东西,可以说挺爽的。
基于spark排序的一种更廉价的实现方案-附基于spark的性能测试
排序可以说是很多日志系统的硬指标(如按照时间逆序排序),如果一个大数据系统不能进行排序,基本上是这个系统属于不可用状态,排序算得上是大数据系统的一个“刚需”,无论大数据采用的是hadoop,还是spark,还是impala,hive,总之排序是必不可少的,排序的性能测试也是必不可少的。
有着计算奥运会之称的Sort Benchmark全球排序每年都会举行一次,每年巨头都会在排序上进行巨大的投入,可见排序速度的高低有多么重要!但是对于大多数企业来说,动辄上亿的硬件投入,实在划不来、甚至远远超出了企业的项目预算。相比大数据领域的暴力排序有没有一种更廉价的实现方式?
在这里,我们为大家介绍一种新的廉价排序方法,我们称为blockSort。
500G的数据300亿条数据,只使用4台 16核,32G内存,千兆网卡的虚拟机即可实现 2~15秒的 排序 (可以全表排序,也可以与任意筛选条件筛选后排序)。
一、基本的思想是这样的,如下图所示:
1.将数据按照大小预先划分好,如划分成 大、中、小三个块(block)。
2.如果想找最大的数据,那么只需要在最大的那个块里去找就可以了。
3.这个快还是有层级结构的,如果每个块内的数据量很多,可以到下面的子快内进行继续查找,可以分多个层进行排序。
4.采用这种方法,一个亿万亿级别的数据(如long类型),最坏最坏的极端情况也就进行2048次文件seek就可以筛选到结果。
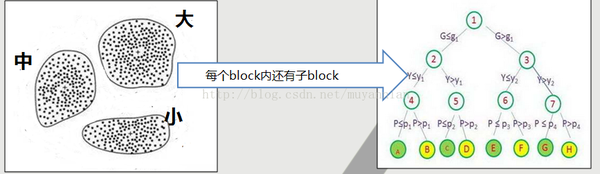
怎么样,原理是不是非常简单,这样数据量即使特别多,那么排序与查找的次数是固定的。
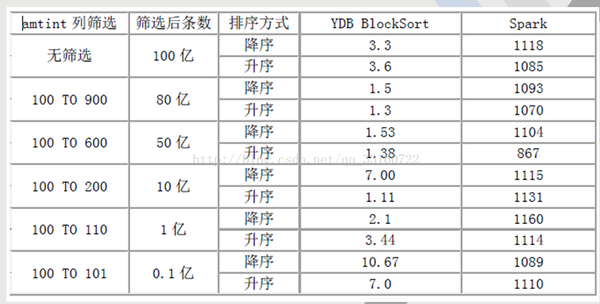
二、这个是我们之前基于spark做的性能测试,供大家参考
在排序上,YDB具有绝对优势,无论是全表,还是基于任意条件组合过滤,基本秒杀Spark任何格式。
测试结果(时间单位为秒)
三、当然除了排序上,我们的其他性能也是远远高于spark,这块大家也可以了解一下
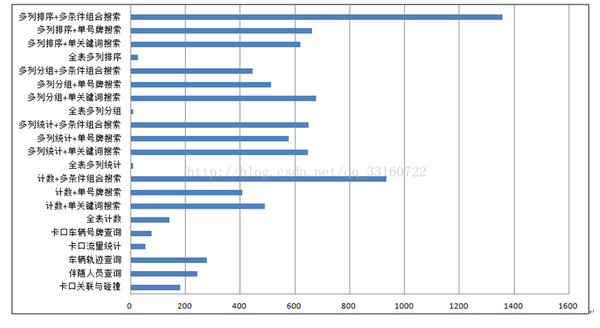
1、与Spark txt在检索上的性能对比测试。
注释:备忘。下图的这块,其实没什么特别的,只不过由于YDB本身索引的特性,不想spark那样暴力,才会导致在扫描上的性能远高于spark,性能高百倍不足为奇。
下图为ydb相对于spark txt提升的倍数
2、这些是与 Parquet 格式对比(单位为秒)
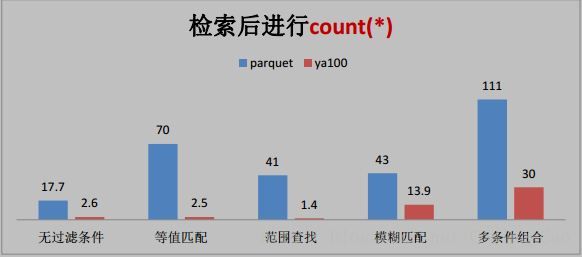
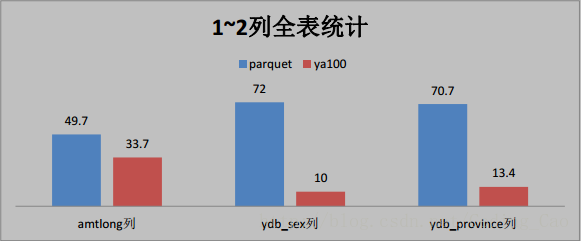
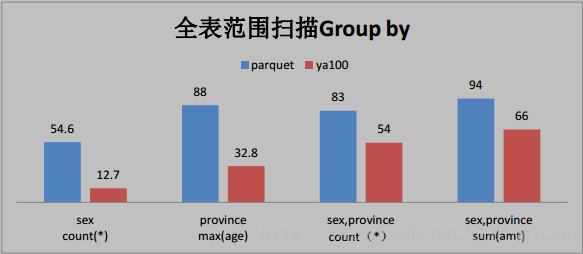
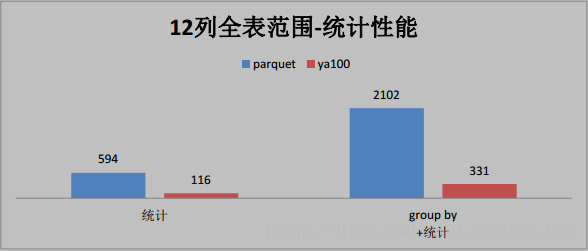
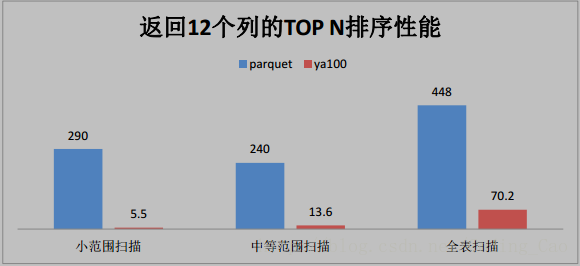
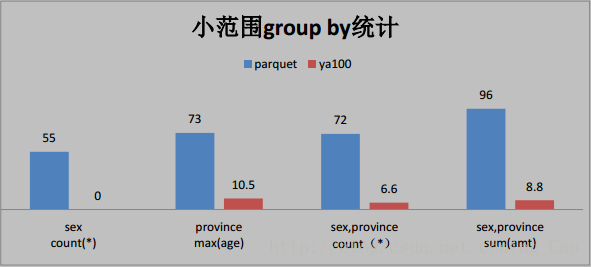
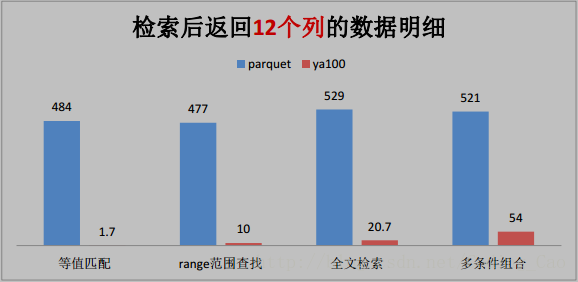
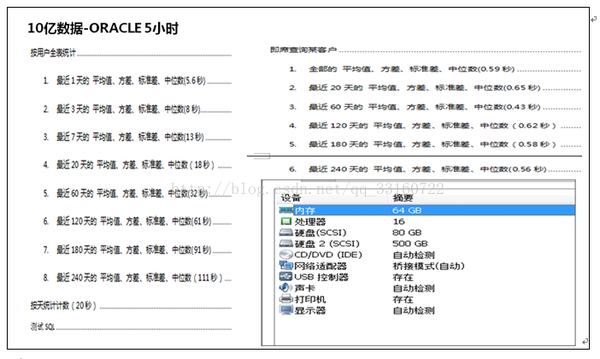
3、与ORACLE性能对比
跟传统数据库的对比,已经没啥意义,Oracle不适合大数据,任意一个大数据工具都远超oracle 性能。
4.稽查布控场景性能测试
四、YDB是怎么样让spark加速的?
基于Hadoop分布式架构下的实时的、多维的、交互式的查询、统计、分析引擎,具有万亿数据规模下的秒级性能表现,并具备企业级的稳定可靠表现。
YDB是一个细粒度的索引,精确粒度的索引。数据即时导入,索引即时生成,通过索引高效定位到相关数据。YDB与Spark深度集成,Spark对YDB检索结果集直接分析计算,同样场景让Spark性能加快百倍。
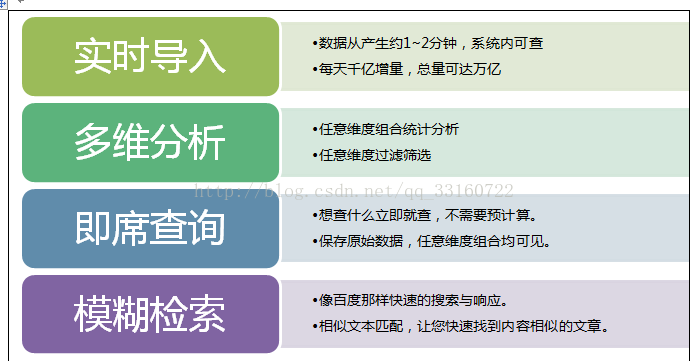
五、哪些用户适合使用YDB?
1.传统关系型数据,已经无法容纳更多的数据,查询效率严重受到影响的用户。
2.目前在使用SOLR、ES做全文检索,觉得solr与ES提供的分析功能太少,无法完成复杂的业务逻辑,或者数据量变多后SOLR与ES变得不稳定,在掉片与均衡中不断恶性循环,不能自动恢复服务,运维人员需经常半夜起来重启集群的情况。
3.基于对海量数据的分析,但是苦于现有的离线计算平台的速度和响应时间无满足业务要求的用户。
4.需要对用户画像行为类数据做多维定向分析的用户。
5.需要对大量的UGC(User Generate Content)数据进行检索的用户。
6.当你需要在大数据集上面进行快速的,交互式的查询时。
7.当你需要进行数据分析,而不只是简单的键值对存储时。
8.当你想要分析实时产生的数据时。
ps: 说了一大堆,说白了最适合的还是踪迹分析因为数据量大,数据还要求实时,查询还要求快。这才是关键。
视频地址 (看不清的同学可以进入腾讯视频 高清播放)
https://v.qq.com/x/page/q0371wjj8fb.html
https://v.qq.com/x/page/n0371l0ytji.html
感兴趣的读者也可以阅读YDB编程指南 http://url.cn/42R4CG8 。也可以参考该书自己安装延云YDB进行测试。
- 与 Hadoop 对比,如何看待 Spark 技术?
- 与 Hadoop 对比,如何看待 Spark 技术
- 与 Hadoop 对比,如何看待 Spark 技术?
- 与 Hadoop 对比,如何看待 Spark 技术?
- 与 Hadoop 对比,如何看待 Spark 技术?
- 与Hadoop相比,如何看待Spark技术?
- spark与hadoop对比
- spark与hadoop对比
- 与Hadoop相比,怎么看待spark?
- 如何看待人生与技术的价值
- 如何看待人生与技术的价值
- 如何看待人生与技术的价值
- Hadoop与Spark技术入门
- Spark与Hadoop MapReduce的对比分析
- Hadoop与Spark的核心组件对比
- 如何看待技术学习
- 如何看待基础分析与技术分析的区别
- Spark于hadoop对比
- 《并发编程》--8.线程优先级
- python3.5学习if(学习笔记2)
- css水平垂直居中
- 如何让windows控制台程序运行时不显示黑色框,直接运行
- Go语言接口的内部实现
- 与 Hadoop 对比,如何看待 Spark 技术?
- HDFS文件系统
- Eclipse下Struts2环境配置步骤
- MySQL开发规范与使用技巧总结
- MySQL数据库远程连接开启方法
- Mathematica9.0中文版软件下载详细图文安装步骤!
- centos7 下安装配置Tomcat
- CodeForces
- [复习]高斯消元 解方程组


