使用Erlang、C和Lisp实现的BigData解决海量移动数据
来源:互联网 发布:第八届云计算大会ppt 编辑:程序博客网 时间:2024/06/03 05:46
BugSense是一个错误汇报和质量度量的服务,每天追踪几千个应用。当移动应用崩溃时,BugScense帮助开发者查明并解决问题。这个创业团队为它的客户提供一流的服务,包括VMWare,Sumsung,Skype以及成千上万的独立应用开发者。追踪超过200M设备需要快速、容错以及廉价的基础设施。
最近六个月,我们决定使用我们的BigData基础设施,给用户提供应用性能和稳定性的度量手段,让他们知道错误是怎么影响他们的用户基础和收益的。
我们知道我们的解决方案应该是从第一天开始就必须是可伸缩的,因为外面超过4%的智能手机的数据将会像DDOS攻击一样涌入。
我们希望能够做到:
- 抽象应用逻辑给浏览器回推JSON数据
- 快速运行复杂算法
- 不使用专用Hadoop集群的情况下分析数据
- 预处理数据之后存储(降低存储量)
- 每个节点能够处理超过1000并发的请求
- 在每个应用超过125M行的数据中做join(类似SQL中的join,关联聚合,译者注)
- 不花费巨额服务器成本
解决方案用到:
- 少于20个Azure大型云主机
- 内存数据库
- 一个成熟的用C编写的自定义LISP语言来完成查询,比使用虚拟机(需要垃圾回收)要快好几倍
- 使用Erlang实现节点间通讯
- 修改TCP_TIMEWAIT_LEN达到降低40K的连接,节省CPU、内存和TCP缓冲
常驻内存数据库
我们知道解决所有这些流量唯一的办法是使用一个内存型数据库。
为了实现巨大的数据集合上的ad-hoc查询(例如,“多少三星设备的用户已经遭遇某个错误超过一周了”),不仅需要解决内存限制,还有数据处理前后的序列化、反序列化。这就是我们启动LDB项目的原因。
LDB 项目
你相信你能够向一个系统插入各种类型数据源(甚至上千种不同类型的移动设备)的数据,几行代码就能描述你希望提取的信息,并且将所有这些信息随身携带吗?而且是在实时的、持续运行的系统中?
LDB更多是一个应用服务器而不是个数据库。尽管它是内存型的,数据实际上存储在硬盘并且节点间会复制数据实现冗余备份。
LDB中我们不是简单执行查询。我们运行算法,因为我们有一个完全成熟的C实现的自定义LISP语言可以访问与数据库共享的地址空间。这意味着你能够极快的搜索数据、计数器累加、读写等等。
拥有LISP的优势在于你能够轻易创建像Hive一样的类SQL的语句,实时查询你的数据:
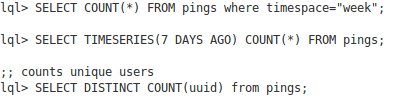
LDB这样运作:
每个应用有它自己的LDB。这意味着它有独立的内存空间,这样一来,我们能轻易的移动更大的应用(按照流量)到不同的机器。
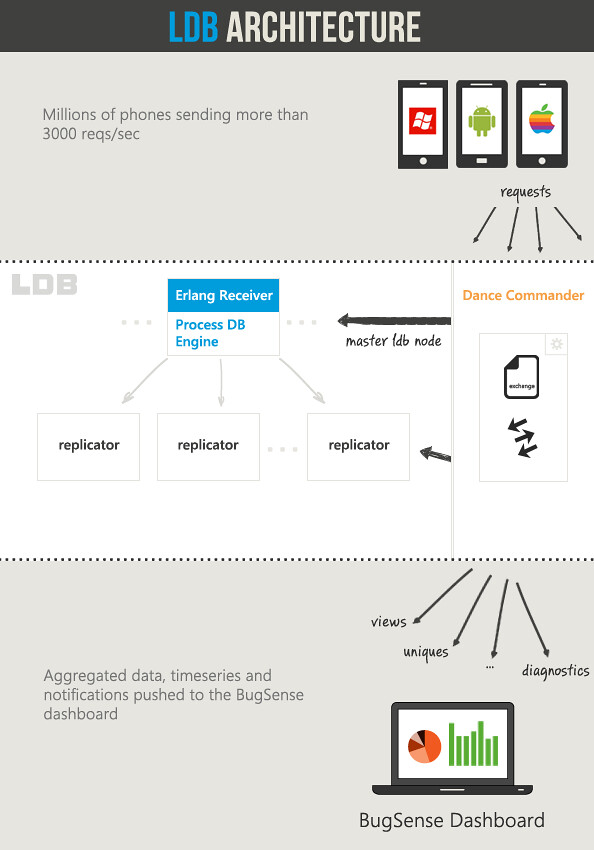
当移动设备的一个请求到达时,主LDB节点,接受连接(使用一个erlang 线程池)然后引导数据到指定的DB,这个请求处理机制只用到少于20行的erlang代码,这也是我们选择erlang实现节点间通讯的另一个原因。
当请求源源不断的涌入LDB时,一个叫“process.lql”的文件负责分析、解析数据、创建若干计数器。对每个请求的所有这些处理都是飞速完成的。
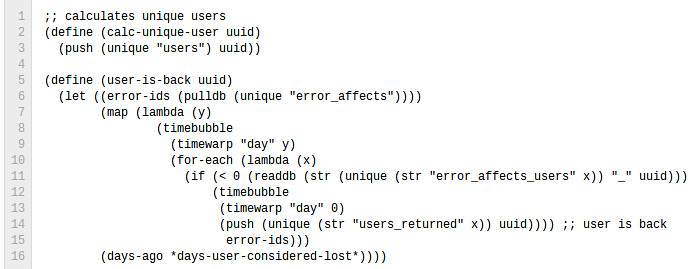
我们有能力做到这些,因为LISP-VM启动以及为每个请求做所有这些处理,比VM(需要垃圾回收)要快好几倍。
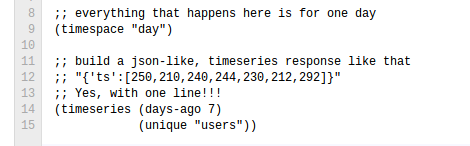
用LDB我们能在3行代码内完成时间序列创建和数据聚合。
比如,这里为一个唯一用户创建一个七天的时间序列:
替代方案
在我们的测试中,我们看到SQL数据库不是一个合适的选择,因为我们的数据是非结构化的而且我们需要非常多的复杂“joins(关联、聚合,译者注)”(以及很多索引)。另外对于NoSQL数据库,我们不能在其数据上运行我们的算法(当系统持续运行时),如果做mappers/reducers也会让整个事情复杂缓慢。我们需要一个高并发的系统,没有大型的锁或者数据库锁,这样用几个KBs就能追踪百万级别的事件而且非常容易扩展。
一个非常好的替代方案是使用流式数据库(比如Storm)。我们主要的问题是单个节点有很多活动部件和逻辑。用LDB,我们能够利用极速处理数据的优势(他们驻于相同的内存空间),存储数据为聚合的计数器或者符号表(因此适合千兆字节的数据),然后用一个DSL来做所有极速统计。没有序列化和反序列化,没有网络消耗也没有垃圾回收。它就像把装配好的代码映射到你的数据一样。
另外LDB中有接收器能够计量和处理到来的数据,所有模块都是用少量几行代码构成的一个流式组件,一个存储引擎和一个复制引擎。
内核优化- UDP TCP对比
我们的场景与其他每秒海量请求的服务有一个明显区别,那就是移动设备和服务器之间的会话包非常小(3个TCP握手包,1个有效数据包和3个TCP结束包)。
但是,TCP没有考虑太多这种场景(设备间的小会话)并且实现了一个叫做TIME_WAIT的状态(2.6linux内核中持续1分钟),当最后一个FIN包被发送,这个连接的TCP状态仍然保持开启一段时间来接收任何遗失、延迟的包(在连接关闭前)。在我们的场景中这有点无用(我们需要类似UDP模式的而不是TCP的可靠性),由于有效数据包只有1个(查询请求可能是4到5个),所以我们决定修改内核源码减少这个常量到20,。结果是令人惊讶的减少了40K的连接,节省了CPU 内存和TCP缓冲。
我们提供的补丁在文件:
linux-kernel-source/include/net/tcp.h
#define TCP_TIMEWAIT_LEN (60*HZ)
to
#define TCP_TIMEWAIT_LEN (20*HZ)
使用这个架构,我们能对所有付费用户的移动应用提供实时分析和监控,只要了不到20个Azure大型云主机,包括灾备和冗余备份在内的服务器。
英文原文:Highscalability,编译:ImportNew - 储晓颖
译文链接:http://www.importnew.com/1706.html
- 使用Erlang、C和Lisp实现的BigData解决海量移动数据
- 海量数据的解决思路
- 海量数据实时使用面对的问题和想法
- 使用erlang实现的quicksort
- SQL Server 索引结构及其使用(三)--实现小数据量和海量数据的通用分页显示存储过程
- BitMap--解决海量数据
- lisp实现的专家系统
- map的lisp实现
- [bigdata-038] tushare 金融数据 安装使用
- [bigdata-001] mysql 5.7 由于安全问题不能导出数据的解决方式
- 使用生产者消费者解决海量数据的处理与相关优化
- C语言实现的lisp解析器介绍
- 使用Ajax实现DropDownList和ListBox的联动以及两个ListBox之间数据的移动
- 使用Ajax实现DropDownList和ListBox的联动以及两个ListBox之间数据的移动
- 使用Ajax实现DropDownList和ListBox的联动以及两个ListBox之间数据的移动
- 使用Ajax实现DropDownList和ListBox的联动以及两个ListBox之间数据的移动
- 使用Ajax实现DropDownList和ListBox的联动以及两个ListBox之间数据的移动
- 使用Ajax实现DropDownList和ListBox的联动以及两个ListBox之间数据的移动
- test
- msf install
- java多态杂记
- Linux学习之路
- lua 转义字符
- 使用Erlang、C和Lisp实现的BigData解决海量移动数据
- Python中静态方法 类方法 实例方法的不同
- Linux间进程通信 管道
- 解决同时安装多个版本jdk,cmd验证和path不一致的问题
- Neo4j CQL -(8)- WHERE子句
- 大数据数组查找最大的100个数据
- Java多线程(10)——ThreadLocal
- 了解linux下的系统调用
- lua提供的string方法


