LaTex在新详情的表现测试
来源:互联网 发布:linux curl命令详解 编辑:程序博客网 时间:2024/04/29 15:21
1.简介
word2vec 是google在2013发布的开源工具包, 用于生产分布式词向量. 它简单高效, 特别适合大规模, 超大规模的语料库, 从中获取高精度的词向量表示.
词向量的介绍看 这里 .
Q: 对于形如
A: 通过向量间的距离(如 余弦距离) 来刻画不同词汇之间的相似度. 这里的相似度并不是同义词, 近义词等, 而是语料库中跟它具有同样相邻词的词.
基于词向量的LSTM架构, 在中文分词, 词性标注, 语义组块, 命名实体识别 等方面取得了良好的效果. 在精度上均与 概率图 模型不相上下, 而产生的模型要小得多.
2.算法原理
word2vec用的是神经网络模型,分为两种
- CBOW, Continuous Bag of Words
- skip-gram
每个模型的训练方法又分别有两种
- Hierarchical Softmax
- Negative Sampling
所以搭配起来,
本文讲述CBOW+Hierarchical Softmax 的原理. 通过周围词来预测当前词.
PS: 网络上《word2vec中的数学原理详解》一文流传甚广, 但我觉得它的符号约定不太友好, 于是写了自己的. 本文不展开偏导计算部分.
2.1 符号约定
- w
要预测的当前词. Context(w)
w上下文相关的词, 它之前的c个词 与 它之后的c个词, 共2c个词.
设c=2,Context(w)=[w(t−2),w(t−1),w(t+1),w(t+2)] - m
分布式词向量的固定长度 - D
语料库Corpus中所有出现单词组成的词典. - path(w)
huffman树中, 单词w的路径.path(w)i∈(0,1) 表示路径向量中第i个分量的值. - len(path(w))
huffman树中, 单词w的路径长度. θ(w)i
huffman树中, 单词w的路径中第i个非叶子节点.θ(w)=(θ(w)1,...,θ(w)len(path(w)))
其中θ(w)1 对应的就是根节点.θ(w)i 也代指该非叶子节点的向量. 它也是m维的.
2.2 网络结构
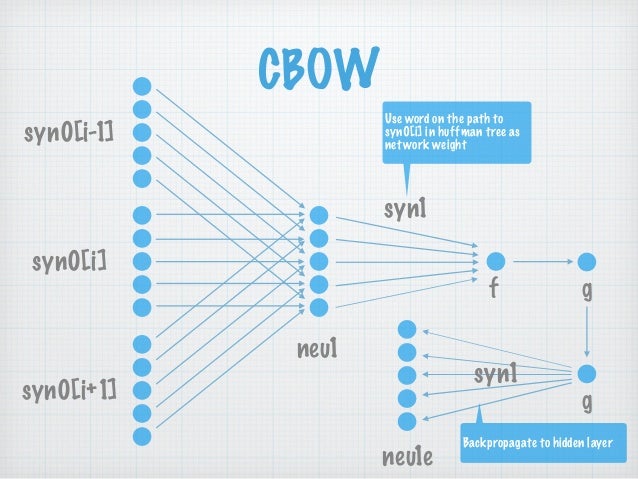
图2-1 CBOW网络结构 syn0[.] 即为 w[.], 表示邻居词汇
每层展开来讲:
ps:自己画图太费时间, 所以下文的符号没有与图2-1 结构对应上, sorry.
- 输入层
Context(w)=[w(t−2),w(t−1),w(t+1),w(t+2)] .
所以共有2c*m个节点.
一般神经网络的输入都是已知的, 而Word2Vec 网络中的输入, 是通过SoftMax()计算后才得到的. - 投影层
有m个节点. 对输入层各词向量作加和处理.∑Context(w) - 输出层
输出层是一棵树, 一棵Huffman树! 这是与普通神经网络的显著不同之处. 这棵树的叶子节点数就是词典D的大小|D| .
Huffman树相关知识可以回顾 树-总述 .
以词频作权重, 我们就构建出了这么一棵Huffman树.
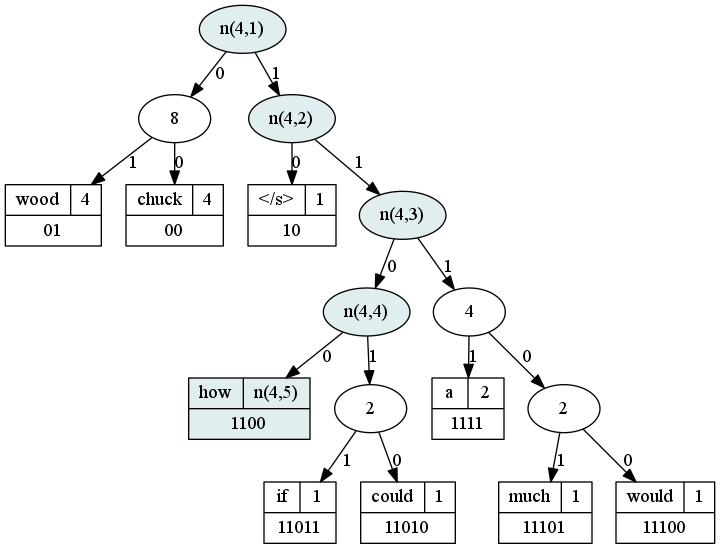
图2-2 网络输出层的示例
以how这个单词来讲, 它的路径就是(1,1,0,0).
2.3 推导计算
每一个单词w, 都对应一个huffman树叶子节点, 因为是二叉的, 所以从根节点走到w的叶子节点, 相当于再不断地进行二分类.
参考文章
huffman-tree-in-word2vec
drawing-word2vec
- LaTex在新详情的表现测试
- 在表现中能不能加进两个新的元素?
- Magento 创建新的产品详情页面
- Latex测试
- 各国人在饥饿时的表现
- onresize在不同浏览器的表现
- 字形在界面上的特异表现
- JVM在执行多态时的表现
- MSDN的好处表现在四方面
- 现在网上的虚拟机有很多,本人测试VMware在Mac上表现良好,推荐给大家
- php7 新特性详情
- 贫富之间的差距不仅表现在数量上,而且也表现在质量上
- 表现层模式新探
- 表现层模式新探
- 新的测试项
- 跳转到APP的详情界面(在设置里面的详情信息)
- LaTeX定义新命令
- Latex 新一页
- 利用@value获取配置文件的信息
- hdu6166 最短路
- 华为eNSP模拟器中两个路由器IP互联
- springMVC记录(二)
- WindowBuilder1.9Release版插件安装
- LaTex在新详情的表现测试
- Java NIO系列教程(一) Java NIO 概述
- HttpURLConnection使用示例
- nginx
- 算法常用的工具---流程图
- TensorFlow/对抗网络DCGAN生成图片
- STL中set基础用法笔记
- Git 版本控制之Xcode 上使用(码云)
- Sitemesh的使用


