浅析栈区和堆区内存分配的区别
来源:互联网 发布:在淘宝上买东西的流程 编辑:程序博客网 时间:2024/05/15 00:36
浅析栈区和堆区内存分配的区别
一直以来总是对这个问题的认识比较朦胧,我相信很多朋友也是这样的,总是听到内存一会在栈上分配,一会又在堆上分配,那么它们之间到底是怎么的区别呢?为了说明这个问题,我们先来看一下内存内部的组织情况.

从上图可知,程序占用的内存被分了以下几部分.
1、栈区(stack)由编译器自动分配释放 ,存放函数的参数值,局部变量的值等,内存的分配是连续的,类似于平时我们所说的栈,如果还不清楚,那么就把它想成数组,它的内存分配是连续分配的,即,所分配的内存是在一块连续的内存区域内.当我们声明变量时,那么编译器会自动接着当前栈区的结尾来分配内存.
2、堆区(heap)一般由程序员分配释放, 若程序员不释放,程序结束时可能由操作系统回收.类似于链表,在内存中的分布不是连续的,它们是不同区域的内存块通过指针链接起来的.一旦某一节点从链中断开,我们要人为的把所断开的节点从内存中释放.
3、全局区(静态区)(static)全局变量和静态变量的存储是放在一块的,初始化的全局变量和静态变量在一块区域, 未初始化的全局变量和未初始化的静态变量在相邻的另一块区域。 程序结束后由系统释放
4、文字常量区常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区存放函数体的二进制代码。
char c; //栈上分配
char *p = new char[3]; //堆上分配,将地址赋给了p;
在 编译器遇到第一条指令时,计算其大小,然后去查找当前栈的空间是大于所需分配的空间大小,如果这时栈内空间大于所申请的空间,那么就为其分配内存空间,注 意:在这里,内在空间的分配是连续的,是接着上次分配结束后进行分配的.如果栈内空间小于所申请的空间大小,那么这时系统将揭示栈溢出,并给出相应的异常 信息.
编译器遇到第二条指令时,由于p是在栈上分配的,所以在为p分配内在空间时和上面的方法一样,但当遇到new关键字,那么编译器都知道,这是用户申请的动态内存空间,所以就会转到堆上去为其寻找空间分配.大家注意:堆上的内存空间不是连续的,它是由相应的链表将其 空间区时的内在区块连接的,所以在接到分配内存空间的指定后,它不会马上为其分配相应的空间,而是先要计算所需空间,然后再到遍列整个堆(即遍列整个链的 节点),将第一次遇到的内存块分配给它.最后再把在堆上分配的字符数组的首地址赋给p.,这个时候,大家已经清楚了,p中现在存放的是在堆中申请的字符数组的首地址,也就是在堆中申请的数组的地址现在被赋给了在栈上申请的指针变量p.为了更加形象的说明问题,请看下图: 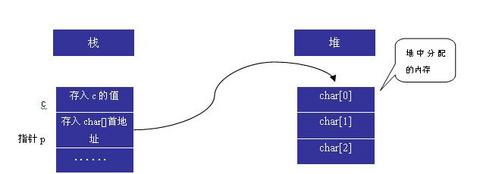
从上图可以看出,我们在堆上动态分配的数组的首地址存入了指针p所指向的内容.
请注意:在栈上所申请的内存空间,当我们出了变量所在的作用域后,系统会自动我们回收这些空间,而在堆上申请的空间,当出了相应的作用域以后,我们需要显式来释放所申请的内存空间,如果我们不及时得对这些空间进行释放,那么内存中的内存碎片就越来越多,从而我们的实际内存空间也就会变的越来越少,孤立的内存块越来越多。在这里,我们知道,堆中的内存区域不是连续的,还是将有效的内存区域经过链表指针连接起来的,如果我们申请到了某一块内存,那么这一块内存区将会从连续的(通过链表连接起来的)内存块上断开,如果我们在使用完后,不及时的对它进行释放,那么它就会孤立的开来,由于没有任何指针指向它,所以这个区域将成为内存碎片,所以在使用完动态分配的内存后,一定要显式的对它进行释放.
小结:
1 、内存分配方面:
堆:堆是向高地址扩展的数据结构,一般由程序员分配释放, 若程序员不释放,程序结束时可能由 OS 回收 。注意它与数据结构中的堆是两回事,分配方式是类似于链表。可能用到的关键字如下: new 、 malloc 、 delete 、 free 等等。
栈:栈是向低地址扩展的数据结构,由编译器 (Compiler) 自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2 、申请方式方面:
堆:需要程序员自己申请,并指明大小。在 c 中 malloc 函数如 p1 = (char *)malloc(10) ;在 C++ 中用 new 运算符,但是注意 p1 、 p2 本身是在栈中的。因为他们还是可以认为是局部变量。
栈:由系统自动分配。 例如,声明在函数中一个局部变量 int b ;系统自动在栈中为 b 开辟空间。
3 、系统响应方面:
堆:操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样代码中的 delete 语句才能正确的释放本内存空间。另外由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
4 、大小限制方面:
堆:是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的 ,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
栈: 是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,栈的大小是固定的(是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示 overflow 。因此,能从栈获得的空间较小。
5 、效率方面:
堆:是由 new 分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
栈:由系统自动分配,速度较快。但程序员是无法控制的。
- 浅析栈区和堆区内存分配的区别
- 浅析栈区和堆区内存分配的区别
- 浅析栈区和堆区内存分配的区别
- 浅析栈区和堆区内存分配的区别
- 浅析栈区和堆区内存分配的区别
- 浅析栈区和堆区内存分配的区别
- 浅析栈区和堆区内存分配的区别
- 浅析栈区和堆区内存分配的区别(转)
- 栈区和堆区内存分配的区别
- 栈区和堆区内存分配区别
- 栈区和堆区内存分配区别 .
- 栈区和堆区内存分配区别
- 栈区和堆区内存分配区别
- 栈区和堆区内存分配区别
- 堆区和栈区内存分配区别
- 栈区和堆区内存分配区别
- 栈区和堆区内存分配区别
- 栈区和堆区内存分配区别
- linux下ssh连接不上
- poI导excel
- slaltstack入门
- 小程序https Android (安卓) 可以发请求,IOS (苹果)发请求失败问题
- 从0开始读java源码
- 浅析栈区和堆区内存分配的区别
- 【练习赛补题】问题 E: 花生采摘 【模拟】
- ListView添加加载动画
- 折半(二分查找)中,使用int mid = low+((high-low)>>>1)的原因
- ionic3 — 标题居中以及添加button的方法,修改图标大小
- LCP与NCP
- speex与webrtc回声消除小结
- (记录合并)union和union all 的区别
- UVALive 2755 Hidden Password (最小表示法)


