CNN目标检测(二):YOLO
来源:互联网 发布:百度笑报程序员 编辑:程序博客网 时间:2024/05/13 21:47
↑↑↑↑目录在这里↑↑↑↑
缩进YOLO全称You Only Look Once: Unified, Real-Time Object Detection,是在CVPR2016提出的一种目标检测算法,核心思想是将目标检测转化为回归问题求解,并基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。YOLO与Faster RCNN有以下区别:
- Faster RCNN将目标检测分解为分类为题和回归问题分别求解:首先采用独立的RPN网络专门求取region proposal,即计算图1中的 P(objetness);然后对利用bounding box regression对提取的region proposal进行位置修正,即计算图1中的Box offsets(回归问题);最后采用softmax进行分类(分类问题)。
- YOLO将物体检测作为一个回归问题进行求解:输入图像经过一次网络,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。

缩进可以看出,YOLO将整个检测问题整合为一个回归问题,使得网络结构简单,检测速度大大加快;由于网络没有分支,所以训练也只需要一次即可完成。这种“把检测转化为回归问题”的思路非常有效,之后的很多检测算法(包括SSD)都借鉴了此思路。
1. YOLO网络结构

缩进上图2中展示了YOLO的网络结构。相比Faster RCNN,YOLO结构简单而,网络中只包含conv,relu,pooling和全连接层,以及最后用来综合信息的detect层。其中使用了1x1卷积用于多通道信息融合(若不明白1x1卷积请查看上一篇Faster RCNN文章)。
2. YOLO核心思想

图3
YOLO的工作过程分为以下几个过程:
(1) 将原图划分为SxS的网格。如果一个目标的中心落入某个格子,这个格子就负责检测该目标。
(2) 每个网格要预测B个bounding boxes,以及C个类别概率Pr(classi|object)。这里解释一下,C是网络分类总数,由训练时决定。在作者给出的demo中C=20,包含以下类别:
人person
鸟bird、猫cat、牛cow、狗dog、马horse、羊sheep
飞机aeroplane、自行车bicycle、船boat、巴士bus、汽车car、摩托车motorbike、火车train
瓶子bottle、椅子chair、餐桌dining table、盆景potted plant、沙发sofa、显示器tv/monitor
在YOLO中,每个格子只有一个C类别,即相当于忽略了B个bounding boxes,每个格子只判断一次类别,这样做非常简单粗暴。
(3) 每个bounding box除了要回归自身的位置之外,还要附带预测一个confidence值。这个confidence代表了所预测的box中含有目标的置信度和这个bounding box预测的有多准两重信息:

如果有目标落中心在格子里Pr(Object)=1;否则Pr(Object)=0。 第二项是预测的bounding box和实际的ground truth之间的IOU。
缩进所以,每个bounding box都包含了5个预测量:(x, y, w, h, confidence),其中(x, y)代表预测box相对于格子的中心,(w, h)为预测box相对于图片的width和height比例,confidence就是上述置信度。需要说明,这里的x, y, w和h都是经过归一化的,之后有解释。
(4) 由于输入图像被分为SxS网格,每个网格包括5个预测量:(x, y, w, h, confidence)和一个C类,所以网络输出是SxSx(5xB+C)大小
(5) 在检测目标的时候,每个网格预测的类别条件概率和bounding box预测的confidence信息相乘,就得到每个bounding box的class-specific confidence score:

显然这个class-specific confidence score既包含了bounding box最终属于哪个类别的概率,又包含了bounding box位置的准确度。最后设置一个阈值与class-specific confidence score对比,过滤掉score低于阈值的boxes,然后对score高于阈值的boxes进行非极大值抑制(NMS, non-maximum suppression)后得到最终的检测框体。
3. YOLO中的Bounding Box Normalization
缩进YOLO在实现中有一个重要细节,即对bounding box的坐标(x, y, w, h)进行了normalization,以便进行回归。作者认为这是一个非常重要的细节。在原文2.2 Traing节中有如下一段:
Our final layer predicts both class probabilities and bounding box coordinates.
We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1.
We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.
缩进接下来分析一下到底如何实现。

图4 SxS网格与bounding box关系(图中S=7,row=4且col=1)
缩进如图4,在YOLO中输入图像被分为SxS网格。假设有一个bounding box(如图4红框),其中心刚好落在了(row,col)网格中,则这个网格需要负责预测整个红框中的dog目标。假设图像的宽为widthimage,高为heightimage;红框中心在(xc,yc),宽为widthbox,高为heightbox那么:
(1) 对于bounding box的宽和高做如下normalization,使得输出宽高介于0~1:

(2) 使用(row, col)网格的offset归一化bounding box的中心坐标:

经过上述公式得到的normalization的(x, y, w, h),再加之前提到的confidence,共同组成了一个真正在网络中用于回归的bounding box;而当网络在Test阶段(x, y, w, h)经过反向解码又可得到目标在图像坐标系的框,解码代码在darknet detection_layer.c中的get_detection_boxes()函数,关键部分如下:
- boxes[index].x = (predictions[box_index + 0] + col) / l.side * w;
- boxes[index].y = (predictions[box_index + 1] + row) / l.side * h;
- boxes[index].w = pow(predictions[box_index + 2], (l.sqrt?2:1)) * w;
- boxes[index].h = pow(predictions[box_index + 3], (l.sqrt?2:1)) * h;
4. YOLO训练过程
缩进对于任何一种网络,loss都是非常重要的,直接决定网络效果的好坏。YOLO的Loss函数设计时主要考虑了以下3个方面
(1) bounding box的(x, y, w, h)的坐标预测误差。
缩进在检测算法的实际使用中,一般都有这种经验:对不同大小的bounding box预测中,相比于大box大小预测偏一点,小box大小测偏一点肯定更不能被忍受。所以在Loss中同等对待大小不同的box是不合理的。为了解决这个问题,作者用了一个比较取巧的办法,即对w和h求平方根进行回归。从后续效果来看,这样做很有效,但是也没有完全解决问题。
(2) bounding box的confidence预测误差
缩进由于绝大部分网格中不包含目标,导致绝大部分box的confidence=0,所以在设计confidence误差时同等对待包含目标和不包含目标的box也是不合理的,否则会导致模型不稳定。作者在不含object的box的confidence预测误差中乘以惩罚权重λnoobj=0.5。
缩进除此之外,同等对待4个值(x, y, w, h)的坐标预测误差与1个值的conference预测误差也不合理,所以作者在坐标预测误差误差之前乘以权重λcoord=5(至于为什么是5而不是4,我也不知道T_T)。
(3) 分类预测误差
缩进即每个box属于什么类别,需要注意一个网格只预测一次类别,即默认每个网格中的所有B个bounding box都是同一类。
所以,YOLO的最终误差为下:
Loss = λcoord * 坐标预测误差 + (含object的box confidence预测误差 + λnoobj * 不含object的box confidence预测误差) + 类别预测误差
=

-------------------------------------------------------下面是一点参考内容--------------------------------------------------------
缩进在各种常用框架中实现网络中一般需要完成forward与backward过程,forward函数只需依照Loss编码即可,而backward函数简需要计算残差delta。这里单解释一下YOLO的负反馈,即backward的实现方法。在UFLDL教程中网络正向传播方式定义为:
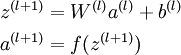
而最后一层反向传播残差定义为:
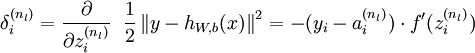
对于YOLO来说,最后一层是detection_layer,而倒数第二层是connected_layer(全连接层),之间没有ReLU层,即相当于最后一层的激活函数为:

那么,对于detection_layer的残差就变为:

只需计算每一项的参数训练目标值与网络输出值之差,反向回传即可,与代码对应。其他细节读者请自行分析代码,不再介绍。
5. 结果分析
缩进在论文中,作者给出了YOLO与Fast RCNN检测结果对比,如下图。YOLO对背景的误判率(4.75%)比Fast RCNN的误判率(13.6%)低很多。但是YOLO的定位准确率较差,占总误差比例的19.0%,而fast rcnn仅为8.6%。这说明了YOLO中把检测转化为回归的思路有较好的precision,但是bounding box的定位方法还需要进一步改进。

缩进综上所述,YOLO有如下特点:
- 快。YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单,且训练只需一次完成。
- 背景误检率低。YOLO在训练和推理过程中能“看到”整张图像的整体信息,而基于region proposal的物体检测方法(如Fast RCNN)在检测过程中,只“看到”候选框内的局部图像信息。因此,若当图像背景(非物体)中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体[1]。
- 识别物体位置精准性差,√w和√h策略并没有完全解决location准确度问题。
- 召回率低,尤其是对小目标。
----------------------------------------------------------------------
参考文献:
[1] YOLO详解,赵丽丽, https://zhuanlan.zhihu.com/p/25236464
[2] 论文阅读笔记:You Only Look Once: Unified, Real-Time Object Detection,tangwei2014,http://blog.csdn.NET/tangwei2014/article/details/5091531- CNN目标检测(二):YOLO
- 目标检测与分割(二):YOLO
- 【R-CNN系列目标检测】(5)YOLO算法
- 对目标检测方法yolo的理解 (二)
- 目标检测方法系列:R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 目标检测之YOLO
- [目标检测]YOLO原理
- YOLO:实时目标检测
- 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 目标检测方法系列——R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD
- 【相关知识】目标检测之||R-CNN||SPP-NET ||Fast-RCNN ||Faster-RCNN||YOLO ||SSD
- 目标检测之YOLO算法
- 【深度学习:目标检测】深度学习检测方法梳理:R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列
- CNN目标检测(三):SSD详解
- 目标检测:R-CNN
- cnn目标检测
- 目标检测R-CNN
- 论文 | YOLO(You Only Look Once)目标检测
- Faster-RCNN训练时遇到的问题
- bzoj4773 负环
- C#正则表达式之组与非捕获组浅析 2009-08-20 13:44 chenglidexiaoxue CSDN博客 字号:T | T 一键收藏,随时查看,分享好友! C#正则表达式之组与非捕获组是什么
- CNN目标检测(一):Faster RCNN详解
- R语言读文件
- CNN目标检测(二):YOLO
- C#枚举
- CNN目标检测(三):SSD详解
- 二分图的相关算法
- Vmware提示“内部错误”
- Total Hamming Distance问题及解法
- Faster RCNN解析
- JAVA实现发送邮箱验证码
- Docker容器自启动


