Python 可迭代的对象、迭代器和生成器
来源:互联网 发布:mac合上盖子屏幕亮 编辑:程序博客网 时间:2024/05/22 02:12
迭代是数据处理的基石。扫描内存中放不下的数据集时,我们要找到一种惰性获取数据项的方式,即按需一次获取一个数据项。这就是迭代器模式(Iterator pattern)。
Sentence类第1版:单词序列
我们要实现一个 Sentence 类,以此打开探索可迭代对象的旅程。我们向这个类的构造方法传入包含一些文本的字符串,然后可以逐个单词迭代。第 1 版要实现序列协议,这个类的对象可以迭代,因为所有序列都可以迭代——这一点前面已经说过,不过现在要说明真正的原因。
�� sentence.py:把句子划分为单词序列
1 class Sentence: 2 3 def __init__(self, text): 4 self.text = text #传进来的参数 5 self.words = RE_WORD.findall(self.text) #匹配到的字符编程列表形式 6 7 def __len__(self): #支持查看长度 8 return len(self.words) 9 10 def __getitem__(self, position): #支持索引取值11 return self.words[position]12 13 def __repr__(self): #供程序猿查看的~14 return 'Sentence(%s)' % reprlib.repr(self.text)
注意:
默认情况下,reprlib.repr 函数生成的字符串最多有 30 个字符
以上代码执行的结果为:
>>> s = Sentence('"The time has come," the Walrus said,') # 实例化Sentence并传入需要查找的字符串>>> sSentence('"The time ha... Walrus said,') # __repr__中的reprlib实现的缩写>>> for word in s: # _getitem__实现的可以迭代... print(word)ThetimehascometheWalrussaid>>> list(s) # 转换成列表['The', 'time', 'has', 'come', 'the', 'Walrus', 'said']
序列可以迭代的原因:iter函数
解释器需要迭代对象 x 时,会自动调用 iter(x)。
内置的 iter 函数有以下作用。
(1) 检查对象是否实现了 __iter__ 方法,如果实现了就调用它,获取一个迭代器。
(2) 如果没有实现 __iter__ 方法,但是实现了 __getitem__ 方法,Python 会创建一个迭代器,尝试按顺序(从索引 0 开始)获取元素。
(3) 如果尝试失败,Python 抛出 TypeError 异常,通常会提示“C objectis not iterable”(C 对象不可迭代),其中 C 是目标对象所属的类。
任何 Python 序列都可迭代的原因是,它们都实现了 __getitem__ 方法。其实,标准的序列也都实现了 __iter__ 方法,因此你也应该这么做
这是鸭子类型(duck typing)的极端形式:不仅要实现特殊的 __iter__ 方法,还要实现 __getitem__ 方法,而且__getitem__ 方法的参数是从 0 开始的整数(int),这样才认为对象是可迭代的。
在白鹅类型(goose-typing)理论中,可迭代对象的定义简单一些,不过没那么灵活:如果实现了 __iter__ 方法,那么就认为对象是可迭代的。此时,不需要创建子类,也不用注册,因为 abc.Iterable 类实现了 __subclasshook__ 方法,请看下面的 ��
>>> class Foo:... def __iter__(self):... pass... >>> f = Foo()>>> from collections import abc>>> issubclass(Foo, abc.Iterable)True>>> isinstance(f, abc.Iterable)True
可迭代的对象与迭代器的对比
可迭代的对象
使用 iter 内置函数可以获取迭代器的对象。如果对象实现了能返回迭代器的 __iter__ 方法,那么对象就是可迭代的。序列都可以迭代;实现了 __getitem__ 方法,而且其参数是从零开始的索引,这种对象也可以迭代。
�� 下面是一个简单的 for 循环,迭代一个字符串。这里,字符串 'ABC'是可迭代的对象。背后是有迭代器的,只不过我们看不到:
>>> s = 'demon'>>> for char in s:... print(char)... demon
如果没有 for 语句,不得不使用 while 循环模拟,要像下面这样写:
1 s = 'demon'2 it = iter(s) #使用迭代器迭代s字符串3 4 while True:5 try:6 print(next(it)) #调用next等通过从iter中获取值7 except StopIteration: #当迭代器中的所有数据都迭代完毕以后,会报StopIteration的异常8 del it9 break #删除迭代器并跳出循环体
标准的迭代器接口有两个方法。
__next__
返回下一个可用的元素,如果没有元素了,抛出 StopIteration异常。
__iter__
返回 self,以便在应该使用可迭代对象的地方使用迭代器,例如在 for 循环中。
这个接口在 collections.abc.Iterator 抽象基类中制定。这个类定义了 __next__ 抽象方法,而且继承自 Iterable 类;__iter__ 抽象方法则在 Iterable 类中定义。如图所示。
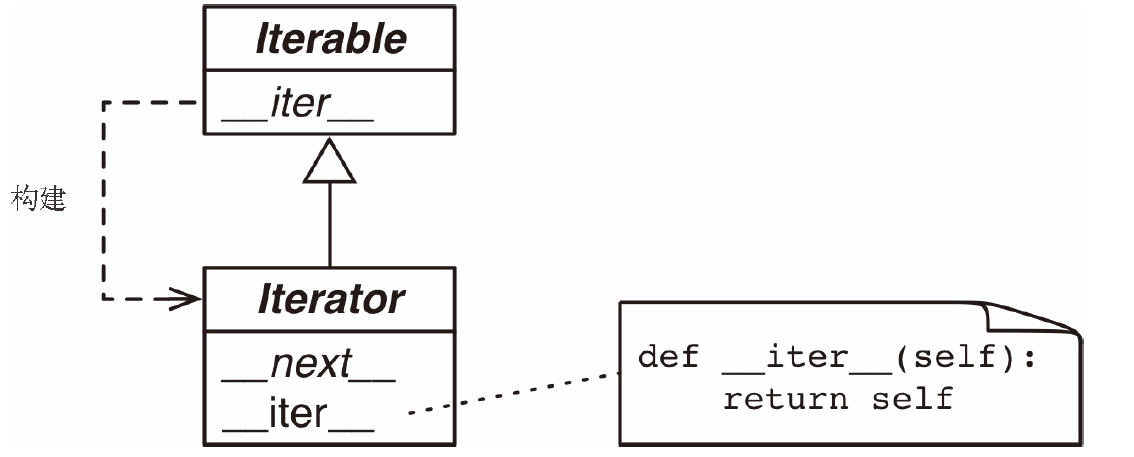
Iterable 和 Iterator 抽象基类。以斜体显示的是抽象方法。具体的 Iterable.__iter__ 方法应该返回一个 Iterator 实例。具体的 Iterator 类必须实现 __next__ 方法。Iterator.__iter__ 方法直接返回实例本身。
看下面的 ��
1 import re 2 import reprlib 3 4 RE_WORD = re.compile(r'\w+') #需要匹配的正则 5 6 class Sentence: 7 8 def __init__(self, text): 9 self.text = text #传进来的参数10 self.words = RE_WORD.findall(self.text) #匹配到的字符编程列表形式11 12 def __len__(self): #支持查看长度13 return len(self.words)14 15 def __getitem__(self, position): #支持索引取值16 return self.words[position]17 18 def __repr__(self): #供程序猿查看的~19 return 'Sentence(%s)' % reprlib.repr(self.text)20 21 s3 = Sentence('Pig and Pepper') #实例化22 it = iter(s3) #从s3中获取迭代器的内容23 print('iter迭代器:', it) #打印迭代器24 print(next(it)) #获取迭代器25 print(next(it))26 print(next(it))27 #print(next(it)) #迭代器里面的内容已经空了,在取就会报错了,StopIteration28 print('s3变成序列:', list(it)) #把s3实例变成序列,因为迭代器内容没有了,所以是空列表29 print('s3重新获取序列:', list(iter(s3)))
因为迭代器只需__next__ 和 __iter__两个方法,所以除了调用next() 方法,以及捕获 StopIteration 异常之外,没有办法检查是否还有遗留的元素。此外,也没有办法“还原”迭代器。如果想再次迭代,那就要调用 iter(...),传入之前构建迭代器的可迭代对象。传入迭代器本身没用,因为前面说过 Iterator.__iter__ 方法的实现方式是返回实例本身,所以传入迭代器无法还原已经耗尽的迭代器。
Sentence类第2版:典型的迭代器
Sentence 类可以迭代,因为它实现了特殊的__iter__ 方法,构建并返回一个 SentenceIterator 实例。《设计模式:可复用面向对象软件的基础》一书就是这样描述迭代器设计模式的。这里之所以这么做,是为了清楚地说明可迭代的对象和迭代器之间的重要区别,以及二者之间的联系。
sentence_iter.py:使用迭代器模式实现 Sentence 类
1 import re 2 import reprlib 3 4 RE_WORD = re.compile(r'\w+') 5 6 7 class Sentence: 8 9 def __init__(self, text):10 self.text = text11 self.words = RE_WORD.findall(self.text)12 13 def __repr__(self):14 return 'Sentence(%s)' % reprlib.repr(self.text)15 16 def __iter__(self): #可以迭代17 return SentenceIterator(self.words) #返回一个迭代器18 19 20 class SentenceIterator:21 22 def __init__(self, words): #SentenceIterator 实例引用单词列表23 self.words = words24 self.index = 0 #self.index 用于确定下一个要获取的单词25 26 def __next__(self):27 try:28 word = self.words[self.index] #获取 self.index 索引位上的单词29 except IndexError: #获取的索引上没有值,就代表迭代器闷得蜜了吧~30 raise StopIteration() #结束了,当然是抛出StopIteration的异常咯31 self.index += 1 #要么就让索引自动+1供下次迭代器调用使用32 return word #返回索引上面的值33 34 def __iter__(self): #实现__iter__方法35 return self
注意,对这个示例来说,其实没必要在 SentenceIterator 类中实现__iter__ 方法,不过这么做是对的,因为迭代器应该实现 __next__和 __iter__ 两个方法,而且这么做能让迭代器通过issubclass(SentenceInterator, abc.Iterator) 测试。如果让SentenceIterator 类继承 abc.Iterator 类,那么它会继承abc.Iterator.__iter__ 这个具体方法。
把Sentence变成迭代器:坏主意
构建可迭代的对象和迭代器时经常会出现错误,原因是混淆了二者。要知道,可迭代的对象有个 __iter__ 方法,每次都实例化一个新的迭代器;而迭代器要实现 __next__ 方法,返回单个元素,此外还要实现__iter__ 方法,返回迭代器本身。
除了 __iter__ 方法之外,你可能还想在 Sentence 类中实现__next__ 方法,让 Sentence 实例既是可迭代的对象,也是自身的迭代器。可是,这种想法非常糟糕。根据有大量 Python 代码审查经验的Alex Martelli 所说,这也是常见的反模式。
迭代器模式可用来:
访问一个聚合对象的内容而无需暴露它的内部表示
支持对聚合对象的多种遍历
为遍历不同的聚合结构提供一个统一的接口(即支持多态迭代)为了“支持多种遍历”,必须能从同一个可迭代的实例中获取多个独立的迭代器,而且各个迭代器要能维护自身的内部状态,因此这一模式正确的实现方式是,每次调用 iter(my_iterable) 都新建一个独立的迭代器。这就是为什么这个示例需要定义 SentenceIterator 类。
Sentence类第3版:生成器函数实
实现相同功能,但却符合 Python 习惯的方式是,用生成器函数代替SentenceIterator 类
sentence_gen.py:使用生成器函数实现 Sentence 类
1 import re 2 import reprlib 3 4 RE_WORD = re.compile(r'\w+') 5 6 7 class Sentence: 8 9 def __init__(self, text):10 self.text = text11 self.words = RE_WORD.findall(self.text)12 13 def __repr__(self):14 return 'Sentence(%s)' % reprlib.repr(self.text)15 16 def __iter__(self):17 for word in self.words: #迭代self.words18 yield word #产出当前的word19 return #这个 return 语句不是必要的;这个函数可以直接“落空”,自动返回。20 #不管有没有 return 语句,生成器函数都不会抛出 StopIteration
生成器函数的工作原理
只要 Python 函数的定义体中有 yield 关键字,该函数就是生成器函数。调用生成器函数时,会返回一个生成器对象。也就是说,生成器函数是生成器工厂。
注意:
普通的函数与生成器函数在句法上唯一的区别是,在后者的定义体中有 yield 关键字。有些人认为定义生成器函数应该使用一个新的关键字,例如 gen,而不该使用 def。
举个�� 下面一个特别简单的函数说明生成器的行为:
1 def gen_123(): 2 yield 1 3 yield 2 4 yield 3 5 6 7 print('gen_123是个函数', gen_123) 8 print('gen_123调用的时候是个生成器', gen_123()) 9 10 for i in gen_123():11 print(i)12 13 g = gen_123()14 print('使用next来一发', next(g))15 print('使用next来二发', next(g))16 print('使用next来三发', next(g))17 try:18 next(g)19 except StopIteration:20 print('报错哦,迭代器结束咯~')21 else:22 print('啊啊啊啊啊~~官人,好疼呀!')
以上代码执行的结果为:
gen_123是个函数 <function gen_123 at 0x100562e18> gen_123调用的时候是个生成器<generator object gen_123 at 0x102146308> 1 2 3 使用next来一发1 使用next来二发 2 使用next来三发3 报错哦,迭代器里面没有值了~
生成器函数会创建一个生成器对象,包装生成器函数的定义体。把生成器传给 next(...) 函数时,生成器函数会向前,执行函数定义体中的下一个 yield 语句,返回产出的值,并在函数定义体的当前位置暂停。最终,函数的定义体返回时,外层的生成器对象会抛出StopIteration 异常——这一点与迭代器协议一致。
1 def gen_AB(): #定义一个生成器,为毛线是生成器,因为有yield呀 2 print('Start') 3 yield 'A' #for循环第一次隐式调用next(gen_AB())函数时候,会打印Start,然后停止在第一个yield上产出 4 print('Continue') 5 yield 'B' #for循环第二次隐式调用next...产出B 6 print('End.') 7 8 9 for i in gen_AB():10 print('--->', i) #每次隐式调用的yield的值
以上代码执行的结果:
Start---> AContinue---> BEnd.
Sentence类第4版:惰性实现
设计 Iterator 接口时考虑到了惰性:next(my_iterator) 一次生成一个元素。懒惰的反义词是急迫,其实,惰性求值(lazy evaluation)和及早求值(eager evaluation)是编程语言理论方面的技术术语。
目前实现的几版 Sentence 类都不具有惰性,因为 __init__ 方法急迫地构建好了文本中的单词列表,然后将其绑定到 self.words 属性上。这样就得处理整个文本,列表使用的内存量可能与文本本身一样多(或许更多,这取决于文本中有多少非单词字符)。如果只需迭代前几个单词,大多数工作都是白费力气。
sentence_gen2.py: 在生成器函数中调用 re.finditer生成器函数,实现 Sentence 类
1 class Sentence: 2 3 def __init__(self, text): 4 self.text = text 5 self.words = RE_WORD.finditer(self.text) #惰性的,省内存哦~ 生成器哦 6 7 def __repr__(self): 8 return 'Sentence(%s)' % reprlib.repr(self.text) 9 10 def __iter__(self):11 for match in self.words:12 yield match.group() #产出数据13 return
Sentence类第5版:生成器表达式
简单的生成器函数,如前面的 Sentence 类中使用的那个,可以替换成生成器表达式。
生成器表达式可以理解为列表推导的惰性版本:不会迫切地构建列表,而是返回一个生成器,按需惰性生成元素。也就是说,如果列表推导是制造列表的工厂,那么生成器表达式就是制造生成器的工厂。
先在列表推导中使用 gen_AB 生成器函数,然后在生成器表达式中使用
>>> def gen_AB(): #生成器... print('start')... yield 'A'... print('continue')... yield 'B'... print('end.')... >>> res1 = [x*3 for x in gen_AB()] #列表推倒式startcontinueend.>>> for i in res1:... print('--->', i) #隐式调用,获取yield的产出的值... ---> AAA---> BBB>>> res2 = (x*3 for x in gen_AB()) #直接使用生成器>>> res2<generator object <genexpr> at 0x102ad25c8>>>> for i in res2: #循环输出生成器的结果... print('--->', i)... start---> AAAcontinue---> BBBend.
sentence_genexp.py:使用生成器表达式实现 Sentence类
1 import re 2 import reprlib 3 4 RE_WORD = re.compile(r'\w+') 5 6 7 class Sentence: 8 9 def __init__(self, text):10 self.text = text11 12 def __repr__(self):13 return 'Sentence(%s)' % reprlib.repr(self.text)14 15 def __iter__(self):16 return (match.group() for match in RE_WORD.finditer(self.text))
这里不是生成器函数了(没有 yield),而是使用生成器表达式构建生成器,然后将其返回。不过,最终的效果一样:调用 __iter__ 方法会得到一个生成器对象。
何时使用生成器表达式
生成器表达式是创建生成器的简洁句法,这样无需先定义函数再调用。不过,生成器函数灵活得多,可以使用多个语句实现复杂的逻辑,也可以作为协程使用,遇到简单的情况时,可以使用生成器表达式,因为这样扫一眼就知道代码的作用。
另一个示例:等差数列生成器
典型的迭代器模式作用很简单——遍历数据结构。不过,即便不是从集合中获取元素,而是获取序列中即时生成的下一个值时,也用得到这种基于方法的标准接口。例如,内置的 range 函数用于生成有穷整数等差数列(Arithmetic Progression,AP),itertools.count 函数用于生成无穷等差数列。
下面我们在控制台中对稍后实现的 ArithmeticProgression 类做一些测试,如 �� 所示。这里,构造方法的签名是ArithmeticProgression(begin, step[, end])。range() 函数与这个 ArithmeticProgression 类的作用类似,不过签名是range(start, stop[, step])。我选择使用不同的签名是因为,创建等差数列时必须指定公差(step),而末项(end)是可选的。我还把参数的名称由 start/stop 改成了 begin/end,以明确表明签名不同。在示例 �� 里的每个测试中,我都调用了 list() 函数,用于查看生成的值。
�� ArithmeticProgression 类
1 class ArithmeticProgression: 2 3 def __init__(self, begin, step, end=None): #__init__ 方法需要两个参数:begin和step。end是可选的,如果值是None,那么生成的是无穷数列 4 self.begin = begin 5 self.step = step 6 self.end = end #None -> 无穷数列 7 8 def __iter__(self): 9 result = type(self.begin + self.step)(self.begin) #强制转换成前面的类型,并把self.begin的值赋给result10 forver = self.end is None11 index = 012 while forver or result < self.end: #如果forver是None就一直循环下去或者当result得结果大于传递进来的end的值13 yield result #产出result的值14 index += 115 result = self.begin + self.step * index
演示 ArithmeticProgression 类的用法
>>> ap = ArithmeticProgression(0, 1, 3)>>> list(ap)[0, 1, 2]>>> ap = ArithmeticProgression(1, .5, 3)>>> list(ap)[1.0, 1.5, 2.0, 2.5]>>> ap = ArithmeticProgression(0, 1/3, 1)>>> list(ap)[0.0, 0.3333333333333333, 0.6666666666666666]>>> from fractions import Fraction>>> ap = ArithmeticProgression(0, Fraction(1, 3), 1)>>> list(ap)[Fraction(0, 1), Fraction(1, 3), Fraction(2, 3)]>>> from decimal import Decimal>>> ap = ArithmeticProgression(0, Decimal('.1'), .3)>>> list(ap)[Decimal('0.0'), Decimal('0.1'), Decimal('0.2')]
注意,在得到的等差数列中,数字的类型与 begin 或 step 的类型一致。如果需要,会根据 Python 算术运算的规则强制转换类型
aritprog_gen 生成器函数
1 def aritprog_gen(begin, step, end=None):2 result = type(begin + step)(begin)3 forever = end is None4 index = 05 while forever or result < end:6 yield result7 index += 18 result = begin + step * index
使用itertools模块生成等差数列
Python 3.4 中的 itertools 模块提供了 19 个生成器函数,结合起来使用能实现很多有趣的用法
例如,itertools.count 函数返回的生成器能生成多个数。如果不传入参数,itertools.count 函数会生成从零开始的整数数列。不过,我们可以提供可选的 start 和 step 值,这样实现的作用与aritprog_gen 函数十分相似:
>>> import itertools>>> gen = itertools.count(1, .5)>>> next(gen)1 >>> next(gen)1.5>>> next(gen)2.0>>> next(gen)2.5
然而,itertools.count 函数从不停止,因此,如果调用list(count()),Python 会创建一个特别大的列表,超出可用内存,在调用失败之前,电脑会疯狂地运转。
不过,itertools.takewhile 函数则不同,它会生成一个使用另一个生成器的生成器,在指定的条件计算结果为 False 时停止。因此,可以把这两个函数结合在一起使用,编写下述代码:
>>> gen = itertools.takewhile(lambda n:n<3, itertools.count(1, .5))>>> list(gen)[1, 1.5, 2.0, 2.5]
aritprog_v3.py:与前面的 aritprog_gen 函数作用相同
1 import itertools2 3 4 def aritprog_gen(begin, step, end=None):5 first = type(begin + step)(begin)6 ap_gen = itertools.count(first, step)7 if end is not None:8 ap_gen = itertools.takewhile(lambda n: n < end, ap_gen)9 return ap_gen
标准库中的生成器函数
标准库提供了很多生成器,有用于逐行迭代纯文本文件的对象,还有出色的 os.walk 函(https://docs.python.org/3/library/os.html#os.walk)。这个函数在遍历目录树的过程中产出文件名,因此递归搜索文件系统像for 循环那样简单。
第一组是用于过滤的生成器函数:从输入的可迭代对象中产出元素的子集,而且不修改元素本身。与 takewhile 函数一样。大多数函数都接受一个断言参数(predicate)。这个参数是个布尔函数,有一个参数,会应用到输入中的每个元素上,用于判断元素是否包含在输出中。
用于过滤的生成器函数
模块
函数
说明
itertools
compress(it, selector_it)
并行处理两个可迭代的对象;如果selector_it中的元素是真值,产出it中对应的元素
itertools
dropwhile(predicate, it)
处理 it,跳过predicate的计算结果为真值得元素,然后产出剩下的各个元素(不在进行检查)
(内置)
filter(predicate,it)
把 it 中的各个元素传给predicate,如果predicate(item) 返回真值,那么产出对应的元素;如果predicate是None,那么只产出真值元素
itertools
filterfalse(predicate, it)
与 filter 函数的作用类似,不过 predicate 的逻辑是相反的; predicate 返回假值时产出对应的元素
itertools
islice(it, stop) 或 islice(it , start , stop , step=1)
产出 it 的切片,作用类似于s[:stop]或s[satrt:stop:step],不过 it 可以任何可迭代的对象,而且这个函数实现的是惰性操作
itertools
takewhile(predicate, it)
predicate 返回真值时产出对象的元素,然后立即停止,不在进行检查
演示用于过滤的生成器函数
>>> def vowel(c):... return c.lower() in 'aeiou'... >>> list(filter(vowel, 'Aardvark'))['A', 'a', 'a']>>> import itertools>>> list(itertools.filterfalse(vowel, 'Aardvark'))['r', 'd', 'v', 'r', 'k']>>> list(itertools.dropwhile(vowel, 'Aardvark'))['r', 'd', 'v', 'a', 'r', 'k']>>> list(itertools.takewhile(vowel, 'Aardvark'))['A', 'a']>>> list(itertools.compress('Aardvark', (1,0,1,1,0,1)))['A', 'r', 'd', 'a']>>> list(itertools.islice('Aardvark', 4))['A', 'a', 'r', 'd']>>> list(itertools.islice('Aardvark', 4, 7))['v', 'a', 'r']>>> list(itertools.islice('Aardvark', 1, 7, 2))['a', 'd', 'a']
下一组是用于映射的生成器函数:在输入的单个可迭代对象(map 和starmap 函数处理多个可迭代的对象)中的各个元素上做计算,然后返回结果。 表中的生成器函数会从输入的可迭代对象中的各个元素中产出一个元素。如果输入来自多个可迭代的对象,第一个可迭代的对象到头后就停止输出。
用于映射的生成器函数
模块
函数
说明
itertools
accumulate(it, [func])
产出累积的总和;如果提供了 func,那么吧前面元素传给它,然后把计算结果和下一个元素传给它,以此类推,最后产出结果
(内置)
enumerate(iterable, start=0)
产出由两个元素组成的元组,结构是(index, item),其中index和 start 开始计数,item则从 iterable 中获取
(内置)
map(func, it1, [it2, ...,itN]
把 it 中的哥哥元素传给fun,产出结果,如果传入N个可迭代的对象,那么 func 必须能够接受N个参数,并且要并行处理各个可迭代的对象
itertools
starmap(func, it)
把 it 中的哥哥元素传给func,产出结果;输入的课迭代对象应该产出可迭代的元素iit, 然后以func(*iit) 这种形式调用func
演示 itertools.accumulate 生成器函数
>>> sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1]>>> import itertools>>> list(itertools.accumulate(sample)) # 计算总和[5, 9, 11, 19, 26, 32, 35, 35, 44, 45]1212>>> list(itertools.accumulate(sample, min)) # 计算最小值,因为传递了函数,所以两个数对比,把最新的取到和后一个一起在传递给函数[5, 4, 2, 2, 2, 2, 2, 0, 0, 0]>>> list(itertools.accumulate(sample, max)) # 计算最大值,原理同上[5, 5, 5, 8, 8, 8, 8, 8, 9, 9]>>> import operator>>> list(itertools.accumulate(sample, operator.mul)) # 计算乘积[5, 20, 40, 320, 2240, 13440, 40320, 0, 0, 0]>>> list(itertools.accumulate(range(1, 11), operator.mul))[1, 2, 6, 24, 120, 720, 5040, 40320, 362880, 3628800] # 计算1!到10!阶乘
演示用于映射的生成器函数
>>> list(enumerate('albatroz', 1)) # enumerate如果不给最后一位,会从0开始,给了数字会从数字开始,这里就是从1开始[(1, 'a'), (2, 'l'), (3, 'b'), (4, 'a'), (5, 't'), (6, 'r'), (7, 'o'), (8, 'z')]>>> import operator>>> list(map(operator.mul, range(11), range(11))) # 计算各个整数的平方[0, 1, 4, 9, 16, 25, 36, 49, 64, 81, 100]>>> list(map(operator.mul, range(11), [2, 4, 8])) # 计算两个可迭代对象中对应位置上的两个元素之积,元素最少的那个可迭代对象到头后就停止[0, 4, 16]>>> list(map(lambda a, b: (a, b), range(11), [2, 4, 8])) # 等同于zip的用法[(0, 2), (1, 4), (2, 8)]>>> import itertools>>> list(itertools.starmap(operator.mul, enumerate('albatroz', 1))) # 从1开始,根据字母所在的位置,吧字母重复相应的次数['a', 'll', 'bbb', 'aaaa', 'ttttt', 'rrrrrr', 'ooooooo', 'zzzzzzzz']>>> sample = [5, 4, 2, 8, 7, 6, 3, 0, 9, 1]>>> list(itertools.starmap(lambda a, b: b/a,... enumerate(itertools.accumulate(sample), 1))) # 计算平均值[5.0, 4.5, 3.6666666666666665, 4.75, 5.2, 5.333333333333333,5.0, 4.375, 4.888888888888889, 4.5]
接下来这一组是用于合并的生成器函数,这些函数都从输入的多个可迭代对象中产出元素。chain 和 chain.from_iterable 按顺序(一个接一个)处理输入的可迭代对象,而 product、zip 和 zip_longest 并行处理输入的各个可迭代对象。
合并多个可迭代对象的生成器函数
模块
函数
说明
itertools
chain(it1,.....,itN)
先产出 it1 中的所有元素,然后产出 it2 中的所有元素,以此类推,无缝连接到一起
itertools
chain.from_iterable(it)
产出 it 生成的各个可迭代对象中的元素,一个接一个,无缝连接在一起;it 应该产出可迭代的元素,例如可迭代的对象列表
itertools
product(it1, ..., itN, repeat=1)
计算笛卡儿积:从输入的各个可迭代对象中获取元素,合并成由 N 个元素组成的元祖,与嵌套的 for 循环的效果一样,repeat知名重复处理多少次输入的可迭代对象
(内置)
zip(it1, ..., itN)
并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元祖,只要有一个可迭代的对象到头了,就默默地停止
itertools
zip_longest(it1, ...,itN, fillvalue=None)
并行从输入的各个可迭代对象中获取元素,产出由 N 个元素组成的元组,等到最长的可迭代对象到头后才停止,空缺的值使用 fillvalue 填充
展示 itertools.chain 和 zip 生成器函数及其同胞的用法。再次提醒,zip 函数的名称出自 zip fastener 或 zipper(拉链,与ZIP 压缩没有关系)。“出色的 zip 函数”附注栏介绍过 zip 和itertools.zip_longest 函数。
演示用于合并的生成器函数
>>> list(itertools.chain('ABC', range(2))) # 调用chain函数时通常掺入两个或更多个可迭代的对象['A', 'B', 'C', 0, 1]>>> list(itertools.chain(enumerate('ABC'))) # 如果只传入一个可迭代的对象,那么chain函数并无卵用[(0, 'A'), (1, 'B'), (2, 'C')]>>> list(itertools.chain.from_iterable(enumerate('ABC'))) # 但是chain.from_iterable函数从可迭代的对象中获取每个元素,然后按顺序把元素连接起来[0, 'A', 1, 'B', 2, 'C']>>> list(zip('ABC', range(5))) # zip常用于把两个可迭代的对象合并成一系列由两个元素组成的元祖[('A', 0), ('B', 1), ('C', 2)]>>> list(zip('ABC', range(5), [10, 20, 30, 40])) # zip可以并行处理任意数量个可迭代的对象,不过只要有一个可迭代的对象到头,生成器就停止[('A', 0, 10), ('B', 1, 20), ('C', 2, 30)]>>> list(itertools.zip_longest('ABC', range(5))) # itertools.zip_logest函数的作用与zip类似,不过输入的所有可迭代对象都会处理到头,如果需要会填充None[('A', 0), ('B', 1), ('C', 2), (None, 3), (None, 4)]>>> list(itertools.zip_longest('ABC', range(5), fillvalue='?')) # fillvalue 关键字参数用于指定填充的值[('A', 0), ('B', 1), ('C', 2), ('?', 3), ('?', 4)]
itertools.product 生成器是计算笛卡儿积的惰性方式;我们在多个 for 子句中使用列表推导计算过笛卡儿积。此外,也可以使用包含多个 for 子句的生成器表达式,以惰性方式计算笛卡儿积。
>>> list(itertools.product('ABC', range(2))) # 三个字符的字符串与两个整数的值域得到的笛卡尔积是六个元祖[('A', 0), ('A', 1), ('B', 0), ('B', 1), ('C', 0), ('C', 1)]>>> suits = 'spades hearts diamonds clubs'.split()>>> list(itertools.product('AK', suits)) # 两张牌('AK')与四中花色得到的笛卡尔积是八个元祖[('A', 'spades'), ('A', 'hearts'), ('A', 'diamonds'), ('A', 'clubs'),('K', 'spades'), ('K', 'hearts'), ('K', 'diamonds'), ('K', 'clubs')]>>> list(itertools.product('ABC')) # 如果传入一个可迭代的对象,product函数产出的是一系列只有一个元素的元祖,并没有什么卵用~[('A',), ('B',), ('C',)]>>> list(itertools.product('ABC', repeat=2)) # repeat=N 关键字参数告诉 product 函数重复 N 次处理输入的各个可迭代对象 [('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'),('B', 'C'), ('C', 'A'), ('C', 'B'), ('C', 'C')]>>> list(itertools.product(range(2), repeat=3))[(0, 0, 0), (0, 0, 1), (0, 1, 0), (0, 1, 1), (1, 0, 0),(1, 0, 1), (1, 1, 0), (1, 1, 1)]>>> rows = itertools.product('AB', range(2), repeat=2)>>> for row in rows: print(row)...('A', 0, 'A', 0)('A', 0, 'A', 1)('A', 0, 'B', 0)('A', 0, 'B', 1)('A', 1, 'A', 0)('A', 1, 'A', 1)('A', 1, 'B', 0)('A', 1, 'B', 1)('B', 0, 'A', 0)('B', 0, 'A', 1)('B', 0, 'B', 0)('B', 0, 'B', 1)('B', 1, 'A', 0)('B', 1, 'A', 1)('B', 1, 'B', 0)('B', 1, 'B', 1)
生成器函数会从一个元素中产出多个值,扩展输入的可迭代对象,如表
把输入的各个元素扩展成多个输出元素的生成器函数
模块
函数
说明
itertools
combinations(it, out_len)
把 it 产出的 out_len 个元素组合在一起,然后产出
itertools
combinations_with_replacement(it, out_len)
把 it 产出的 out_len 个元素组合在一起,然后产出,包含相同元素的组合
itertools
count(start=0, step=1)
从 start 开始不断产出数字,按 step 指定的步幅增加
itertools
cycle(it)
从 it 中产出各个元素,村粗各个元素的副本,然后按顺序重复不断产出各个元素
itertools
permutations(it, out_len=None)
把 out_len 个 it 产出的元素排列在一起,然后产出这些排列;out_len的默认值等于len(list(it))
itertools
repeat(item, [times])
重复不断地产出指定的元素,除非提供 times,指定次数
itertools 模块中的 count 和 repeat 函数返回的生成器“无中生有”:这两个函数都不接受可迭代的对象作为输入。cycle 生成器会备份输入的可迭代对象,然后重复产出对象中的元素
演示 count、repeat 和 cycle 的用法
>>> ct = itertools.count() # 使用count函数构建ct生成器>>> next(ct) # 获取ct的第一个元素0 >>> next(ct), next(ct), next(ct) # 不能使用ct构建列表,因为ct是无穷的,所以我获取了接下来的3个元素(1, 2, 3)>>> list(itertools.islice(itertools.count(1, .3), 3)) # 如果使用 islice 或者 takewhile 函数做了限制,可以从count生成器中构建列表[1, 1.3, 1.6]>>> cy = itertools.cycle('ABC') # 使用 'ABC' 构建一个cycle生成器,然后获取第一个元素'A' >>> next(cy)'A'>>> list(itertools.islice(cy, 7)) # 只有受到islice函数的限制,才能构建列表;这里获取接下来的7个元素['B', 'C', 'A', 'B', 'C', 'A', 'B']>>> rp = itertools.repeat(7) # 构建一个 repeat 生成器,始终产生数字 7 >>> next(rp), next(rp)(7, 7)>>> list(itertools.repeat(8, 4)) # 传入 times 参数可以限制repeat 生成器生成的元素数量,这里会生成4次数字8[8, 8, 8, 8]>>> list(map(operator.mul, range(11), itertools.repeat(5))) # ➒ repeat 函数最常见用途:为 map 函数提供固定参数,这里提供的是乘数 5 [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
在 itertools 模块的文档中(https://docs.python.org/3/library/itertools.html),combinations、combinations_和 permutations 生成器函数,连同 product 函数,称为组合学生成器(combinatoric generator)。itertools.product 函数和其余的组合学函数有紧密的联系。
组合学生成器函数会从输入的各个元素中产出多个值
>>> list(itertools.combinations('ABC', 2)) # 'ABC' 中每个元素(len()==2) 的各种组合,在生成的元素中元素的顺序无关紧要(可以视为集合)[('A', 'B'), ('A', 'C'), ('B', 'C')]>>> list(itertools.combinations_with_replacement('ABC', 2)) # 'ABC'中每个元素(len()==2) 的各种组合,包括相同元素的组合[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'B'), ('B', 'C'), ('C', 'C')]>>> list(itertools.permutations('ABC', 2)) # 'ABC' 中每两个元素(len()==2)的各种排列;在生成的元祖中,元素的顺序有重要意义[('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'C'), ('C', 'A'), ('C', 'B')]>>> list(itertools.product('ABC', repeat=2)) # 'ABC' 和 'ABC' (repeat=2 的效果)的笛卡尔积[('A', 'A'), ('A', 'B'), ('A', 'C'), ('B', 'A'), ('B', 'B'), ('B', 'C'),('C', 'A'), ('C', 'B'), ('C', 'C')]
最后一组生成器函数用于产出输入的可迭代对象中的全部元素,不过会以某种方式重新排列。其中有两个函数会返回多个生成器,分别是 itertools.groupby 和 itertools.tee。这一组里的另一个生成器函数,内置的 reversed 函数,是所述的函数中唯一一个不接受可迭代的对象,而只接受序列为参数的函数。这在情理之中,因为reversed 函数从后向前产出元素,而只有序列的长度已知时才能工作。不过,这个函数会按需产出各个元素,因此无需创建反转的副本。
用于重新排列元素的生成器函数
模块
函数
说明
itertools
groupby(it,key=None)
产出由两个元素组成的元素,形式为 (key,group),其中 key 是分组标准, group 是生成器,用于产出分组里的元素
(内置)
reversed(seq)
从后向前,倒序产出 seq 中的元素;seq 必须是序列,或者是实现了__reversed__特殊方法的对象
itertools
tee(it, n=2)
产出一个由 n 个生成器组成的元祖,每个生成器用于单独产出输入的可迭代对象中的元素
演示 itertools.groupby 函数和内置的 reversed 函数的用法。注意,itertools.groupby 假定输入的可迭代对象要使用分组标准排序;即使不排序,至少也要使用指定的标准分组各个元素。
itertools.groupby 函数的用法
>>> list(itertools.groupby('LLLLAAGGG')) # ➊ groupby函数产出(key, group_generator)这种形式的元祖[('L', <itertools._grouper object at 0x102227cc0>),('A', <itertools._grouper object at 0x102227b38>),('G', <itertools._grouper object at 0x102227b70>)]>>> for char, group in itertools.groupby('LLLLAAAGG'): # 处理 groupby 函数返回的生成器要嵌套迭代;这里在外城使用 for 循环,内层使用列表推导式... print(char, '->', list(group))...L -> ['L', 'L', 'L', 'L']A -> ['A', 'A',]G -> ['G', 'G', 'G']>>> animals = ['duck', 'eagle', 'rat', 'giraffe', 'bear',... 'bat', 'dolphin', 'shark', 'lion']>>> animals.sort(key=len) # 为了使用groupby函数,要排序输入;这里按照单词的长度排序>>> animals['rat', 'bat', 'duck', 'bear', 'lion', 'eagle', 'shark','giraffe', 'dolphin']>>> for length, group in itertools.groupby(animals, len): # 再次遍历 key 和 group 值对,把 key 显示出来,并把 group 扩展成列表... print(length, '->', list(group))...3 -> ['rat', 'bat']4 -> ['duck', 'bear', 'lion']5 -> ['eagle', 'shark']7 -> ['giraffe', 'dolphin']>>> for length, group in itertools.groupby(reversed(animals), len): # 这里使用 reverse 生成器从右向左迭代 animals... print(length, '->', list(group))...7 -> ['dolphin', 'giraffe']5 -> ['shark', 'eagle']4 -> ['lion', 'bear', 'duck']3 -> ['bat', 'rat']
这一组里的最后一个生成器函数是 iterator.tee,这个函数只有一个作用:从输入的一个可迭代对象中产出多个生成器,每个生成器都可以产出输入的各个元素。
>>> list(itertools.tee('ABC'))[<itertools._tee object at 0x10222abc8>, <itertools._tee object at 0x10222ac08>]>>> g1, g2 = itertools.tee('ABC')>>> next(g1)'A'>>> next(g2)'A'>>> next(g2)'B'>>> list(g1)['B', 'C']>>> list(g2)['C']>>> list(zip(*itertools.tee('ABC')))[('A', 'A'), ('B', 'B'), ('C', 'C')]
Python 3.3中新出现的句法:yieldfrom
如果生成器函数需要产出另一个生成器生成的值,传统的解决方法是使用嵌套的 for 循环。
例如,下面是我们自己实现的 chain 生成器:
>>> def chain(*iterable):... for it in iterable:... for i in it:... yield i... >>> s = 'ABC'>>> t = tuple(range(3))>>> list(chain(s, t))['A', 'B', 'C', 0, 1, 2]
chain 生成器函数把操作依次交给接收到的各个可迭代对象处理。为此,“PEP 380 — Syntax for Delegating to a Subgenerator”引入了一个新句法,如下述控制台中的代码清单所示:
1 def chain(*iterable):2 for i in iterable:3 yield from i4 5 s = 'ABC'6 t = tuple(range(3))7 8 print(list(chain(s, t)))
可以看出,yield from i 完全代替了内层的 for 循环。在这个示例中使用 yield from 是对的,而且代码读起来更顺畅,不过感觉更像是语法糖。除了代替循环之外,yield from 还会创建通道,把内层生成器直接与外层生成器的客户端联系起来。把生成器当成协程使用时,这个通道特别重要,不仅能为客户端代码生成值,还能使用客户端代码提供的值。
可迭代的归约函数
表中的函数都接受一个可迭代的对象,然后返回单个结果。这些函数叫“归约”函数、“合拢”函数或“累加”函数。其实,这里列出的每个内置函数都可以使用 functools.reduce 函数实现,内置是因为使用它们便于解决常见的问题。此外,对 all 和 any 函数来说,有一项重要的优化措施是 reduce 函数做不到的:这两个函数会短路(即一旦确定了结果就立即停止使用迭代器)
读取迭代器,返回单个值的内置函数
模块
函数
说明
(内置)
all(it)
it 中的所有元素都为真时返回True,否则就返回False;all([])返回True
(内置)
any(it)
只要 it 中有元素为真值就返回 True,否则返回Fasle;all([])返回Fasle
(内置)
max(it, [key=,] [default=])
返回 it 中值最大的元素,key是排序函数,与 sorted 函数中的一样;如果可迭代的对象为空,返回default
(内置)
min(it, [key=,] [default=])
返回 it 中值最小的元素, key 是排序函数,与sorted 函数中的一样;如果可迭代的对象为空,返回default
functools
reduce(func, it, [initial])
把前两个元素传给 func,然后把计算结果和第三个元素传给func,以此类推,返回最后的结果;如果提供inital,把它当做第一个元素传入
(内置)
sum(it, start=0)
it 中所有元素的中和,如果提供可选的 start,会把它加上(计算浮点数的加法时,可以用math.fsum函数提高精度)
all 和 any 函数的操作演示如 �� 所示
>>> all([1, 2, 3])True>>> all([1, 0, 3])False>>> all([])True>>> any([1, 2, 3])True>>> any([1, 0, 3])True>>> any([0, 0.0])False>>> any([])False>>> g = (n for n in [0, 0.0, 7, 8])>>> any(g)True>>> next(g)8
深入分析iter函数
如前所述,在 Python 中迭代对象 x 时会调用 iter(x)。可是,iter 函数还有一个鲜为人知的用法:传入两个参数,使用常规的函数或任何可调用的对象创建迭代器。这样使用时,第一个参数必须是可调用的对象,用于不断调用(没有参数),产出各个值;第二个值是哨符,这是个标记值,当可调用的对象返回这个值时,触发迭代器抛出 StopIteration 异常,而不产出哨符。
�� 展示如何使用 iter 函数掷骰子,直到掷出 1 点为止:
>>> def d6():... return randint(1, 6)...>>> d6_iter = iter(d6, 1)>>> d6_iter<callable_iterator object at 0x00000000029BE6A0>>>> for roll in d6_iter:... print(roll)...4363
注意,这里的 iter 函数返回一个 callable_iterator 对象。示例中的 for 循环可能运行特别长的时间,不过肯定不会打印 1,因为 1 是哨符。与常规的迭代器一样,这个示例中的 d6_iter 对象一旦耗尽就没用了。如果想重新开始,必须再次调用 iter(...),重新构建迭代器。
另外一个读取文件的 �� 读取文件直到遇到空行或者到达文件末尾为止:
import oswith open('/tmp/bashrc') as f: for line in iter(f.readline, os.linesep): print(line)
- Python 可迭代的对象、迭代器和生成器
- Python 可迭代的对象、迭代器和生成器
- Python可迭代对象,迭代器,生成器的区别
- Python迭代器,可迭代对象,生成器
- Python中可迭代对象、迭代器和生成器相关
- Python的迭代器和生成器
- Python的迭代器和生成器
- Python的迭代器和生成器
- Python的生成器和迭代器
- Python的迭代器和生成器
- python的迭代器和生成器
- python迭代,可迭代对象,生成器,迭代器--
- python迭代器和生成器
- Python 迭代器和生成器
- Python 迭代器和生成器
- Python迭代器和生成器
- Python迭代器和生成器
- python迭代器和生成器
- yolo2
- xml、dtd、SAX解析、DOM解析、DOM4J解析学习(一)
- 最近的维护心得总结(关于安全)
- Windows10安装基本应用程序体会
- android studio自带模拟器Root
- Python 可迭代的对象、迭代器和生成器
- line_profiler安装时出错:Microsoft Visual C++ 14.0 is required
- 单片机模块化一:按键思考
- C51 单片机 读取93C64
- MyBatis Generator之IntrospectedTable
- error:could not open 'E:\Tools\j8k\lib\amd64\jvm.cfg'
- 英语小黑屋总结
- 1277:连续和
- 程序员编程生涯中常会犯的7个错误


