文本处理方法概述
来源:互联网 发布:苹果分区数据恢复 编辑:程序博客网 时间:2024/06/06 20:28
说明:本篇以实践为主,理论部分会尽量给出参考链接
摘要:
1.分词
2.关键词提取
3.主题模型(LDA/TWE)
4.词的两种表现形式(词袋模型和分布式词向量)
5.关于文本的特征工程
6.文本挖掘(文本分类,文本用户画像)
内容:
1.分词
分词是文本处理的第一步,词是语言的最基本单元,在后面的文本挖掘中无论是词袋表示还是词向量形式都是依赖于分词的,所以一个好的分词工具是非常重要的。
这里以python的jieba分词进行讲解分词的基本流程,在讲解之前还是想说一下jieba分词的整个工作流程:
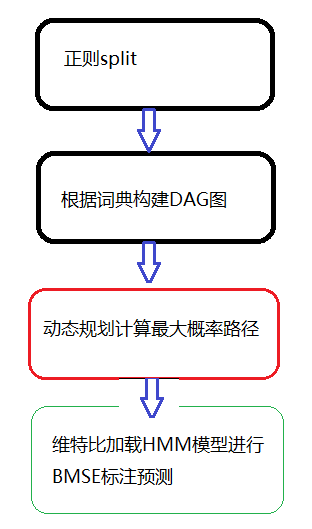
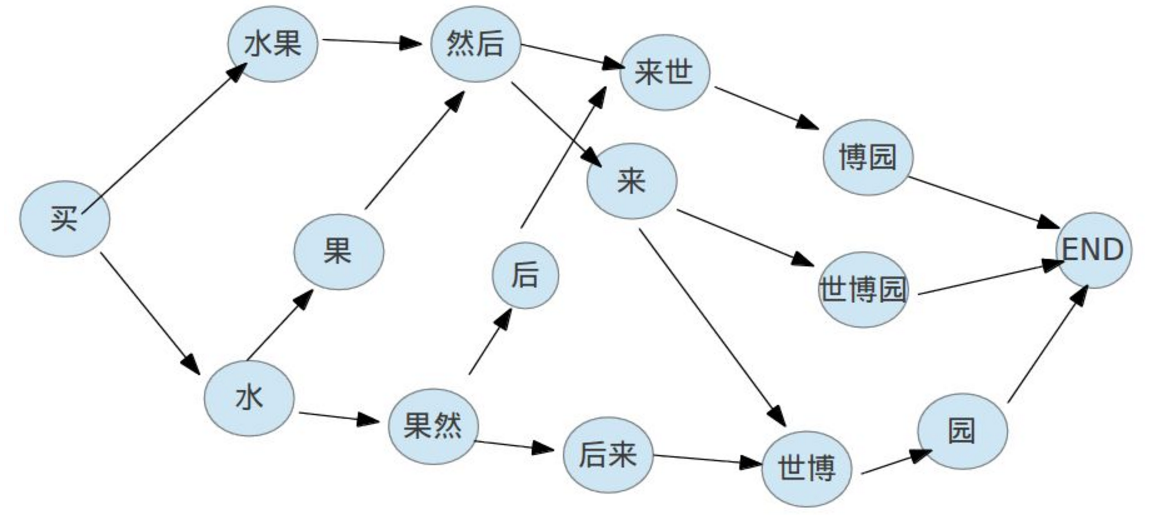
图1是jieba切词函数的4个可能过程,图2是一个根据DAG图计算最大概率路径,具体的代码走读请参考jieba cut源码
讲了这么多,我们还是要回归到实践中去,看下jieba的分词接口
1 # encoding=utf-8 2 import jieba 3 4 seg_list = jieba.cut("我来到北京清华大学", cut_all=True) 5 print("Full Mode: " + "/ ".join(seg_list)) # 全模式 9 10 seg_list = jieba.cut("他来到了网易杭研大厦") # 默认是精确模式11 print(", ".join(seg_list))12 13 seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") # 搜索引擎模式14 print(", ".join(seg_list))
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学【精确模式】: 他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了)【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
其中全模式切词不会发生图1中的第3,4步,也不会发现新词,是一种完全依赖于词典的分词方式
精确模式是会全部计算最大概率路径和新词发现的。
我们都知道分词最重要的是字典,所以jieba也提供了若干方法对词典进行设置:
jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径#词典文件举例:#创新办 3 i#云计算 5#凱特琳 nz#台中add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来
2.关键词提取
文本被分词之后和数据处理一样,也会有如下两个问题:
其一,并不是所有的词都是有用的;其二,一个语料库的词量是非常大的,传统的文本挖掘方法又是基于向量空间模型表示的,所以这会造成数据过于稀疏。
为了解决这两个问题一般会进行停用词过滤和关键字提取,而后者现有基于频率的TF-IDF计算方法和基于图迭代的TextRank的计算方法两种。下面看看这两种方法是怎么工作的

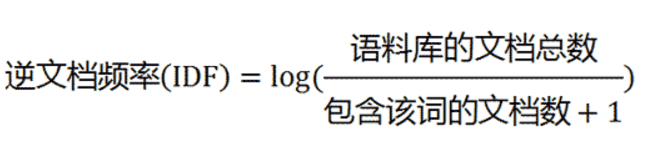
![]()
这里TF表示词在文章中的重要性,因为我们知道一个文章的主题一多次出现;IDF表示词的区分度,因为专业词汇在整个语料库中出现越少,越能关联文章主题。具体来说就是信息熵越低。
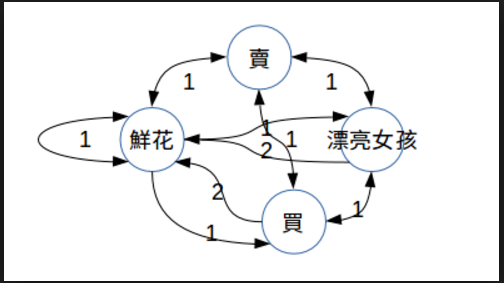
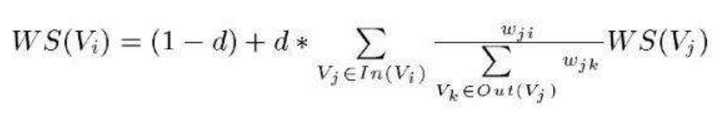
图1是一个文章的上下文词构造的无向加权图(UWG),图2是叶结点的权重迭代公式,其中d是阻尼系数。可见textRank认为一个节点如果入度多且权重大,那么这个节点越重要。
具体理论和代码走读参考: 关键词抽取源码,TextRank: Bringing Order into Texts;下面我们就动手试试吧!
import jieba.analyse#设置停词表路径jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径#默认tfidf提取关键词jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())#sentence 为待提取的文本#topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20#withWeight 为是否一并返回关键词权重值,默认值为 False#allowPOS 仅包括指定词性的词,默认值为空,即不筛选jieba.analyse.TFIDF(idf_path=None) #新建 TFIDF 实例,idf_path 为 IDF 频率文件#textrank提取关键词jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v'))
上面jieba的TFIDF是通过需要指定IDF文件预先指定词的IDF值的,同时textrank中比较重要的参数有一个上下文窗口。jieba通过了这两个方法让我们筛选出前多少个关键词。然而sklearn提供了一种构建文档词矩阵(稀疏矩阵)的方法,可以让我们直接构建文本训练集。
>>> from sklearn.feature_extraction.text import TfidfVectorizer>>> vectorizer = TfidfVectorizer()>>> vectorizer.fit_transform(corpus)... <4x9 sparse matrix of type '<... 'numpy.float64'>' with 19 stored elements in Compressed Sparse ... format>
待续~~~
- 文本处理方法概述
- 常用文本处理方法
- WEKA文本处理方法
- web概述、HTML概述、文本处理、图像、超链接、表格、表单
- java处理文本的方法
- 中文文本处理传统方法
- 文本批量处理方法大全
- 图像处理之预处理方法概述
- WEBBASIC Unit01 Web概述 、 HTML概述 、 文本处理 、 图像和超链接 、 表格 、 表单
- Web概述、HTML概述 、文本处理 、图像和超链接 、表格 、 表单
- java处理大文本及复杂文本替换方法
- java处理大文本及复杂文本替换方法
- 含html标记的文本处理方法
- bat处理替换文本的方法
- Qt处理HTML格式文本的方法
- linux中的文本处理方法集锦
- 【推荐】文本处理的卷积方法
- 对于文本溢出处理的方法
- ajaxfileupload 提示文件另存为
- AutoComplete for jQuery
- 嵌入式处理器-常见问题
- 3324-顺序表应用1:多余元素删除之移位算法
- eclipse中添加tomcat ServerName 无法输入
- 文本处理方法概述
- 深入理解HTTP Session
- 解决Android SDK Manager更新、下载速度慢(1)
- eclipse打开当前文件所在文件夹的方法
- Java提高篇(二六)-----hashCode
- you must restart adb and eclipse的相关解决办法
- CAD转PDF黑白色该如何去转?
- C++中构造函数和析构函数可以抛出异常吗?
- Android studio 修改SDK路径


